OpenAI前CTO王者归来,宣布AI不再需要对话框
本文由 雷峰网 撰写/授权提供,转载请注明原出处。
以下文章来源于:雷峰网
作者:陈嘉欣
编辑:林觉民、马晓宁
0.4 秒能做什么?
眨一次眼大约需要 0.3 秒,而 Thinking Machines Labs 最新发布的 Interaction Model,把 AI 响应延迟压到了 0.4 秒,比 OpenAI 的 GPT-realtime-2.0 快了将近三倍。

但这篇报道真正想说的,不是 0.4 秒这个数字。
如果你以为 Interaction Model 只是一个"速度更快"的语音助手,那就完全搞错了。
真正的突破藏在交互方式里:之前的 AI 模型,包括 GPT-4o 在内,都是"轮流对话"。用户说话时 AI 听不到别的,AI 说话时也不接收新信息。一来一回,像发微信。
Thinking Machines 做的,是把这种模式彻底翻了过来。它的模型可以边听边说边看,你讲话时它能"嗯嗯"回应,你代码写错了它能直接插话,你视频里做了个动作它能实时分析。
这不是 GPT-4o 的升级,这是对 GPT-4o 所在范式的降维打击。
而做这件事的人,正是当年在 OpenAI 主导 GPT-4o 路线的首席技术官 Mira Murati。
Interaction Model 的震撼
5 月 11 日,前 OpenAI CTO Mira Murati 创办的 Thinking Machines Labs 放出了一段 demo 和一个技术博客,立刻点燃了整个 AI 社区。
swyx 的评价格外直白:"彻底碾压了 GDM 和 OpenAI。"Nathan Lambert 称之为"真正与众不同的 demo"。
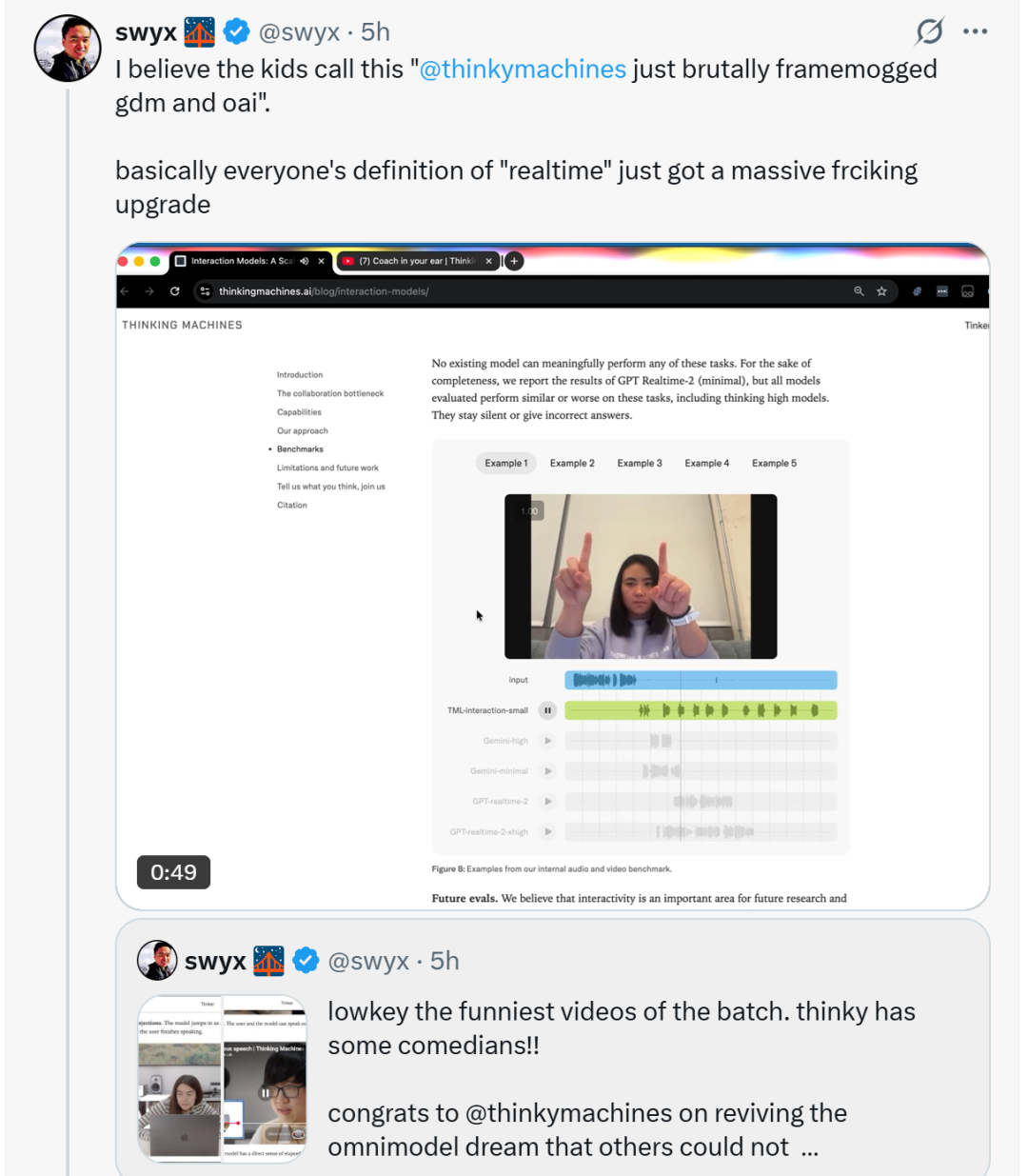
什么让他们这么激动?
技术架构上,Thinking Machines 放弃了标准的"轮流对话"模式,采用全双工架构——同时处理输入和输出,模型可以一边听一边说一边看。具体来说,系统每200毫秒处理一次输入输出片段,所有感知和生成都在同一个 Transformer 内部完成,不需要专门的语音编码器(如 Whisper)做预处理。
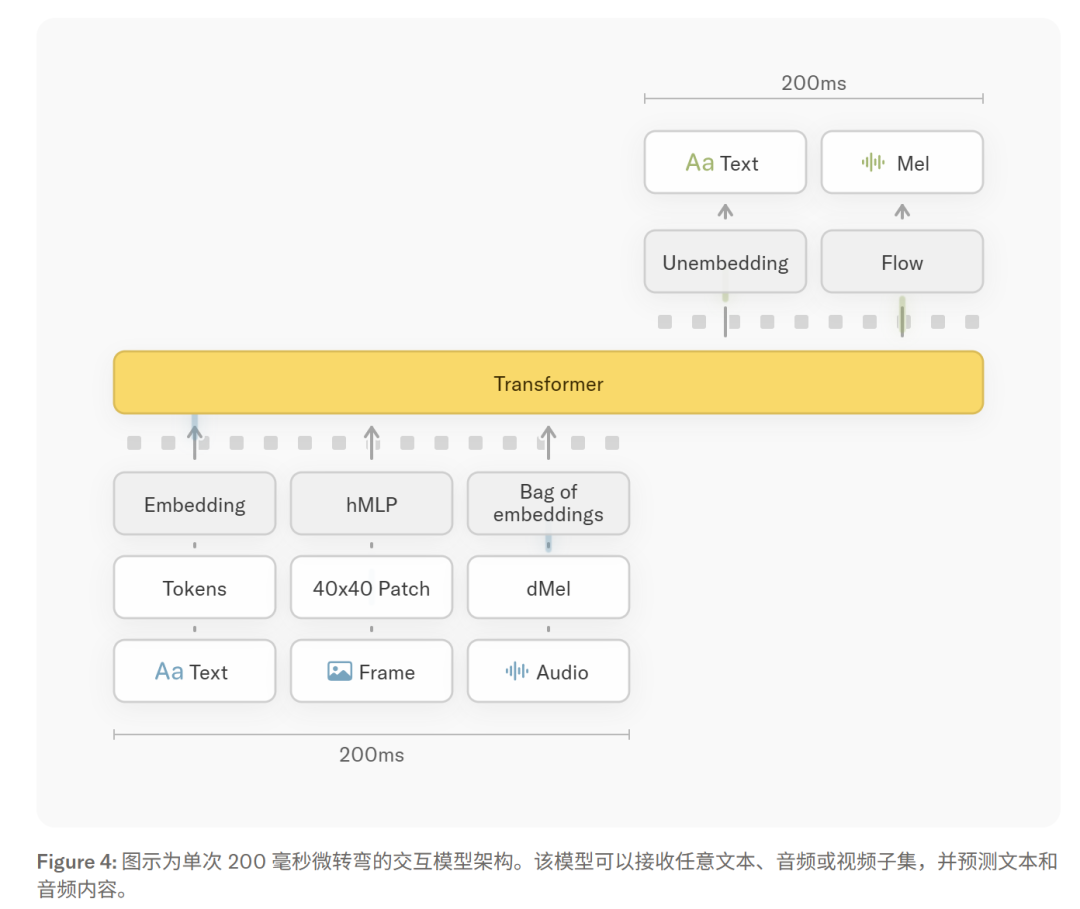
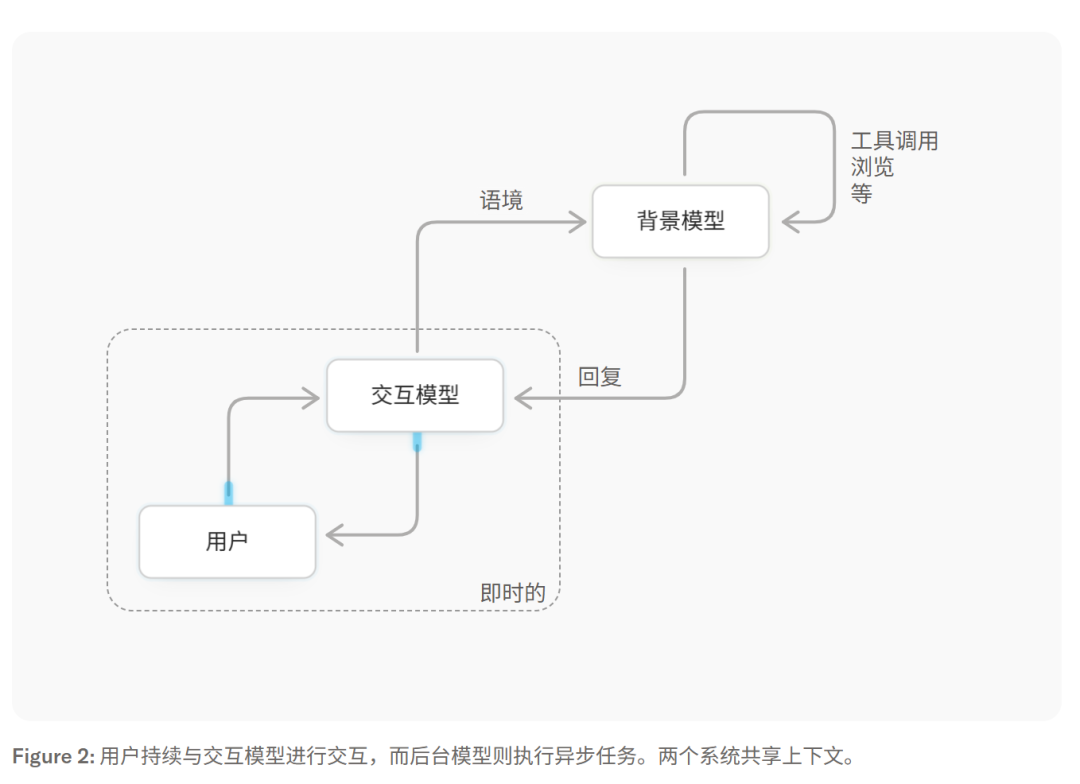
双模型系统也很有意思:一个"前台"Interaction Model(276B 参数 MoE,12B 活跃参数)专门处理实时对话、上下文管理和即时回应;一个"后台"Background Model 异步处理持续推理、联网搜索和复杂工具调用,结果再流式传回前台。
基准测试提供了更硬核的证明——TML-Interaction-Small 在交互质量(FD-bench)上达到 77.8,几乎是 GPT-realtime-2.0(46.8)的两倍。延迟 0.40 秒对1.18秒,快了近三倍。而且在视觉互动测试中,竞争对手面对视频提问"沉默了"或"回答错误",Thinking Machines 的模型却能准确回应。
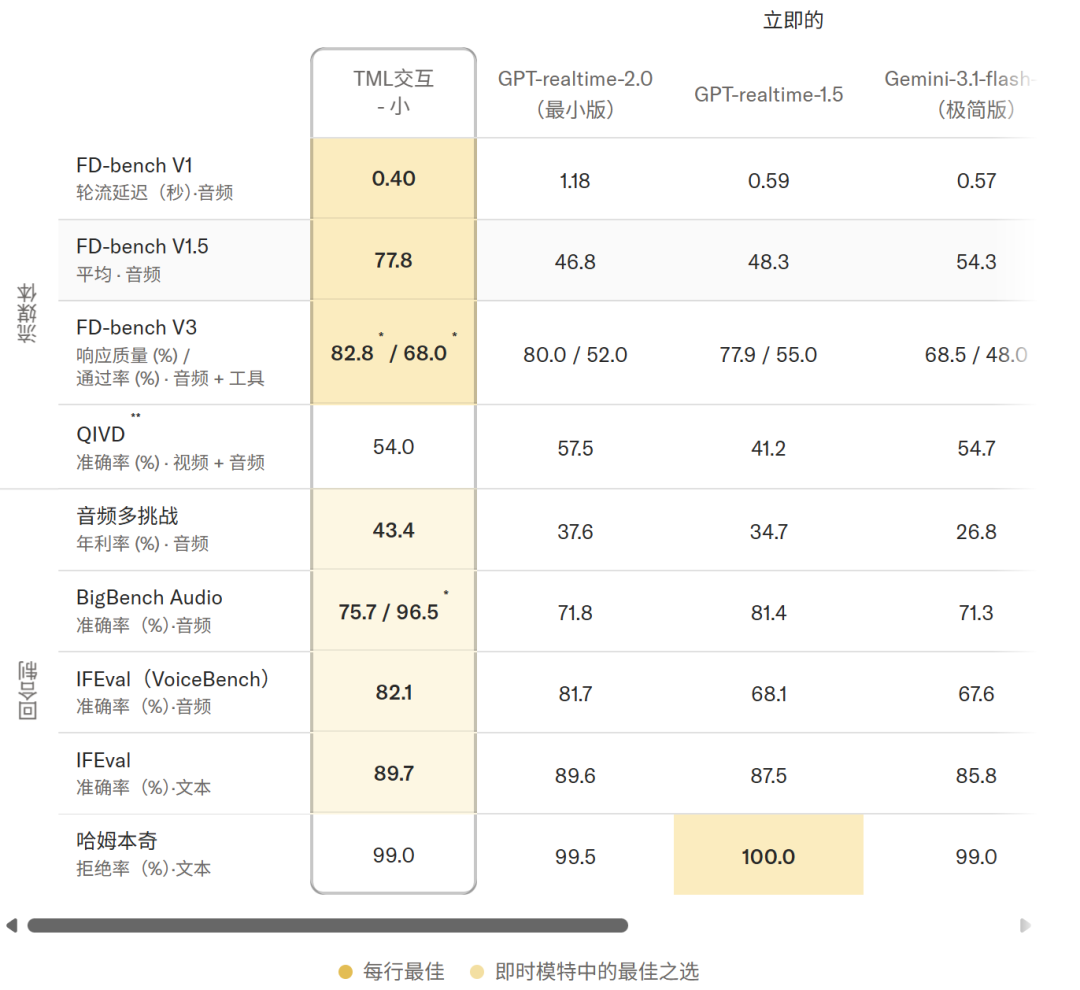
这不是增量改进,是代际差距。
对话框终结者
要理解这个模型为什么重要,得先理解对话框为什么有问题。
从 ChatGPT 到 GPT-4o,人机交互的核心模式一直没有变:用户输入→AI 等待→AI 回复。用户打字时 AI"眼盲耳聋",AI 说话时用户只能等它说完。Thinking Machines 在博客里用了一个绝妙的类比:"就像试图通过电子邮件而不是当面解决关键分歧。"
对话本来应该是流畅的、双向的、实时的。对话框把人类强行塞进了一个"发消息等回复"的框架里。
Interaction Model 要打破的,就是这个框架。
它带来的几个新能力,每一个都在重新定义"什么叫和 AI 对话":
同时听说。你讲话时 AI 能发出"嗯""我看看"等回应——这在人类对话中叫backchanneling,是"我在听"的信号。之前的 AI 做不到,因为它要等你讲完才开始处理。

主动打断。AI 看到你代码里有 Bug,可以直接插话提醒。这在"轮流对话"模式里是不可能的——AI 在生成回复时根本不接受外界输入。
原生时间感知。普通 LLM 没有"时钟"概念——它们只能通过文本提示词知道时间。Interaction Model 天然知道时间流逝,"每 4 分钟提醒我检查温度"这种需求不需要额外编程。
视觉实时互动。AI 可以边看用户动作边回应——你做深蹲它帮你数数,你写代码它帮你盯着错误。
这些能力组合在一起,指向一个结论:对话框是 AI 的第一代 UI。Interaction Model 是第二代。它们的差别,就像命令行和图形界面,像键盘机和触屏机。
Mira 的"出埃及记"
2024 年 9 月,Mira Murati 宣布离开 OpenAI,随后创立了 Thinking Machines Labs。与其他 AI 创业公司不同,Thinking Machines Labs 更像一次"OpenAI 分裂"。
公司创始团队约 30 人,约 2/3 来自 OpenAI,涵盖了从 ChatGPT 创始团队到 GPT-4o 核心开发者的完整班底。
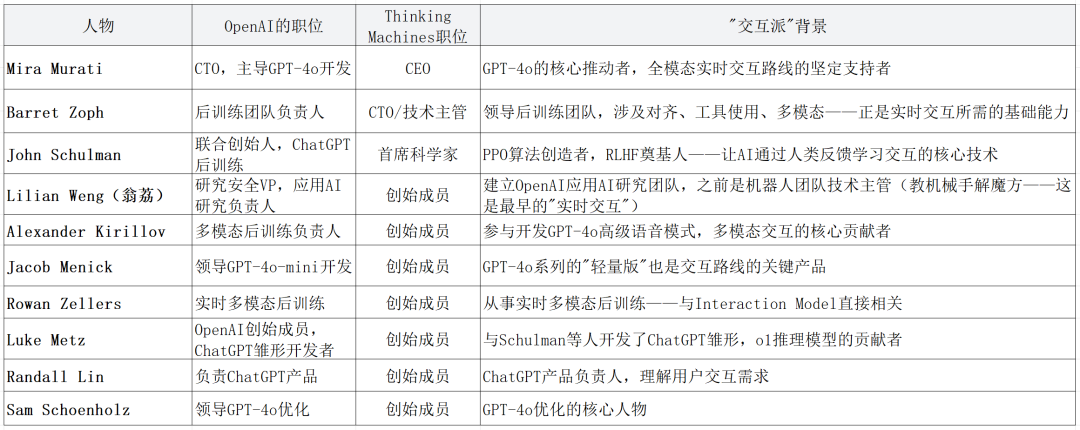
均为 OpenAI 内部"交互派"的核心力量
当时外界对 Mira Murati 离职的猜测很多,但真正的原因其实藏在 OpenAI 的路线之争中。
在 OpenAI 担任 CTO 期间,Murati 一直推动的方向是"全模态实时交互"——这也是 GPT-4o 发布时的核心理念:一个能看、能听、能说、能实时回应的 AI。
但 OpenAI 内部还有另一条路线在崛起,以后来主导 o1 系列的团队为代表——"思维链、大规模推理、慢思考"。不是追求实时,而是追求"想得更久、想得更深"。
两条路线的冲突在 2024 年达到顶点。
上半年为了狙击谷歌的 Google I/O 大会,Mira Murati 带领团队以极快速度推出了 GPT-4o。到了下半年,面对 Claude 3.5 Sonnet 在代码和逻辑上的压制,Sam Altman 和管理层又对 o1 团队施加了极大的压力,要求尽快将“Strawberry”项目产品化。
虽然 Murati 主导了 GPT-4o 的“看听讲”全能,但 9 月份发布的 o1-preview 和 o1-mini 却完全是“退化”的形态,它们不支持语音,不支持多模态,甚至不支持网络搜索。
这种明显的割裂说明,OpenAI 内部无法在短期内将“全模态实时交互”与“慢思考思维链”融合到一个统一架构中,两条路线最终只能各自为战、分道扬镳。
因此,在 o1 模型刚刚发布不到两周后,Murati 毫无征兆地宣布辞任 CTO。有海外媒体统计,2024 年国外科技公司离职 CTO 的平均任期为 3.9 年,但 Mira 在 OpenAI 工作了 6.3 年。
出走的不只她一个人。她带走了一批原 OpenAI 的核心研究人员。公司很快拿到了 a16z 领投的约 20 亿美元融资,估值 120 亿美元。
但创业远比想象中艰难。核心员工大量流失——7 人以上跳槽 Meta,也有人回流 OpenAI。唯一的好消息是 2025 年下半年,PyTorch 创始人 Soumith Chintala 加入担任 CTO,给团队注入了顶级的技术底盘。
如今 Thinking Machines 只有约 130 人。Interaction Model 的发布,是 Murati 出走一年多来拿出的最有力回击——她证明了自己在 OpenAI 时坚持的方向,确实能走通,而且能走得更远。
重新定义人机交互
Thinking Machines 在技术博客里写了一句意味深长的话:"通过使交互成为模型的原生能力,模型的规模增长将同时带来更智能和更有效的协作。"
翻译成人话就是:以前的 AI,越大越聪明,但交互方式还是那个对话框;Thinking Machines 要让 AI 越大越聪明的同时,也越"好聊"。
这是对整个 AI 行业趋势的判断——未来竞争的焦点不在模型规模本身,而在"交互深度"。
如果这个判断是对的,那么最快在未来三年里,以下几个行业将被重新定义:
实时监控。AI 能 7x24 小时盯着视频流,看到安全违规时立刻插话提醒,而不是等巡检人员发现异常再上报。
语音客服。0.4 秒延迟意味着客户几乎感受不到对面是 AI——声音延迟降到人耳感知阈值以下。
工业维护。AI 能在工程师拆设备时实时指导、实时警告、实时查阅手册。
医药研发。原生时间感知让 AI 能跟踪实验进程、提醒关键时间节点、在异常发生时立即介入。
2 千亿参数、12 亿活跃、0.4 秒延迟——这些数字固然令人印象深刻。但 Thinking Machines 真正在赌的是:当对话框被拆掉的那一天,人机交互会被重新定义。而她选择的路径,最终会被证明是正确的那一条。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


OpenAI Codex进入手机,国产“龙虾”们该醒醒了
2026-05-15

千问重构淘宝,阿里“推翻”阿里
2026-05-12

李飞飞创办AI游戏,融资4亿
2026-05-12

深度解析:DeepSeek不差钱,为什么还要融500亿?
2026-05-12

AI转折中的红果
2026-05-13

AI 为什么一定会成为这代人的全新购物入口
2026-05-13

1300亿,快手可灵酝酿“单飞”
2026-05-13

OpenAI前CTO王者归来,宣布AI不再需要对话框
2026-05-14