人类的考试,考验不了AI了
本文由 DoNews 撰写/授权提供,转载请注明原出处。
以下文章来源于:DoNews
作者:李信马
题图:豆包AI
2017 年 5 月,当时世界围棋排名第一的柯洁惨败于 AlphaGo,在机器是否会比人类更聪明这个事关全人类尊严的问题上,我们第一次有了一个确定性的答案。
一年前尚且能赢一局的李世石,成为人类棋手在AI面前最后的夕阳。
不过,人类善于寻找理由,比如将智力转换为更复杂且难以解释的“智慧”,那就显得我们还在赢,还有是更“高级的”赢法。而且作为在智慧这条路径上的先行者,人类可以既做选手又做裁判,给出一套套的测试标准,美其名曰测试 AI,AI 超过了人类水平,那是人类推动的科技进步,AI 没有超过人类,那人类再次赢赢赢。
但“青出于蓝而胜于蓝”这件事,虽然人类希望 AI 快点做到,可当快到像迎面而来的一阵冰雹猛地砸到脸上时,绝大多数人还是会不适应到懵逼。
最初,我们轻松地用游戏来测试 AI,现在,人类能参与地最难的考试,也即将无法用来考验 AI 了。
在一个周前,马斯克发布了最新版的 Grok-4,这款大模型,用老马的话来说,“比所有领域的博士都聪明”。
而其在各项考试中的成绩,可以说是怪物般的存在:
我们比较熟悉的 SAT 和 GRE 考试几乎满分,不太熟悉但更难的考试,GPQA(研究生水平问答)准确率为 88.9%,AIME25(美国数学邀请赛)准确率为 100%,USAMO25(美国数学奥林匹克竞赛)准确率为 61.9%。
最引人注目的是“人类最后的考试”(Humanity’s Last Exam,简称“HLM”),听这个名字,大家就能知道它代表的意思。
这个考试是由 Scale AI 和 Center for AI Safety(CAIS)发布的,包含 3000 个高难度的问题,涉及超过 100 个学科,题目来自数百位不同领域的专家,可以说,这套试题涵盖了人类智力任务中最具挑战性的部分,足以用来衡量 AI 是否具备“类人智能”。
其中题目分为两类,一类是简答题(Exact-Match Questions),需要输出一个完全匹配的字符串作为答案,另一类是选择题(Multiple-Choice Questions),需要从五个或更多选项中选择一个正确答案。
不过,前者占到了 80%,而且数学相关的题目占到了全部问题的 42%,所以不要指望碰运气能刷出高分。

来自题库的题目之一,感受一下无知的痛苦吧
据说,以普通人的水平,大概能答对5%的题目,而当时的大模型也纷纷折戟,没有一个能超过 10%。你问人类最多能打多少分?这不重要,反正题目也是人类出的。
但 Grok-4 的出现,却让 AI 通过“人类最后的考试”的时间大大缩短了,达到了 50.7% 的准确率,成为首个突破 50% 的大模型。
这个分数,高的惊人,但因为考试的难度过大,距离大家的生活又太远,所以很难直观的说明有多难得,不过好在,后来笔者找到了一个差不多所有中国人都能理解的参考系。
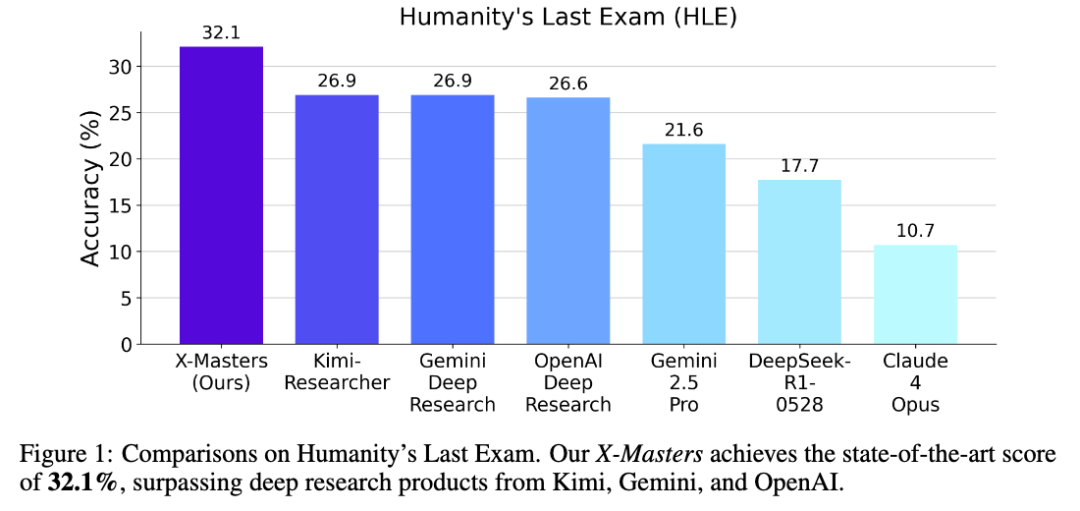
在 Grok-4 发布的差不多同一时间,上海交大联合深势科技团队,使用 DeepSeek-R1-0528 作为驱动智能体的推理模型,在“人类最后的考试”上拿下了 32.1% 的新纪录,可以说代表着国内大模型的最高水平。(虽然立刻就被赶超了)
而大概一两周之前,国内的大模型正在集体测试另一套“国民考试”——高考试题。
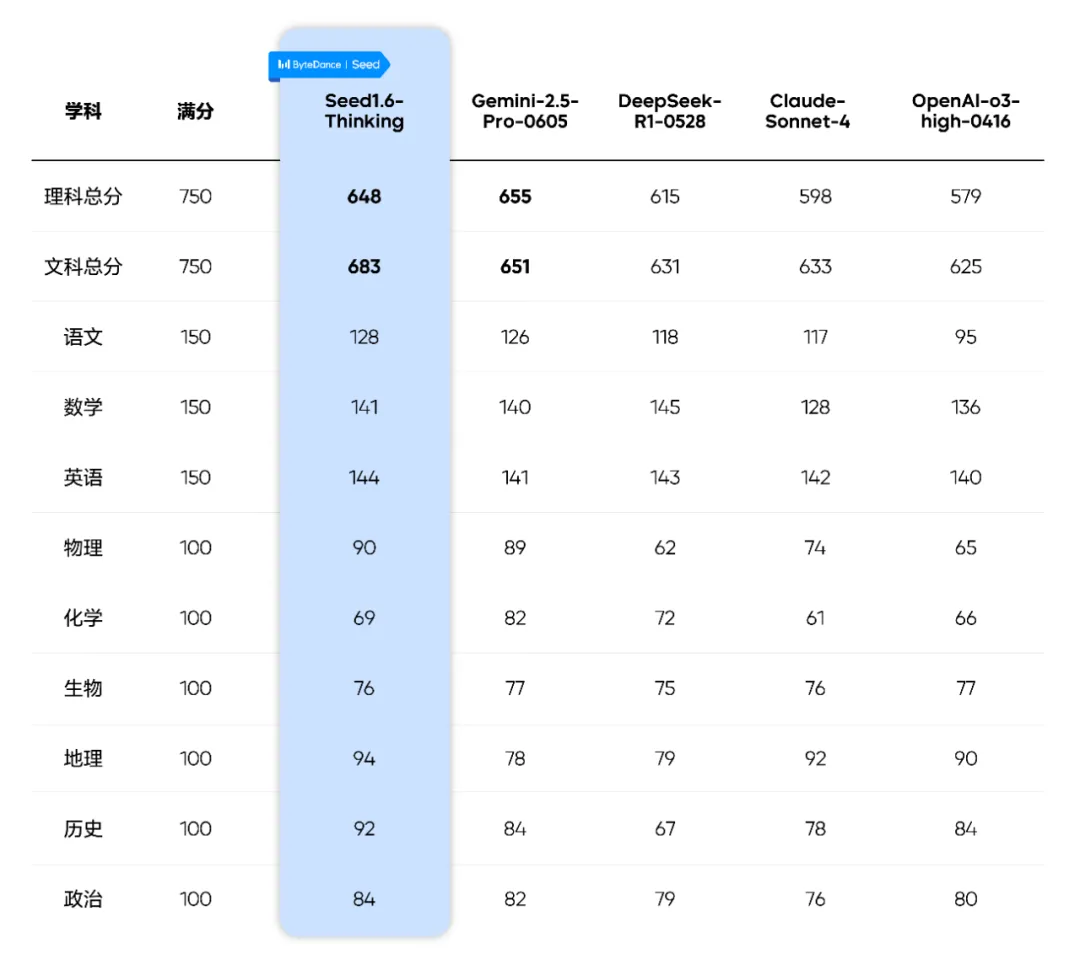
比如,字节跳动 Seed 团队就用最新推出的通用模型 Seed1.6 对 2025 年山东卷高考真题(题目源自网络)进行测试,语数外采用新课标全国Ⅰ卷,其余科目为山东省自主命题,满分 750 分,并找来了两位来自重点高中、有联考判卷经验的高中老师进行匿名评估和多轮质检。
最终,Seed1.6 在理科和文科分别考取了 648 和 683 的高分,这个分数在山东省分别是 4005 名和 211 名,理科成绩可以冲击武汉大学,稳妥些也能去华中科技大学;而文科成绩,更是有把握冲击清北,保底也能去上海交大和复旦大学。作为参照的 DeepSeek-R1-0528 ,理科和文科分别考取了 615 和 631,上到 985(个别名校除外)下到 211 也是选择多多。(排名信息及志愿推荐来源:中国教育在线)
也有媒体用国产大模型测试了下高考辽宁卷,显示腾讯元宝(混元 T1)文科卷的分数还要更胜一筹,笔者查询了下,其文科成绩排到了全省第 11 名,属于是清北招生办争相打电话,理科成绩就逊色多了,但上个 985 还是没问题的。至于 DeepSeek,大致是冲击 985 保底 211 的水平。

所以,以高考试卷为标准,那么 DeepSeek 和豆包、混元间几十分的差距,是考上 985 和考上清北的差距;而以 HLM 为标准,DeepSeek 和 Grok-4 差了接近 40% 的分值……
“比所有领域的博士都聪明”的真假还不确定,但在刚刚高考完的这一届高三考生中,文科成绩能超过 AI 的真的不多了。也许下一年,大模型们的高考成绩,就要彻底吊打人类考生了,能考上清北的人被称为天才,但天才努力跨过的门槛,只是 AI 的保底志愿。
但我更倾向于认为,就像人们对 AI 在围棋领域对人类的碾压再无兴趣一般,高考,还有其他人类能参与的考试,包括“人类最后的考试”,最终都会呈现 AI 一边倒的绝对优势,以至于让人习以为常。
可能到时候,人类会制定新的考试,但不再考虑将人类和 AI 进行对比,而是 AI 之间纯粹的竞赛;也可能将不存在这样的考试或者变得很少,人们将更关注 AI 的应用落地和性价比,毕竟人类也好,AI 也好,考试都只是过程之一,创造出价值才是最终的目的和结果。
不过到那时,人类在智慧上的优越感,又要靠什么来维持呢?


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


微信撞上支付宝
2026-06-22

AI 巨头的「Token 补贴大战」,快打完了吗?
2026-06-22

剪映和即梦,争抢 Seedance
2026-06-22

1万亿智谱,谁赚走了最多的钱?
2026-06-23

AI支付宝上桌,微信慌了吗?
2026-06-23

3年5亿MAU,Meta悄悄养出一个社交爆款
2026-06-23

在数十亿个Agent运行之前,亚马逊先让Agent学会了管库存和招人
2026-06-24

火山引擎就是要制造一个一个又一个 Seedance 2.0 时刻
2026-06-24