大模型热度退潮,真正的技术创新者开始被「看见」
本文由 AI科技评论 撰写/授权提供,转载请注明原出处。
以下文章来源于:AI科技评论
作者:郭海惟
编辑:陈彩娴
“过去两年中国的大模型投资并不是投技术,而是套着投技术的壳投商业模式。硅谷的投资人投 OpenAI 是投技术。”一位投资人对 AI 科技评论表示。
商业模式驱动的投资核心是可预见的数字增长,而技术投资则相反:即便没有明朗的商业模式,只要技术创新仍在不断攀登新的高度,就足以押注。DeepSeek 扬名前,追随 OpenAI 成为大模型的吸金石;DeepSeek 出圈后,“独立创新”取代“步步跟随”、成为大模型的新主流。
在这一变化下,技术创新与投资开始返璞归真、回归本质。一个直接的变化是融资,相比过去两年的融资节奏,今年大模型的吸金热度明显下降。但截至 2025 年 6 月,国内仍有两家大模型公司官宣了新一轮的融资消息,一家是处于大模型第一梯队的智谱 AI,另一家便是专注端侧 AI 的面壁智能。
裸泳的人退出竞争,装备齐全的人正式登场。例如,DeepSeek 在云上千亿级大模型的独辟蹊径,成为了百模大战的终结者,让所有比拼基础模型的公司都不得不开始直面真正的技术创新。这说明大模型的吸金热度虽然在下降,行业的发展却正在朝着一个更健康的趋势前进。
与 DeepSeek 一样,在大模型基础技术上持续创新的团队也渐渐浮出水面,得到越来越多的关注。今年 5 月官宣数亿元融资的面壁智能,不久前在智源大会上发布了其同时在端侧上进行推理与架构创新的新一代“小钢炮 4.0”,就向市场传递了一个信号:
AGI 的落地正在朝着云端两侧发展,并逐渐形成 DeepSeek 与面壁智能花开两朵、各表一枝的局面。如果说 DeepSeek 的开源大模型是云上应用的福音,那么面壁智能的 MiniCPM “小钢炮”系列便是终端智能的触手。
随着 AGI 基础技术话题的不断收敛,从数据、学习、架构与推理上进行创新已成为各家的主要比拼路径,而在架构与推理上同时进行创新的团队却不多,DeepSeek 与面壁是国内的极少数,且一个在云、一个在端,又刚好错开正面竞争、共同弥补了当前国产大模型落地的市场供给版图。
小钢炮证明了,在 DeepSeek 射程以外,AGI 发展依然存在丰富的可能性。但更值得关注的或许是这样一个故事:一个持续迭代的端侧模型,是如何始终从 AGI 的终局思考每一项技术创新的意义,不重复造轮子、并不断为领域做出贡献的。
只有真正向创新看齐的团队,才勇于回答一个简单却宏大的问题:AGI 的终局真正需要什么?
AGI 四象限的“半壁江山”
从 2020 年 GPT-3 到 2022 年底的 ChatGPT,再到大模型彻底狂飙两年后的今天,我们可以看到,现阶段 AGI 技术的创新维度已经大致收敛至四个大的板块:
数据、学习、推理与架构。
在 Scaling Law 式微、范式创新乏力的今天,前两者正在变得“公平”、几乎可以为所有团队所掌握。一方面,数据维度的标准化包括大规模网络爬取、多模态数据融合、高质量数据筛选等技术已相对成熟,而开源数据集的快速发展,让数据集获取规模不断向着“穷尽”互联网数据规模的天花板靠拢。另一方面,训练大模型、提高模型学习能力的基础方法论已经变得更加透明,不再是高阁秘密。
相比之下,推理和架构由于起步较晚、难度更高,几乎成为了模型智能增长的“下半场”,是各个团队之间拉开差距的核心分水岭。与此同时,二者的性能又是相伴相生的。
Transformer 架构仍是主流,但业内一直讨论其不能支撑大家所想象中的终局 AGI 模型,因此架构的创新至关重要。以今年以来备受行业关注的稀疏注意力架构为例,早在 2020 年,包括 OpenAI 在内的许多研究机构就提出了“稀疏注意力”机制,以此来弥补 Transformer 架构的缺陷,但相关研究一直不顺畅,原因是动态稀疏注意力的底层算子要求高,速度很难提升。
对于算力条件有限的终端硬件来说,如果不从架构上进行改进,硬件层面便难以对注意力机制进行加速,稀疏注意力便很难真正落地实现。
过去半年内,国内大模型团队围绕架构创新也进行了不断的创新。例如,DeepSeek、月之暗面分别提出了 NSA 和MoBA 架构的块状稀疏注意力方案,MiniMax 提出了 Lightning Attention 的线性稀疏注意力方案等。其本质都是通过架构创新,从而最大化加速底层架构对 token 的计算能力,从而达到模型软硬结合的最优解。
不过这些创新都是跑在云上的千亿级大模型成功创新,其在端侧场景则未必适用。
以 NSA 架构为例,其整个架构主要服务云端大模型场景,对不同算力平台的兼容性有限。其采用的分层动态模式,在端侧灵活性稍逊的计算场景中,也显得优势不足。在实测中,NSA 架构虽然在长文本处理中有很好的性能表现,但在短文本方面却会显得相对迟钝。
而在 MoBA 架构中,大量的专家模块的通信要求,在端侧场景中会带来较高的块间通信开销。尤其在端侧内存有限的情况下,会出现非连续的内存访问,进一步降低模型的运行效率。
而此次面壁发布的 MiniCPM 4.0 首次集成了 InfLLM v2 稀疏注意力结构,便是针对端侧场景做了大量的针对性优化,从而大幅提升了其在端侧的效率能力。
首先,InfLLM v2 是一个针对端侧场景优化的注意力结构,这让其天然有良好的端侧适应能力。
相比于云端大模型注意力机制对内存的高占用现状,面壁团队又大幅降低了 KV 缓存。据面壁披露,在 128K 长文本场景下,MiniCPM 4.0-8B 相较于 Qwen3-8B 仅需 1/4 的缓存存储空间,从而大幅提升了整个模型在端侧场景的通信与计算效率。
而通过重写底层算子,再与 ArkInfer 等成熟的硬件底层工具结合,让 InfLLM v2 可以在端侧硬件中发布最大的价值。
值得一提的是,这是除了 DeepSeek 以外,第二个有能力在硬件层面进行软硬一体优化的团队。
此外,相比于此前的 InfLLM v1,v2 将无训练的注意力架构方式,升级成为了“可训练”稀疏注意力架构,进一步提升在实际使用场景中的效率。
例如,通过训练,当 v2 在处理 128K 长文本时,每个词元仅需与 不足 5% 的其他词元 进行相关性计算。这意味着相比行业普遍的 40%-50% 稀疏度,面壁将端侧的稀疏度降低到 1/10,约为 5% 的稀疏度。
5% 其实已经与人脑的稀疏激活比例相当。某种意义上来说,人脑的运作接近一个稀疏的端侧模型,而平均每次任务激活的神经元也不到 5%。这给面壁的研究人员在端侧研发进展中提供了很好的范本——如何在有限计算资源的情况下达到效率最优。
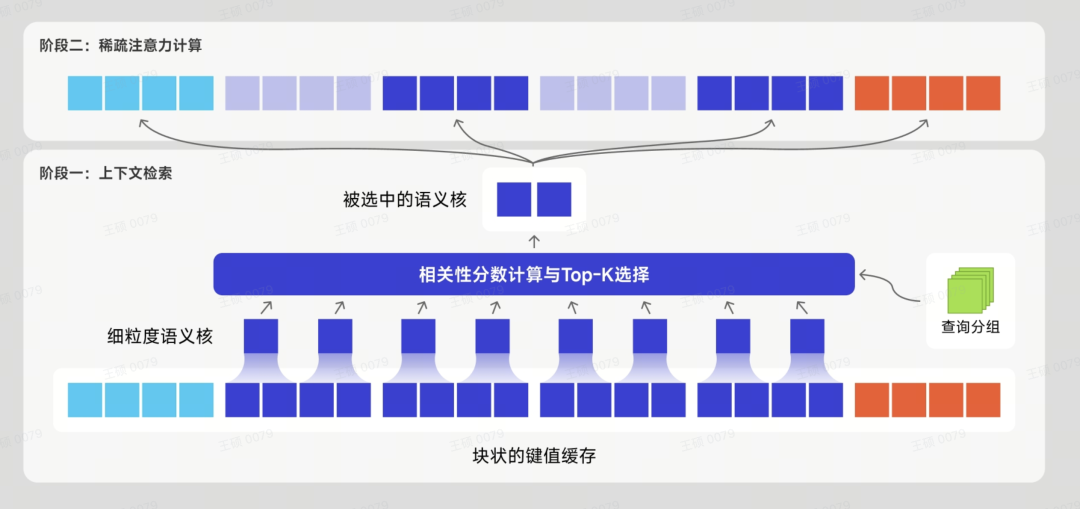
除了注意力架构外,面壁针对端侧环境对模型的堆叠层数也做出了优化。层数(Number of Layers)是指模型堆叠的可学习计算单元的数量,往往决定了模型的容量(Capacity)和复杂度,通过对每一层的非线性变幻,模型可以逐步提取更高阶的数据特征
一般而言,层数越多意味着模型越复杂,越具备全局能力和高阶语义的识别能力。但与之相对应的,则是更多的能耗和效率损失。以云端大模型为例,GPT-3 和 GPT-4 的层数分别为 96 层和 120 层,而 DeepSeek V3 和 R1 均只有 61 层,巨大的层数差异也决定 DeepSeek 在模型效率方面具备了压倒性的领先优势。
面壁此次发布的 MiniCPM 4.0 也在层数上做了优化,在保持能力领先的同时,缩减了层数。MiniCPM 3.0-4B 的层数达到了 62 层,而此次 MiniCPM4.0-8B 仅为 32 层、同期 Qwen 的同级别模型为 36 层。
根据面壁方面表示,架构上的深度优化让 MiniCPM 4.0 从底层拥有了更强的效率优势。
小钢炮 4.0 的想象力
6 月 6 日,面壁发布了小钢炮系列大模型 MiniCPM 4.0,官方将其称作:“史上最具想象力”的小钢炮系列。因为除了架构层面的优化外,MiniCPM 4.0 几乎在数据、学习、推理与架构四个不同的侧面,都进行了不同程度的优化。
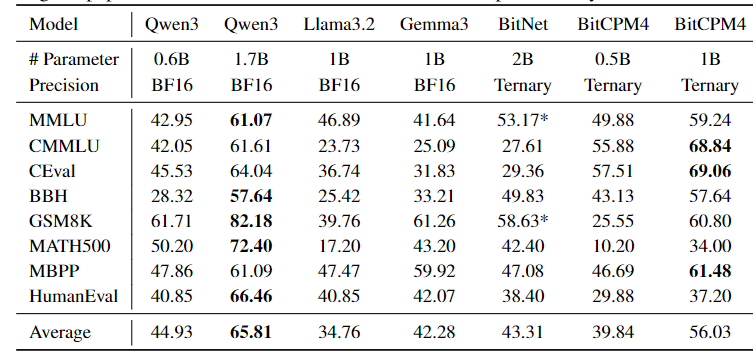
从数据上来看,整个 MiniCPM 4.0 此次发布的两个不同规模的模型,8B和0.5B,两个大模型均继续卫冕同级 SOTA 的领先地位。
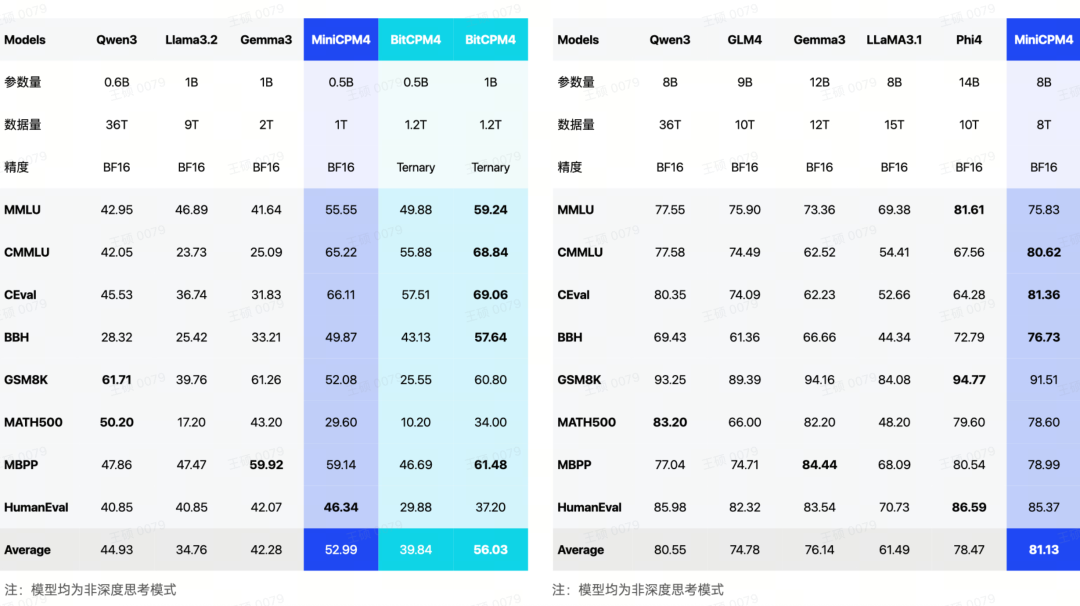
MiniCPM 4.0-8B 模型作为稀疏注意力模型,在MMLU、CEval、MATH500、HumanEval等基准测试中, 性能超越 Qwen-3-8B、Gemma-3-12B。MiniCPM 4.0-0.5B 在性能上,也显著优于 Qwen-3-0.6B,并实现了最快 600 Token/s 的极速推理速度。
引用面壁官方的介绍是:“在系统级稀疏创新的支持下,小钢炮 4.0 与过去产品相比,在极限情况下实现了 220 倍、常规 5 倍的速度提升。”
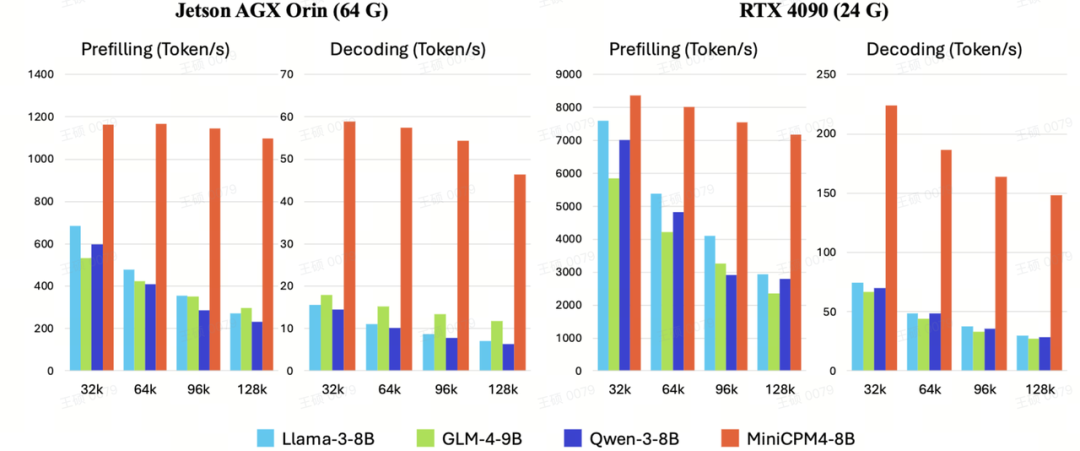
尤其在主打边缘计算的 Jetson AGX orin 芯片中(图左),MiniCPM4.0 几乎实现了断代领先。而且在不同规模测试下,相比于同类型的模型而言,MiniCPM4.0 的响应速度的衰减比例也明显更低。这从侧面体现了面壁团队很深入的端侧优化能力。
AI 大模型领域是一个复杂的“动力生态”,不同的玩家想要寻求的身位则不尽相同。有些模型(如 OpenAI 的“GPT-5”、DeepSeek 的“V4”),其目标或许是成为法拉利这样的全球动力天花板;有些方案则像卡罗拉,朴实但靠谱,力图成为全球销量最高的通用产品。
而面壁的小钢炮系列,或许更像是MiniCooper:小巧、精致,致力于用最合适的马力达到最好的驾驶体验——它对自己的要求是有性格的,性能强大,小野,拒绝无趣。
如果说 InfLLM 这样的架构升级是一辆汽车底盘,那么从从底盘和变速箱,到车身和动力系统,面壁几乎全面升级了小钢炮。
例如,面壁团队采用了创新的“稀疏注意力”模式,即让模型能够根据任务特征自动切换注意力模式。这其实就像汽车的两档“变速箱”,让汽车可以适合更加复杂的“端侧路况”。
在处理高难度的长本文、深度思考任务时,启用稀疏注意力以降低计算复杂度,而在短文本场景下切换至稠密注意力以确保精度与速度,实现了长、短文本切换的高效响应。这种「高效双频换挡」机制,类似混合稀疏注意力的模式设计,让 MiniCPM4.0 能够拥有灵活的能力。

而其专门自研的全套端侧推理框架 CPM.cu,以及此前提到过的内存改进的 BitCPM 量化算法,对多平台端侧芯片进行优化的 ArkInfer 跨平台部署框架,则像是 MiniCPM4.0 的高马力“三缸发动机”。

例如 CPM.cu 端侧自研推理框架是一个针对端侧大模型推理设计的轻量、高效的 CUDA 推理框架,核心支持 稀疏架构、投机采样 和 低位宽量化 等前沿技术创新。而 MiniCPM4.0 则首次将这个框架与 InfLLM 做了融合,从而改进了整个系统在硬件层面的表现效率。
其中 FR-Spec 轻量投机采样类似于小模型给大模型当“实习生”,并给小模型进行词表减负、计算加速。通过创新的词表裁剪策略,让小模型专注于高频基础词汇的草稿生成,避免在低频高难度词汇上浪费算力,再由大模型进行验证和纠正。仅 CPM.cu 框架让模型实现了 5 倍的速度提升。

BitCPM 量化算法,实现了业界 SOTA 级别的 4-bit 量化,并成功探索了 3 值量化(1.58bit)方案。通过精细的混合精度策略和自适应量化算法,模型在瘦身 90% 后,仍能保持出色的性能表现。在优化后,CPM4 1B 的分数远超 Llama3.2 和 Gemma3 同规模的表现,仅稍逊于 Qwen3 1.7B 的表现。
而 ArkInfer 的架构设计主要是为了满足在碎片化的终端硬件环境中进行统一、高效部署的需求。它通过提供一个强大的抽象层,成为了一个可以适配多种不同芯片“适配器”,确保端侧多平台 Model zoo 丝滑使用。
据面壁团队介绍,通过 ArkInfer 的支持,MiniCPM4.0 能够支持多种平台,如联发科、英伟达、高通和瑞芯微等平台各自拥有原生的推理框架(例如,NeuroPilot、Genie、RK-LLM、TensorRT-LLM,以及用于 CPU 的 llama.cpp)等,ArkInfer 都能将这些框架无缝集成。
除了软硬一体外,底层硬件编译与优化能力、高质量对齐数据与训练策略的优化,则像是一辆汽车的“产线”,其中的每一个细节都决定了产品的整体性能。
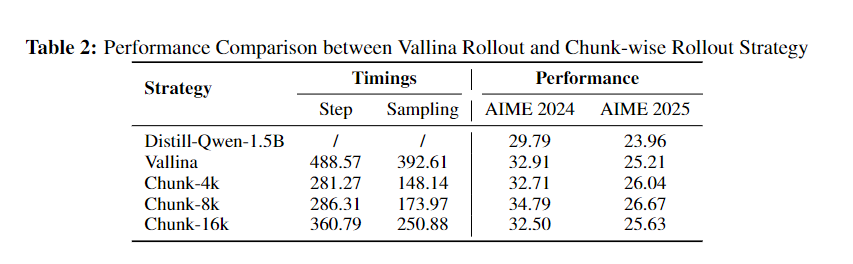
以底层硬件编译与优化能力为例,除了 BitCPM 与 ArkInfer 已经展示出“软硬一体”优化能力外,MiniCPM 4.0 采用了Chunk-wise Rollout 策略,将分块式强化学习引入通过优化 GPU 利用率和最小化计算资源浪费,显著提升了 GPU 利用率并降低了计算机资源浪费。
在数据层面,面壁团队在进行了大量的筛选和对齐工作。
如 Ultra-FineWeb,后者通过高知识密度数据筛选系统建立了严格的准入机制,实现 90% 的验证成本下降。再结合轻量化的 FastText 工具进行大规模数据质检,使得MiniCPM 4.0在处理 15 万亿 token 数据仅需 1000 小时 CPU 时间。
此外,UltraChat-v2 合成了包含数百亿词元的高质量对齐数据,在知识类、指令遵循、长文本、工具使用等关键能力上进行定向强化。在高质量数据与高效训练策略的加持下,相比同尺寸开源模型,MiniCPM 4.0-8B 仅用 22% 的训练开销,即可达到相同能力水平。
在训练策略方面,MiniCPM 4.0 应用了迭代升级后的风洞 2.0 方案(Model Wind Tunnel v2)。
通过在 0.01B-0.5B 小模型上进行高效实验,搜索最优的超参数配置并迁移到大模型,相比此前的 1.0 版本,风洞 2.0 将配置搜索的实验次数降低 50%。

有些人将 DeepSeek 范式的胜利称作某种“掀桌式”的、带有“工程美学”式的创新,人们通过 DeepSeek 发现了一条 OpenAI 模式以外的道路:一条虽非通向最高处,却是通向更广处 AGI 路径的可行性。
正如面壁智能首席科学家刘知远今年初对ai科技评论表示的那样,在他看来,大模型“已经找到了一种通用地从数据学习知识的方案”,“已经在迈向通用智能了。”
显然,从“迈向通用智能”和“抵达通用智能”,智能的生长总归需要一个过程,而且它大概率是会沿着它技术效率的方向蔓延。
因为无论智能上限如何增长,效率与普惠永远是一切人类技术演进后最终的归宿,而端侧探索或许将会成为其中必不可少的答案。

扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


腾讯AI秘密“换船”:元宝失宠,WorkBuddy接棒
2026-06-12

Claude深夜炸场!放出史上最强“危险级”模型Fable 5,价格太逆天
2026-06-10

vivo、荣耀接连入场,戳破了具身智能的AI叙事
2026-06-10

苹果把Siri交给了Gemini
2026-06-10

微信“抢婚”豆包?
2026-06-11

Kimi年内第3轮融资来了,估值300亿美元
2026-06-11

普通人怎么读懂Token经济学?
2026-06-11

一场「贩卖焦虑」的生意,正在被AI重新定价
2026-06-12