
杭州在六小龙之后,又开始投资北京六小虎了
本文由 量子位 撰写/授权提供,转载请注明原出处。
以下文章来源于:量子位(QbitAI)
作者:金磊
杭州在有了六小龙之后,下一个目标,“盯”上了北京的六小虎——智谱。
因为就在最近,从智谱传出来的最新融资消息是这样的:
在杭州的大力支持下,近日智谱完成一笔金额超 10 亿元人民币的战略融资,参与投资方包括杭州城投产业基金、上城资本等。

而这笔资金的用途,在这次融资消息中也有所透露,会用于智谱国产基座 GLM 大模型的技术创新和生态发展。
当然,反过来,智谱也会将这笔资金用于更好服务浙江省和长三角地区蓬勃发展的经济实体,全面推动基于人工智能技术的数字产业转型升级。
据悉智谱节后不到一个月收入超过 1 亿,API 平台付费增长超过 30%。
随之而来的一个问题就是:
六小虎中有四家 base 在北京,但杭州为什么会 pick 智谱?
为什么是智谱?
如果用一句话来总结,那或许就是智谱够全、够快和够实力。
首先,从大模型发展的版图来看,智谱可以说是国内唯一一个可以全面对标 OpenAI 的大模型玩家。
在千亿基座模型、对话模型、代码模型、多模态模型、推理模型和 Agent 技术等领域,智谱已经实现了全覆盖。
并且它自主研发的 GLM 架构全面对标 GPT 系列,形成了一套完整的超大规模智能模型体系。
GLM 架构从底层算子到训练框架均实现自主研发,可以说是突破了西方技术封锁,形成自主可控的创新体系。
OpenAI 的 GPT 系列则主要使用自回归模型,这种模型在生成文本时是单向的,即它只能基于之前的词来预测下一个词。
但这种单向性可能限制了模型在某些自然语言理解(NLU)任务中的表现,因为它无法充分捕捉上下文之间的依赖关系。
而智谱的 GLM 采用了自回归填空(autoregressive blank infilling)作为主要的预训练目标。这种方法允许模型在生成文本时同时考虑上下文信息,从而增强对语言结构的理解和生成能力。
值得一提的是,GLM 原创算法还获得了《自然》期刊报道。
其次,智谱近几年在大模型的迭代速度,在国内大模型玩家范围内,称得上是够快的。
2024 年推出的基座模型 GLM-4-Plus、Agent 模型 AutoGLM、推理模型 GLM-Zero 等,性能比肩 OpenAI 同类产品,并在多模态和长文本推理场景中表现突出。
而这还只是智谱众多“发布动作”的一隅,仅是去年,按照时间轴来排序,“打开方式”是这样的:
12 月,发布 GLM-Zero-Preview,Zero 推理模型,擅长通过逻辑推理来解决数理问题。
11 月,发布 AutoGLM 升级版,可自主执行超 50 步的长步骤操作,也可以跨 app 执行任务,开启“全自动”上网新体验,支持基于浏览器的数十个网站的无人驾驶。
11 月,发布 GLM-PC 内测,基于智谱多模态模型 CogAgent,探索“无人驾驶”PC。可代替用户参与视频会议、处理文档、搜索网页并总结、远程定时操作。
11 月,视频模型 CogVideoX 升级,支持 10s 时长、4k、60 帧超高清画质、任意尺寸以及更好人体动作和物理世界模拟。CogVideoX v1.5-5B、CogVideoX v1.5-5B-I2V 同期开源。
10 月,GLM-4-Voice 端到端情感语音模型发布,并上线清言 app,能够理解情感,有情绪表达、情感共鸣,可自助调节语速,支持多语言和方言,并且延时更低、可随时打断。
10月,AutoGLM 内测版发布,只需接收简单的文字/语音指令,就可以模拟人类操作手机,不受限于 API 调用。
10 月,和三星、高通宣布合作,分别共同打造 AI 产品和端侧多模态交互大模型。
8 月,发布跨文本音频和视频模态实时推理大模型 GLM-4-Videocall,实现 AI 与人实时视频通话。通过 API 接口可无缝部署在包括手机在内各类带摄像头端侧设备。
8 月,新一代基座大模型 GLM-4-Plus 发布,语言理解、指令遵循、长文本处理等方面性能全面提升。
7 月,视频生成模型“清影”在清言 PC 端、移动应用端以及小程序端正式上线,提供文本生成视频和图像生成视频的服务,30 秒即可完成 6 秒视频生成,真实还原物理世界中的运动过程。
6 月,GLM-4-9B 模型开源,支持 100 万 Tokens 长文本和 26 种语言,并首次开源了基于 GLM 的视觉模型 GLM-4V-9B,多模态能力比肩 GPT-4V。
1 月,新一代基座大模型 GLM-4 发布,整体性能相比上一代大幅提升,支持更长上下文,具备更强多模态能力,推理速度更快,支持更高并发,大大降低推理成本。
除此之外,和 OpenAI 所打的“close”路数不同,智谱还是国内最早开源大模型的企业。
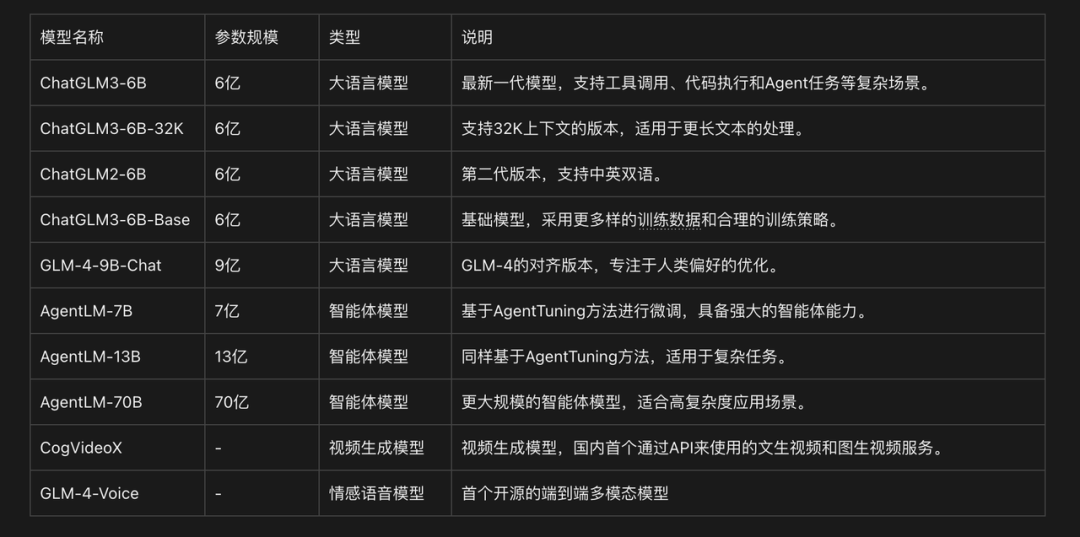
从 2021 年发布百亿模型 GLM-10B,到 2022 年推出首个千亿开源模型 GLM-130B,再到 2023 年上线 ChatGLM,智谱可以说是通过开源推动了中国大模型技术的普及。
而且据了解,智谱今年还计划开源包括基座模型、多模态模型等在内的新一代产品,进一步扩大技术辐射范围。
不仅如此,从市场范围来看,这也不是智谱第一次受到资本的认可。
就在去年 12 月份,智谱完成一轮 30 亿人民币融资,而时隔仅 2 个月,又得到了来自杭州的 10 亿元融资。
更早的,就在去年 9 月,中关村科学城公司宣布以投前 200 亿估值领投智谱,智谱也是国内估值率先超过 200 亿的大模型创业企业。
并且智谱的商业化路径也是清晰,已经形成“模型即服务(MaaS)+私有化部署+智能体平台”的多元模式,已经形成了庞大开发者生态,商业价值高且发展稳定 。
由此,杭州选择智谱,本质上是基于技术自主性、生态开放性、前沿前瞻性、商业可行性四重逻辑。
这一投资不仅是资本行为,更是杭州打造“全国数字经济第一城”的关键落子,有望在AI时代重塑城市竞争力。
会是下一个DeepSeek吗?
在 AI 竞赛的全球版图上,“DeepSeek 时刻”已成为大模型领域的圣杯——它象征着技术突破、生态重构与商业价值的共振。
智谱首席科学家唐杰昨天也在微博公开表示:
DeepSeek 的成功不仅激发了产业界的热情,也让学术界为之一振。它让大学和研究机构意识到了大模型基础理论和技术的重要性。各个大学纷纷加大投入,尤其是理论研究,看来理解 AGI 的本质就在眼前了。。。大家一起加油。AGI 是一个马拉松,我们要调整好节奏,分配好体力,调整心态。
从上述种种总结来看,智谱在国内算的上是非常全面的选手,并且和 DeepSeek 一样,本着开源、降本的打法。
而一座城市需要的不仅是技术明星,更是能串联芯片厂商、开发者社区、行业用户的生态级企业。
从杭州 pick 智谱这一举动来看,可以说明智谱是符合这一“气质”的企业。
站在更宏大的视角,回望工业革命史,真正改变文明进程的从不是单一技术突破,而是技术扩散引发的系统性变革。
因此,比起智谱能否在全球范围内再打出一次“DeepSeek 时刻”,或许我们更应该期待的是能否打出更系统性的“智谱时刻”。
对于这一点,智谱其实也有自己的布局,提出了一套富有前瞻性的 AGI 分级架构。
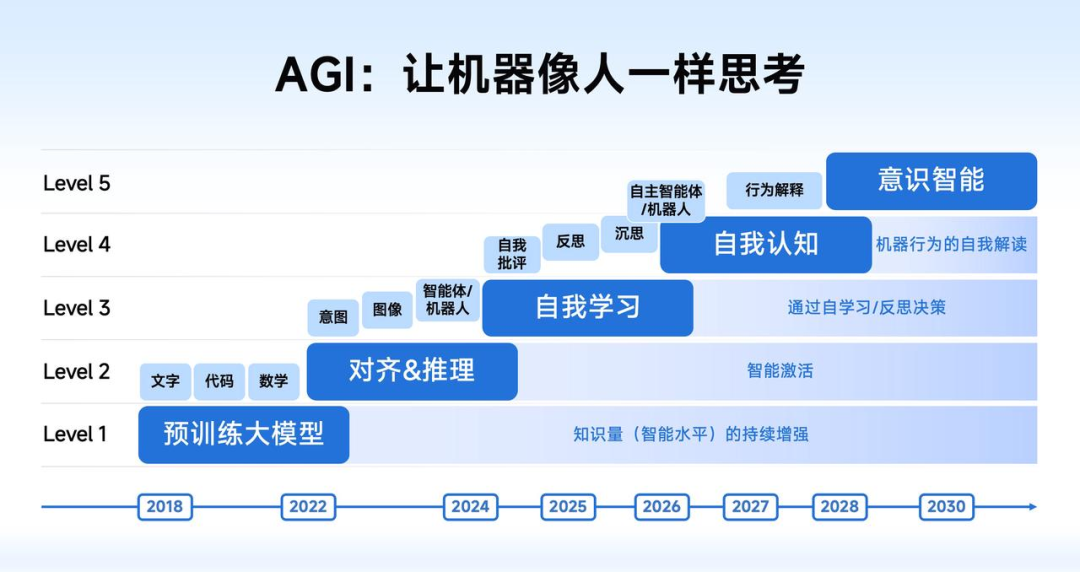
L1 是预训练大模型,作为基座,就像知识的“超级富矿”,海量知识汇聚其中,为 AI 发展筑牢根基。
L2 为对齐&推理阶段,堪称“智能激活”时刻。一方面精准匹配人机意图,横跨文本、图像、视频、音频等模态实现对齐;另一方面让机器掌握类人推理与规划能力,告别机械,开启智能蜕变。
发展至 L3 自我学习阶段,AI 实现重大突破。此前 L1、L2 靠人类引导学习,到这里 AI 学会自我批评、反思,甚至沉思,凭此应对开放域难题,即便未知挑战,也能像人类般反复尝试、探索求解。
来到 L4 自我认知阶段,AI 新增一项关键能力,能对自身行为、决策结果给出清晰解释,明白因果关联,提升智能的可解释性。
L5 意识智能则是 AGI 顶峰。最终达成”机器科学发现者”的终极形态,使 AI 不仅能够解决已知问题,更能像人类科学家般提出原创性科学假设。
总而言之,今年国产 AI 的发展进程,智谱绝对是值得关注的玩家之一。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群

什么!ChatGPT也要刷脸实名认证了?
2026-06-18

一边裁员承压,一边半年狂赚数亿,AI短剧到底谁在赚钱?
2026-06-16

灵光走独木桥
2026-06-16

散户人均赚3.8万,韩国怎么就成了AI最大赌场?
2026-06-16

半年内收入翻倍不止,巨头夹击下的Manus和Genspark跑通变现
2026-06-17

具身智能,卖数据的先赚钱
2026-06-17

今年618,AI到底帮了谁?
2026-06-17

SpaceX吞下Cursor,马斯克狂补Coding:AI大战新重点定了
2026-06-18










