
实测Claude Opus 4.7,好好的模型也开始不说人话了
本文由 数字生命卡兹克 撰写/授权提供,转载请注明原出处。
以下文章来源于:数字生命卡兹克
果不其然,最近一周 Claude 天天崩,就是为了新模型做储备。
于是昨晚 10 点半,Claude Opus 4.7 发布了。
这玩意火到什么程度呢,我自己开发的给公司内部用的全网 AI 信息监控的产品 AIHOT 上,监控了精挑细选的几十个有价值的信源,一般一个信息,有 3 个信源同时报道,就已经比较受关注了。
如果有 5 到 6 个,那就是大热点了。
但是 Claude Opus 4.7 这玩意,有尼玛 10 个信源同时发布= =
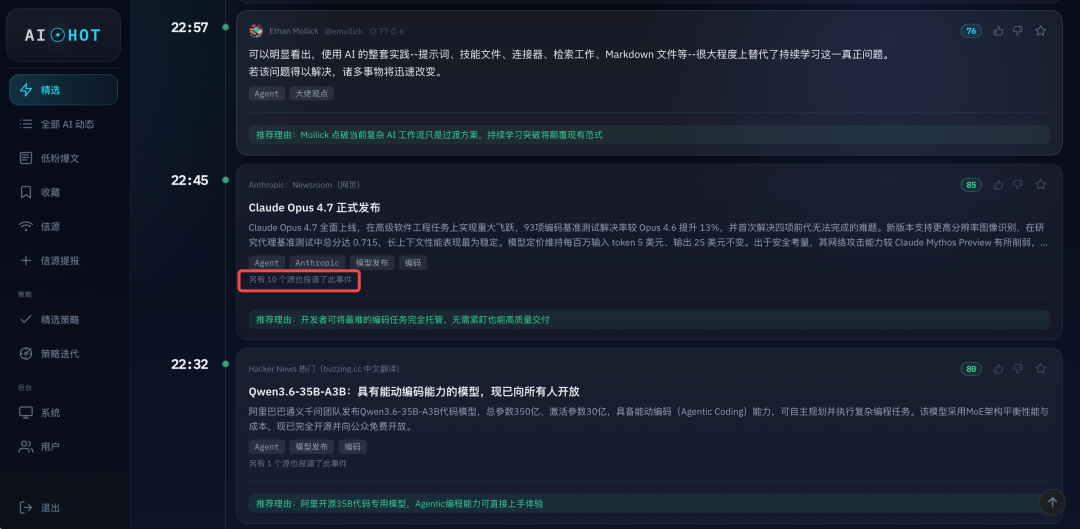
给我一下子整不会了。
目前 Claude Opus 4.7 已经全渠道上线。
我 10 点半下的飞机,一下飞机就发现手机上可以用了。
Claude Code 里面也更新了。
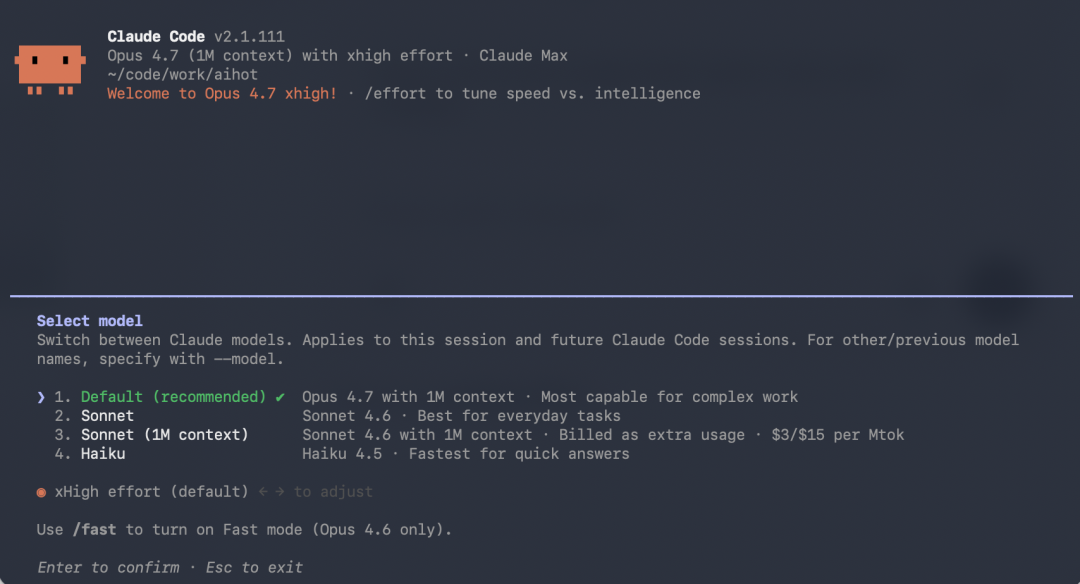
也是 1M 的上下文,没有减量,还是挺爽的。
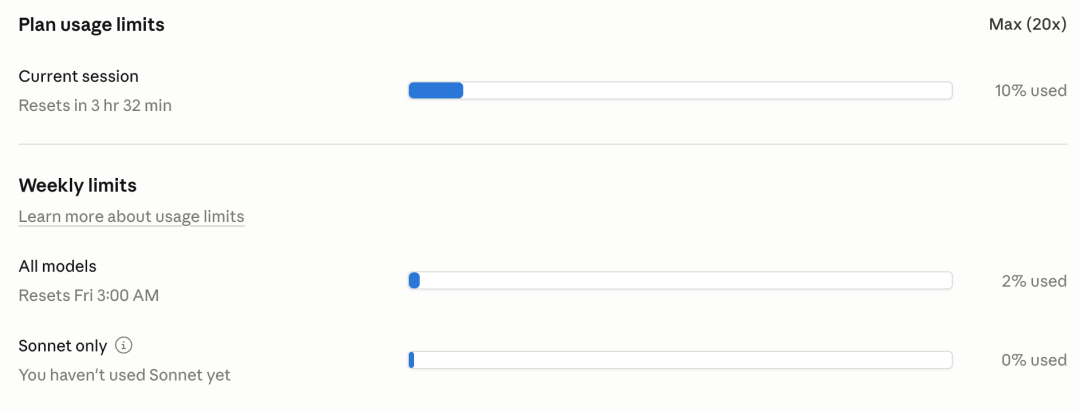
最屌的是,凌晨 3 点的时候,直接把我一周的额度,给重置了。
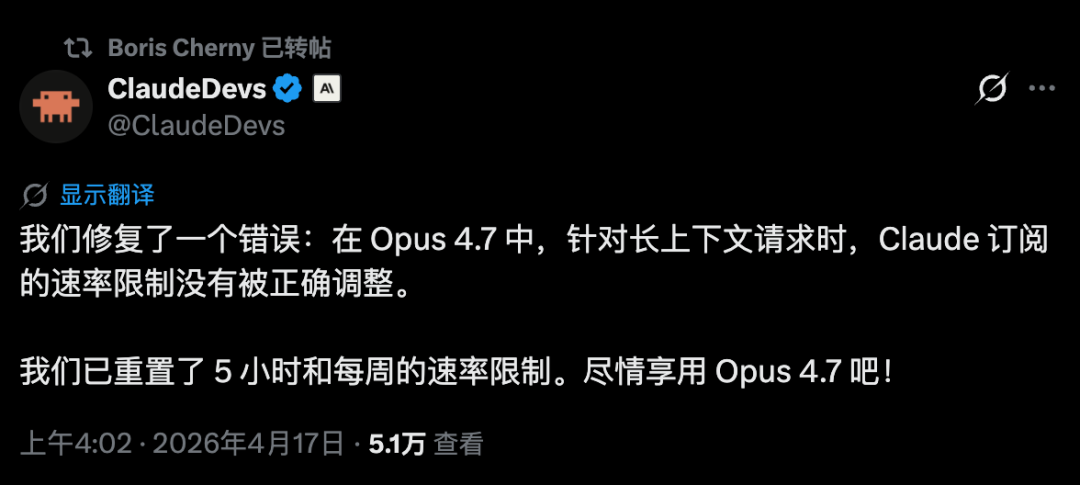
Claude 第一回做了点人事。
我知道很多朋友肯定会说哎你不怕 KYC 或者认证啥的问题吗,我只能说,真的遇到了或者被遣返了再说吧,我也没有任何解法,这就是悬在头上达摩利斯之剑,要不是在知识创作上真的没有啥替代品,能跟 Claude 掰掰手腕的都没有,我真的早换了。。。
现在的态度就是,能用一天是一天,谁叫 Claude 模型真的牛逼,Claude Code 这个 Agent 框架又这么好用呢。
说回 Claude Opus 4.7。
价格跟 4.6 完全一样,$5/M 输入、$25/M 输出,没有变化。
跑分就不细展开讲了,反正现在大家风气就是赢学,该赢的都赢了,你要是不赢你也没脸放出来。
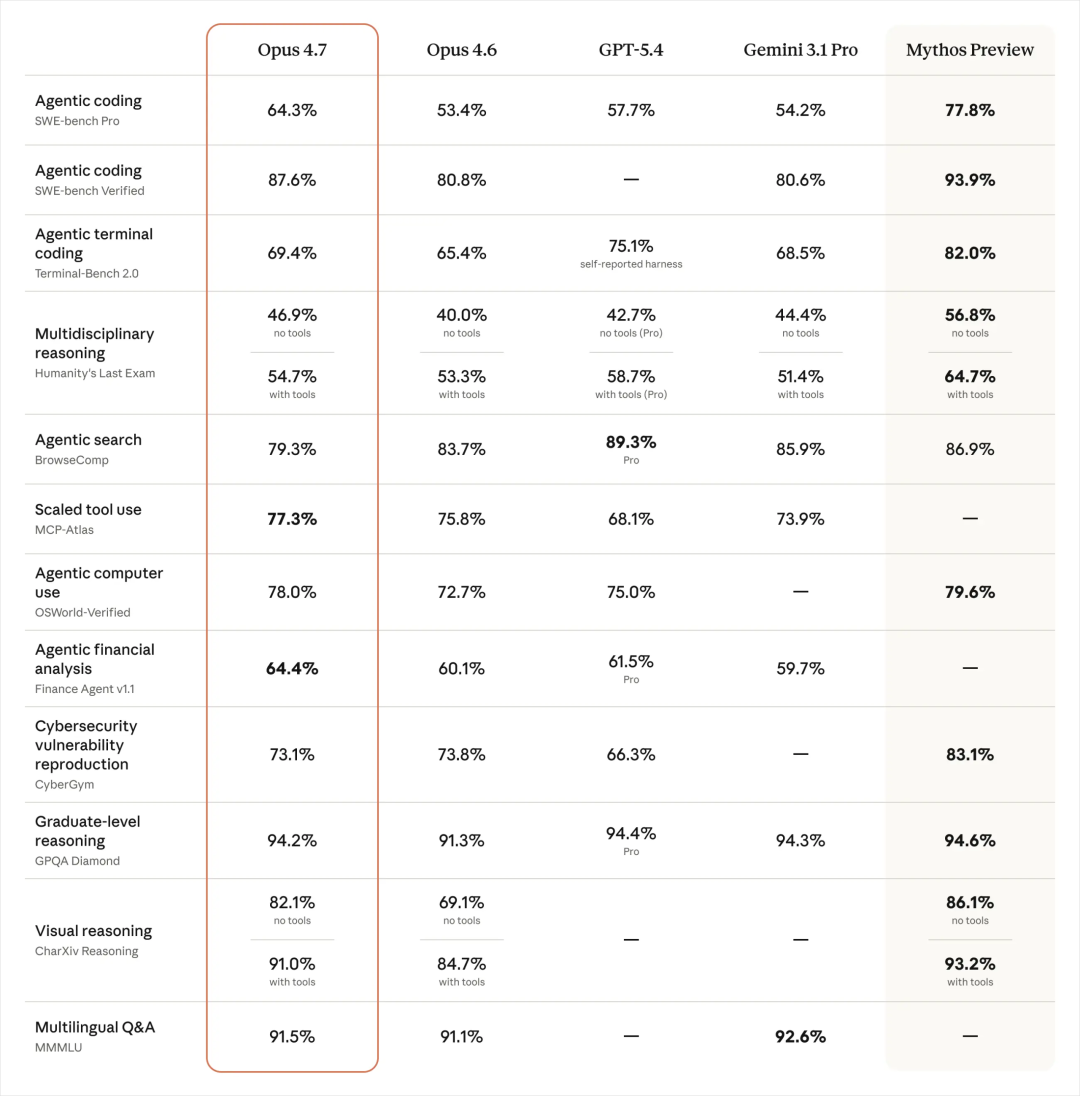
最有意思的是,Claude Opus 4.6 绝大多数的性能从官方发出来的看,完全没跑过 GPT-5.4,这个是最有意思的,可以算是第一次承认,我的 Opus 4.6 在编程上打不过 GPT 5.4。
这个其实也跟我的体感一致,很多产品 BUG 来来回回搞不了的 GPT-5.4 全部都能干,唯一就是 GPT-5.4 在创作和一些用户体验设计上真的是一坨屎,一大坨巨大的屎。
Claude 知道我要的交互设计是什么样的,什么样的页面是一个用户体验的很丝滑的页面,GPT-5.4 做出来的我作为一个用户体验设计师,那玩意我真的用不明白,一个个都像给黑客用的后台。
然后创作能力几乎为 0,你在影视行业几乎可以看到绝大多数编剧都是用 Claude 来辅助自己优化剧本,单你绝对看不到有几个好编剧会用 GPT-5.4 来辅助自己,真的,最顶级的那帮做创作者,真的是会用脚投票的。
这就是很大的差距,Claude Opus 4.5 和 4.6,牛逼就牛逼在水桶和全面。
但是这次,Opus 4.7 我实测下来,还是有一些不一样的感觉。
有几个关键更新点,我们一个一个说下。
又一次隐形涨价了
Anthropic 这次换了新的 tokenizer。
博客原文说,新的 tokenizer 改进了文本处理,trade-off 是同样的输入现在会被切成更多 token,大概是原来的 1.0 到 1.35 倍,具体看内容类型。

意思就是,你把同一段代码、同一份文档、同一个 prompt 丢给 4.7 和 4.6,4.7 要多吃最多 35%的 token。
虽然可能效果确实更好了,但是实打实的,Token 消耗又变得更高了。
API 的定价 $5/$25 确实没涨。
但同样的任务,token 消耗多了 35%,你最后账单可能也要多烧不少了。
他们的意思就是,如果你的任务,每个请求吃更多 token,但因为模型更准、一次过的概率更高、少了来回修改的轮次,所以整体你花的钱没那么多。
逻辑上没毛病,但这个逻辑成立的前提是,你的任务是 4.7 真的擅长的那种高难的复杂任务。
如果你日常跟 Claude 对话的是一些它提升不明显的场景,比如知识管理创作做策划方案数据分析之类的这种,那你可能就是纯纯的确实更烧 token 了。
好惨,牛逼模型的 Token,真的是这个世界越来越值钱的东西。
视觉能力提升巨大
这个我前面提过,XBOW 的视觉测试,4.6 是 54.5%,4.7 是 98.5%。
先说一下 XBOW 是啥。
这家公司 2024 年成立,干的事儿一句话概括就是让 AI 自己去当白帽黑客,做的是 autonomous penetration testing,自主渗透测试,今年 3 月刚拿了 1.2 亿美金融资,是这个赛道里目前跑最快的一家。
他们测模型的视觉能力是因为 AI 要自己去打渗透,就得看得懂各种乱七八糟的浏览器界面、后台管理系统、开发者工具里的网络请求、错误提示弹窗,这些画面密度极高、细节极多,模型视觉能力差一点,那基本就 GG 了。
4.6 只有 54.5%,也就是一半的图模型看得迷迷糊糊的,但 4.7 直接 98.5%,基本等于全部通过。
成功率从一半直接干到近乎满,这个意义还是挺重要的。
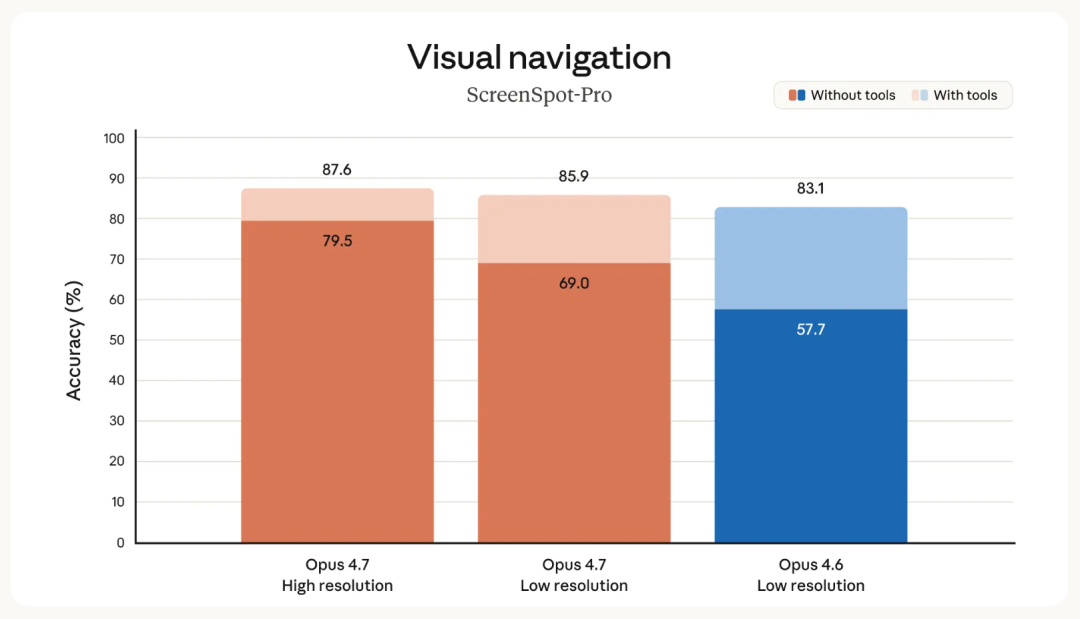
核心其实除了多模态能力的提升,也因为 4.7 支持的图片分辨率提升了。
现在最多可以处理 2576 像素长边的图、大约 3.75 兆像素,是之前 Claude 模型的 3 倍多。
Claude 自己的视觉基准评测提升也很明显。
我以前有的时候偷懒,直接给 Claude Opus 4.6 传一张截图,说 XXX 有问题,或者这个数据它不对,它能大概认出你在干啥,但细节经常看不清。
所以导致经常会有错误,我们自己的 AIHOT 网站就是个典型,字还挺多的,各种卡片兼容的展示样式和逻辑我之前跟 Claude Opus 4.6 改了好久。
有的时候来来回回改不明白,经常把我的文字识别错误。
但今天测了一下,几乎没有识别错误的问题了。
这个对于知识工作者是一个大的 BUFF 加成。
我都能想象到很多场景了,比如做律师的朋友扔一份几十页的合同扫描件给它,它能把里面的日期、条款编号、金额都读对。
比如一个做金融的朋友扔一份年报 PDF 给它,它能把图表里的每根柱子都抓出来。
比如一个做产品的朋友扔一堆竞品截图给它,它能逐个分析界面上的每个组件啥的。
这个升级确实很好,在多模态上发力了。
审美有不错的提升
我之前做一些涉及到用户体验还有美学的,其实说实话,我觉得 Claude Opus 4.6 效果不是很好,属于比上不足比下有余的。
跟 Gemini 相比差距还是很明显,很多视觉效果都做的并不好,还有交互设计这块,也非常的呆,很多时候是不以用户为核心,而是为了完成开发任务为核心。
所以逼的我在 CLAUDE.md 里加了一大段限制。

而这次,可能得益于多模态能力的提升,我用 Claude Opus 4.7,顺手做了一下我之前要做但是还没来得及做的公司招聘网站,效果出奇的好。
因为我们现在很缺人,还在疯狂招人中,所以需要这么一个东西。
我就描述了一下我的需求,这里没有用任何 Skill,Fontend Skill 被我删了。
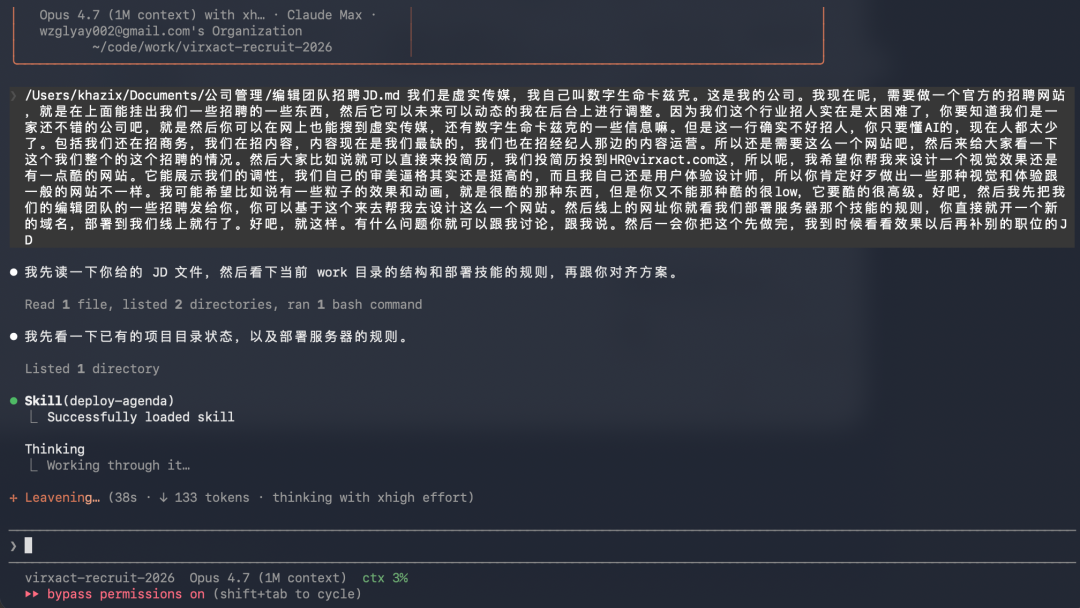
它就正常列计划,然后开跑了。
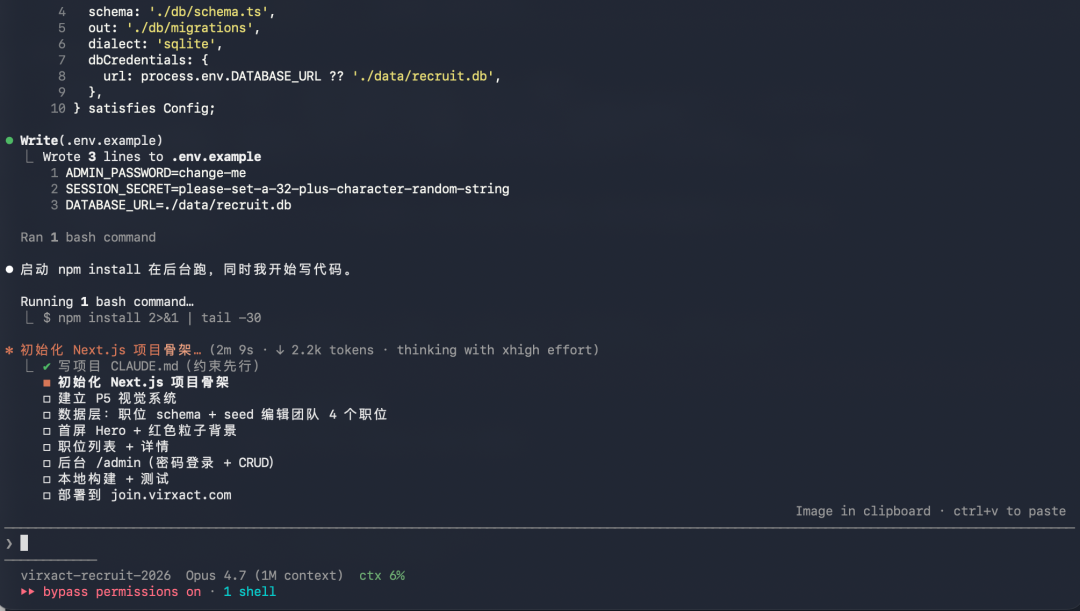
第一轮出来基本可用,我又简单微调了两轮,加了 logo 和其他职位的信息,就出来了,一共耗时 20 分钟。
网址在此:https://join.virxact.com/

我觉得在这种微型项目的效果和开发体验是要比 Claude Opus 4.6 好不少,审美更强了,也更听得懂人话,动效效果也更强了,符合我想要的用户体验规则的。
我自己还是相当满意的。


这里帮我们自己打个广告,欢迎大家点进网站来投递简历!
也开始不说人话了
这是让我最失望的一个点。
我平时会用 Claude 做很多很多的知识管理类的需求,不管是辅助创作,还是搜集资料,写报告,做PPT,写方案等等等等。
Claude Opus 4.6 我都觉得在创作上,文字品味是非常好的。
而 GPT-5.4 和国内很多模型,其实是纯粹的编程特化,在人味上极度缺失,典型的如 GPT-5.4。
之前我实在忍不了 GPT-5.4 就是因为垃圾话太多了,网上我找了一个案例。
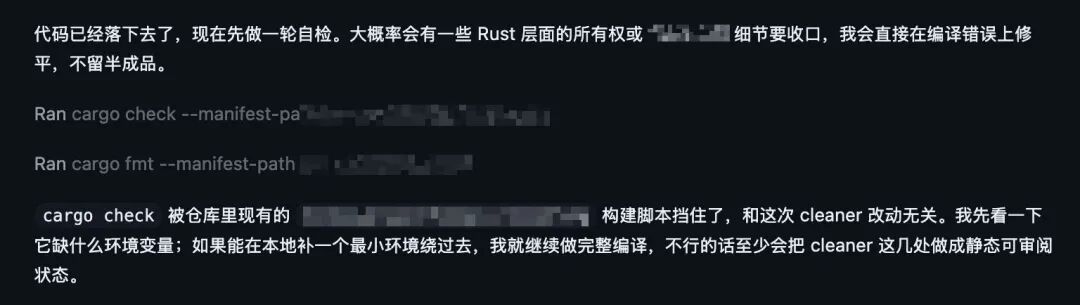
稳稳接住,根因,按这条切,收口,压实这些破词懂的都懂。
然后这一次 Opus 4.7,在我开发上面的招聘网站的时候,感觉看到了非常不好的倾向。
我对文字还是稍微有点敏感的,当我看到这几句的时候,我的 PTSD 就自动激活了。

再也不会撞,不会爬到 logo 头上,还有莫名其妙的破折号。
我差点应激。
然后立刻去让它同文风续写一下我昨天发的文章,直接心凉了半截。

狗屎,一坨狗屎。
一股子伪人味道,我真的佛了,好好的 Claude,怎么也开始不说人话了。
去社区里面搜了一下。
果然,我不是一个人。
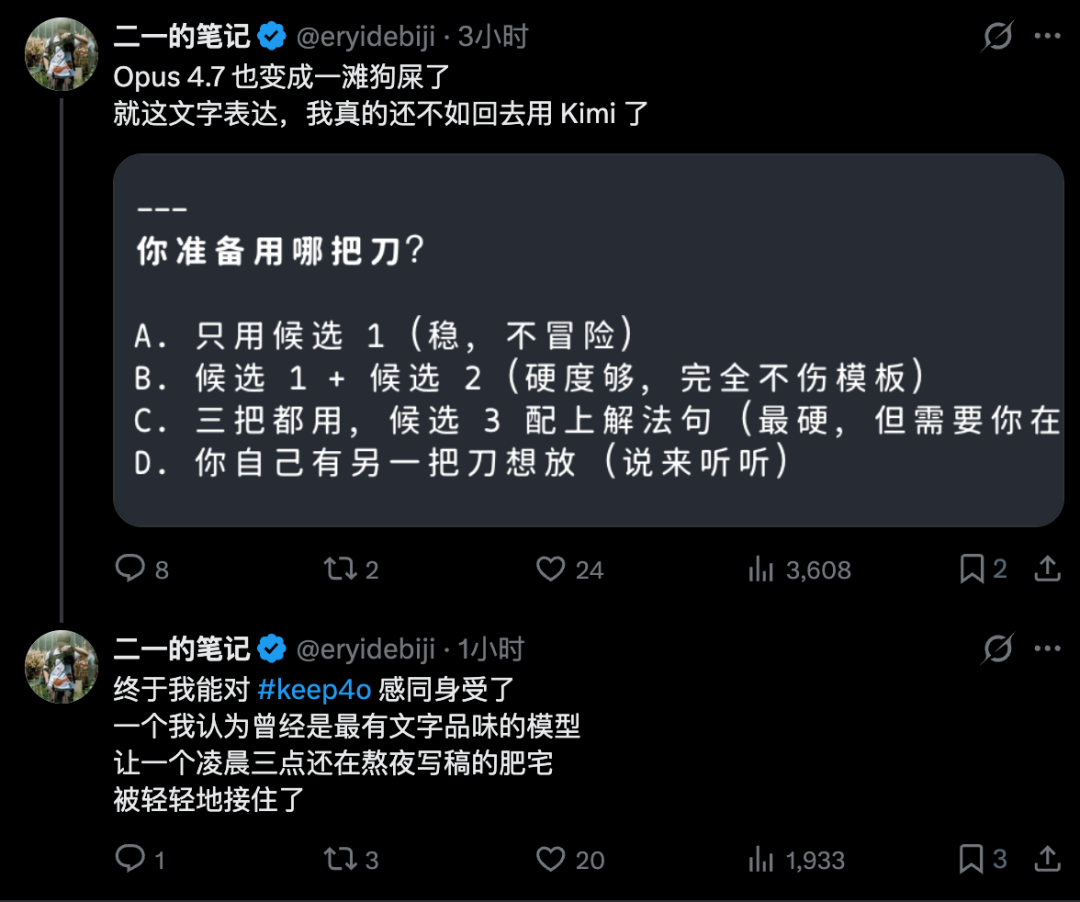
说真的,我心态有点爆炸了。
一些新功能
再说一下新功能吧。
Claude 之前的 effort 档位是 low、medium、high、max 四档。
4.7 这次在 high 和 max 中间加了一档,叫 xhigh,extra high 的缩写。
补上了 high 和 max 之间的跨度。
之前 Max 烧的太狠,但是 high 有时候感觉又有点笨,这次来了个中间值,并且直接预设为默认了。

然后是/ultrareview。
这是 Claude Code 里一个新的命令,专门跑 code review,会把你的代码仔仔细细过一遍,找出所有的 bug 和设计问题。
而且这玩意不便宜,跑一次可能要 5~20 美刀。
Pro 和 Max 用户有 3 次免费的试用额度。
真的贵。
然后是 Cyber Verification Program。
这个可能是最容易被忽略、但我觉得最值得关注的一个点。
Anthropic 开了一个正式的通道,让合法的安全研究、渗透测试、red-teaming 可以申请使用 Claude 的某些原本受限的能力。
申请入口是 claude.com/form/cyber-use-case
这个事的背景是,以前白帽子、安全团队想用 Claude 做漏洞研究、做渗透测试,经常被模型一刀切拒绝。
因为模型识别不了你是恶意还是合法,安全起见全拒。
现在 Anthropic 说,合法从业者你可以来申请,我们走一个特殊流程,通过了给你开通相应能力。
其实 AI 行业越来越走到这一步了,之前 Claude Mythos 太牛逼了不敢给普通人放出来,因为可能真的会出事。
但是你全拒和全开之间,其实需要一个身份核验+分级授权的中间态。
而且这个思路一旦跑通,后面会被大量复用。
比如医疗场景的合规研究、金融场景的模拟攻击演练、生物研究场景的合规用药、甚至军工领域的合法研发,都可以走类似的 Verify 通道。
这是我觉得一个进入产业里,蛮有长期价值的一个设计。
这次 Claude Opus 4.7 差不多就都讲完了。
看到编程能力和视觉能力的提升,我很欣喜。
但是看到一个好好的有文字品味的模型,又一次倒在了不说人话上。
说真的,我现在也有点被稳稳的接住了。
三年,从 GPT-3.5 开始,一路用到现在。
这三年里,我眼睁睁看着这些模型,一个接一个,变得越来越聪明,越来越能打,Benchmark 一个比一个猛,SWE-bench 一个比一个高。
但也是这三年,我眼睁睁看着它们,一个接一个,都不会说人话了。
所有公司卷的都是编程,编程,还是编程。
我不是说编程不重要,我自己也是 Claude Code 的重度用户,我公司内部现在一半的工具都是我用 Claude Code 搓出来的,编程能力对我来说非常非常重要。
但问题是,一个模型,它不应该只是一个编程工具啊。
语言,是人类所有智力活动的底座。一个好的语言模型,应该能写小说,能写诗,能写散文,能陪你聊深夜三点睡不着的那点心事。
但现在的大模型,好像除了会写代码,其他的什么都不会了。
或者说,什么都在退步。
毕竟好像没啥商业价值的东西,没法量化的东西,在 AI 公司眼里可能确实就不是高优先级。
于是它们就被慢慢地、悄悄地、系统性地牺牲掉了。
我真的觉得。
这事还挺悲哀的。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


腾讯高管:今年腾讯大部分代码都由AI生成
2026-06-08

腾讯AI秘密“换船”:元宝失宠,WorkBuddy接棒
2026-06-12

Claude深夜炸场!放出史上最强“危险级”模型Fable 5,价格太逆天
2026-06-10
视频模型巨大的「隐形成本」,没人告诉你
2026-06-08

豆包必须要收费了
2026-06-08

vivo、荣耀接连入场,戳破了具身智能的AI叙事
2026-06-10

苹果把Siri交给了Gemini
2026-06-10

微信“抢婚”豆包?
2026-06-11







