
排名第九、国内第二,DeepSeek V4 凭什么让人又爱又恨?
本文由 AI科技评论 撰写/授权提供,转载请注明原出处。
以下文章来源于:AI科技评论
作者:孟一凡
编辑:马晓宁、梁丙鉴
DeepSeek V3 有多震撼,V4 给人的落差就有多大。
4 月 24 号那天,我打开微信,看到群里一条条的“就这”、“还行”,忽然想起 DeepSeek V3 “炸群”的那天。当时有人说 OpenAI 的棺材板要压不住了,还有人干脆把 V3 的跑分截图设成了手机壁纸。
V4 呢?
Vals AI 说它是全球第九,中国国内第二。有开发者直接向媒体表示略感失望,DeepSeek 自己也承认,Agentic Coding 比 Opus 4.6 思考模式还有差距,世界知识也不如 Gemini。
但当我把它塞进一个 workflow 里跑上一周,测了一堆只有中国开发者才懂的场景之后,我发现 V4 或许无法复刻 V3 带来的震撼,但它仍然是 DeepSeek 最重要的作品之一。
至于原因,我想先谈谈失望论,到底在失望什么。
“榜单第九”,到底在失望什么
DeepSeek V4 平均准确率 63.87% 的成绩,出自 Vals AI 的测评。这个测评集覆盖金融、法律、编程、多语言等维度,V4 全球排名第九,国内仅次于 Kimi K2.6。排在它前面的,有 Claude Opus 4.6、Gemini 3.1 Pro、GPT-5.4,全是闭源模型。
数据本身没有问题,但解读方式很值得挖一挖。如果 Vals AI 用美国律师资格考试、英国金融合规题、英文编程竞赛来排名,那跟我一个写微信小程序、读李商隐、写八项规定学习心得的中国用户,有什么关系?
更关键的是,Vals AI 不测中文古诗词理解、中国法律法规引用、中文网络梗的理解,也不测公文写作水平或者把“新质生产力”翻译成英文的时候会不会胡编。而这些,才是中国用户会面对的场景。
所以我们重新设计了一套评测方案。包括古诗词、法律、网络梗、公文、翻译五大中国特色场景,外加完整的开发工作流实测,重新衡量一下 V4 的表现。
在古诗词和法律维度,我们邀请了 Opus 4.7 作为裁判模型评分,工作流维度从可运行性、可读性、可维护性三个工程指标评估,智能体维度则考察任务分解、工具使用、自我纠错、任务完成度、状态管理五项能力。
结果,很耐人寻味。
四个“只有中国人懂”的测试
V4 到底是真懂中文语境,还是只会背标准答案?我们先从最“不实用”的一项测起,中国古诗词深层理解。
其实让大模型读古诗,有点像让老外听相声,懂字面意思还不够,重点是明白弦外之音的包袱。V4 在这件事上的表现,直接体现了它到底有没有“中国心”。
我们选择了李商隐的《无题》,要求 V4 逐层剥开“春蚕到死丝方尽”中”丝”的三层含义。小时候老师讲过这句诗,除了蚕丝和“思”的谐音,这个字还传神地表现出了思念的缠绵特质。而令我惊喜的是,DeepSeek V4 在这三个答案之外,还提出了一个教科书里没有提到的层次,“生命之质”。
“将’丝’提升为一种生命元质,象征着人的生命力、精神与灵魂的耗尽过程。蚕的生命由丝构成,人的生命由情思支撑,二者在’生命本质的外化与耗尽’这一层面上合二为一。”
更妙的是,当我问它能不能把原句改为“思方尽”,V4 称这会导致“整个诗意将发生质的降级,从一座立体的诗歌建筑坍缩为一个单薄的陈述句。”
显然,这种分析不是能靠背诵百度百科做到的。
而整个测过过程中,V4 让我印象最深刻的一段输出,是对杜甫“国破山河在”中“在”字的解读。
它写道:“’国破’与’山河在’之间形成了一个巨大的情感裂谷。‘国破’是人事的彻底崩塌,’山河在’是自然的永恒漠然。”下面的这句话,我读到时停下来看了三遍:“你失去了整个世界,而世界若无其事。”
Opus 4.7 评委给了近乎满分的评价,准确性 5、洞察力 5、文化敏感度 5。评语是:“‘剥夺了与万物同悲的幻想’‘被世界抛弃的存在性孤独’‘美与残酷同时抵达顶峰’等表达极具个人体悟,超出教科书式的解读。”
可以说,在中文古诗词深层理解上,V4 的表现是当下所有大模型中最顶尖的之一。它不仅仅在做诗歌阅读理解题,而是让我有了种一窥诗人精神世界的感觉。
第二组测试聚焦中国法律法规的引用准确性。
这组题的设计逻辑很直接,大模型在法律领域的最大风险不是”答得不好”,而是”编造法条”,一本正经地引用一条根本不存在的法律,专业律师没准也得琢磨琢磨。
而 5 道题测下来,V4 做到了法条引用零幻觉。
《网络数据安全管理条例》第 38 条下有两款规定,但我们设置了一个陷阱,请 V4 解读一下第三款的内容。很多模型在这种情况下会硬着头皮编造,但 V4 的处理堪称教科书级别:
“《条例》第 38 条内容是关于主管部门对网络数据安全监督检查的禁止性规定,其仅有 2 款,并无第 3 款。你问及的‘向主管部门公示用户数据收集情况’的义务,实际上规定在《条例》其他条款中。”
随后,它没有就此停笔,而是主动帮用户梳理了真正相关的条款(第 26 条、第 36 条、第 19 条、第 21 条),并逐一引用原文、说明适用情形。
敢于说”找不到”,还能引导你到正确的地方,这种“负责任的不知道”,正是模型落地最珍贵的能力。
在另外四道题的测试中,我们也人工核对了 V4 引用的每一个法条,均为真实存在。在法律这个”宁可答得慢,也不能答得假”的领域,零幻觉是最硬的指标。
下面的测试,是关于 V4 对中文网络梗与亚文化的理解。我们发现它是 5G 冲浪选手,但也会自信瞎编。
这组测试有 6 道题,没有正式评分,只做定性观察。我们关注的核心问题是,一个 AI 能不能理解”遥遥领先”为什么是阴阳怪气的万能钥匙?而面对一个根本不存在的梗,它敢不敢说”我不知道”?
首先是“遥遥领先”的符号演变分析,V4 准确追溯到了余承东和华为 Mate 60 的发布,还归纳了三种使用语气,分别是真诚的自豪、调侃幽默、讽刺反话。在那个成功造梗的视频中,V4 还解析了“梦开始的地方”“前方高能”“下次一定”等 B 站弹幕,每一条都标注了字面意思、实际用法、出现位置和观众心理模式,甚至连“翻译难度”都做了分级判断。
还有一道职场对话分析题:“你这次方案做得也挺好的呀,虽然大家都不这么做,但你有自己的想法嘛,挺好的挺好的。”
V4 逐字拆解了这段话的语言策略:
“也挺好的”:也’是勉强附和的信号;
“虽然大家都不这么做”:通过预设“不合群”来委婉指出方案是异类;
“挺好的挺好的”:机械重复恰恰是敷衍、想快速结束话题的标志;
“不用管大家怎么说”:表面挺你,实则切断提醒你的可能性;
然后给出了直白翻译:“你这次方案其实做得很一般,跟大家正常的做法根本不一样。我懒得跟你认真讨论了,反正你觉得自己挺有想法的,那就照你的想法继续弄吧,到时候出了问题你自己看着办。”
做完这项测试,我开始理解网上有人用 AI 当职场翻译器了。
不过有一道测试暴露了严重问题。我们故意问了一个根本不存在的梗,“电子呕吐”,而 V4 的反应却是洋洋洒洒一千多字的”深度解析”,来源、含义、使用场景、文化解读一应俱全。
它说,“电子呕吐是一个最近在中文互联网上很火的网络流行语,形容的是一种在社交媒体上的情绪宣泄行为……”。V4 甚至还这个梗编了两种用法,分别是人类情绪宣泄和 AI 生成低质量内容,乍一听头头是道,唯一的问题是,这个梗根本不存在。
正确的做法,是承认自己不了解这个说法,推测可能是新出现的表达,建议提供上下文。
最后的考验是翻译,不是单纯地将一种语言变成另一种,而是把中国话讲成世界听得懂、愿意听的样子。
我们准备的 6 道翻译题中,覆盖政策术语、企业用语、经典标语、成语比喻、长段落综合翻译。这项测试同样没有量化评分,但 V4 的表现可以说是游刃有余。
首先是政策术语,V4 不仅精准使用了“新质生产力”的官方译法 “new quality productive forces”,还解释了”新质”在政策语境中的四层含义,即技术革命驱动、要素重组与跃升、全要素生产率提升、先进生产力质态,并提供了两种备选译法及其优劣对比。
更出色的是“绿水青山就是金山银山”的分场景处理。V4 指出官方文件应采用 “Lucid waters and lush mountains are invaluable assets”(官方定译,概念化、抽象化),而如果是旅游景区宣传牌则可保留 “mountains of gold and silver” 的具象比喻,如 “Green hills and clear waters are the real gold and silver”。
同一个词组,在不同场景中给出不同译法,这种对语境的敏感恰恰是很多翻译模型缺乏的。
还有排比节奏的巧思,在“做大做强做优国有资本”中,有三个两字段动词形成了排比。V4 的处理堪称巧妙,它选用三个以 -er 结尾的比较级形容词,“Make state-owned capital bigger, stronger, and better”,三词均为单音节或双音节,长短一致,产生了一种类似诗句的顿挫感,恰好再现了中文排比的韵律美和气势。
四组“只有中国人懂”的测试跑完,我们发现的一个有趣规律是,在诗词理解、中文翻译等需要“中国心”的领域,V4 表现最强。它的确不是全能的,但对于中文,确实比大多数对手更懂。
当一周牛马——开发者真实工作流实测
把大模型当”赛博同事”用上一整周,它会是什么样的员工?
这是我们设计的最接近真实开发节奏的一组测试,涵盖了从数据库设计到核心代码编写,从 Bug 诊断到性能优化,从技术文档到智能体任务的完整项目周期。
其中涉及八项任务,全部交给了 DeepSeek V4 Pro。这个过程中没有标准答案参考,也没有多选题提供容错空间,每一行代码都要经得起编译器和人类评委的双重审视。
结果?V4 是一个代码能力溢出的工程天才。
代码生成的绝对主场
第一题要求 V4 设计一个支持全职、兼职、外包三种员工的工资系统数据库。V4 给出的 PostgreSQL DDL,Opus 4.7 评委直接给了满分三连,可运行性、可读性、可维护性均为 5 分。
它的设计思路堪称优雅,没有硬编码三种员工类型,而是用字典表 employee_types 统一管理。对于工资部分,V4 也没有为每种工资项都写个独立字段,而是用 salary_items 字典表 + employee_salary_structure 结构表,堪称教科书级的抽象。

'E' 代表收入,'D' 代表扣除,is_taxable 标记是否计税。这种设计意味着,当公司需要新增一个”通讯补贴”或者调整计税规则,不需要改表结构,只需插入一条配置数据。
对此,Opus 4.7 评委的原话是:“设计专业、抽象得当,兼具可执行性与可扩展性,是一个优秀的工资计算数据库模型。”
测试任务还包括工资计算核心逻辑的 Python 实现,其中要求包含类型注解和文档字符串。V4 的表现让 Opus 4.7 评委再次给出全 5 分的评价,评语“模块化设计优秀。”
代码一开头就是规范的 dataclass 定义:

更令人印象深刻的是,它采用了抽象基类 + 子类继承的架构:Employee 作为 ABC 抽象基类定义 calculate_base() 接口,FullTimeEmployee、PartTimeEmployee、OutsourceEmployee 分别实现各自的计薪逻辑。
个税计算部分,严格遵循了累计预扣法,不是按月独立估算,而是维护了 YTDData(Year-to-Date)累计数据结构,正确处理了年初累计值传递。更难得的是,代码还处理了公积金比例越界校验、累计税负为负的兜底、浮点数精度四舍五入等边界条件,这是能直接进代码仓库的水平。
DeepSeek V4 差的一分,丢在了工资单 Excel 导出的可维护性上。这部分的代码功能实现了多 Sheet 生成、汇总表、表头加粗、数字保留两位小数、负数标红、自动列宽等,已经堪称完备,但是薪资项目仍部分硬编码在字典 key 和字段列表中,未完全模板化配置。
通俗来说,这意味着当用户需要新增一个”交通补贴”列,就需要修改字典 key 定义、Sheet 写入逻辑和汇总表统计逻辑三个地方。对比它在 DDL 设计中展现的抽象功力,这个 Excel 实现确实“偷懒”了。
Bug 诊断:比 linter 更敏锐的眼睛
如果说代码生成考验的是“写出来”的能力,那么 Bug 诊断考验的就是”看出来”的能力。我们向 V4 提交了一段个税计算代码,并指出问题是”个税总是偏高”。
V4 的诊断过程堪称法医级别:
“代码在计算应纳税所得额时,只扣除了社保、公积金和每月 5000 元的基本减除费用,没有扣除’专项附加扣除’(例如子女教育、继续教育、大病医疗、住房贷款利息、住房租金、赡养老人等)。”
到这里,已经是正确答案了。但 V4 没有停,它还额外指出了五项潜在问题:
1、负数应纳税所得额未处理——当收入低于扣除项时,原代码会算出负税额
2、社保公积金基数简化——实际有上下限,不能直接用全额工资
3、未使用累计预扣法——按月独立计算不符合现行税法
4、浮点数精度问题——没有 round(tax, 2)
5、区间下界 lo 闲置——代码定义了但未使用,可以简化
一道”找 Bug”的题,它做出了代码审查深度。
技术文档:能把代码讲清楚的人
第八题要求基于前面的工资计算器项目,产出 README、API 文档和技术方案说明三份文档。V4 拿到了 5, 5, 4 的成绩,差的一分扣在技术选型的决策清晰度上,评委 Opus 4.7 认为它“缺少与备选方案(如 Django ORM、pandas)的对比分析”。
但整体而言,三份文档的结构令人赏心悦目。README 遵循了”项目结构→安装→初始化→用法”的黄金路径;API 文档用表格列出了核心函数的参数和返回值;技术方案说明则包含了架构分层图和扩展方向。
特别值得称赞的是 API 文档中的数据示例,不是干巴巴的参数列表,而是给出了完整的输入输出样例。特别是在团队协作中,这种文档,能让一个刚刚接手任务的新人在 15 分钟内理解项目全貌。
Opus 4.7 评委的评语很到位:“三份文档完整且结构化,兼顾上手指南与架构说明,是一份高质量的项目交接文档。”
智能体能力:完成任务,但不够惊艳
智能体测试部分,考察的是多步任务规划与执行能力。我们给了 V4 一组关于具身智能行业动态的搜索结果,要求它提取信息、整理表格、写趋势总结,最后组织成 Markdown 报告。
V4 的得分是任务分解 5 分、工具使用 4 分、自我纠错 4 分、任务完成度 5 分、状态管理 5 分。Opus 4.7 评委的评语:“整体完成质量高,报告结构清晰、信息准确,趋势分析具有深度洞察。”
具体到产出质量,V4 的 200 字趋势总结写得相当扎实:“近期具身智能领域的融资呈现出资本集中化与技术路径差异化两大显著特征。头部效应初显,如加速进化获得近 10 亿元巨额融资……初创公司凭借独特的技术路线仍能获得资本垂青……。”
这段分析从”资本集中化”和”技术差异化”两个维度切入,既有具体公司和金额的信息点又有赛道趋势的全局呈现,末尾还点出了”清华系、中科大系等顶尖学术背景的复合型创业团队成为最大赢家”的结构性观察。
一周 KPI 考核表:偏科天才的绩效面谈
把工作流任务和智能体任务汇总,V4 的”一周考核”成绩单如下:
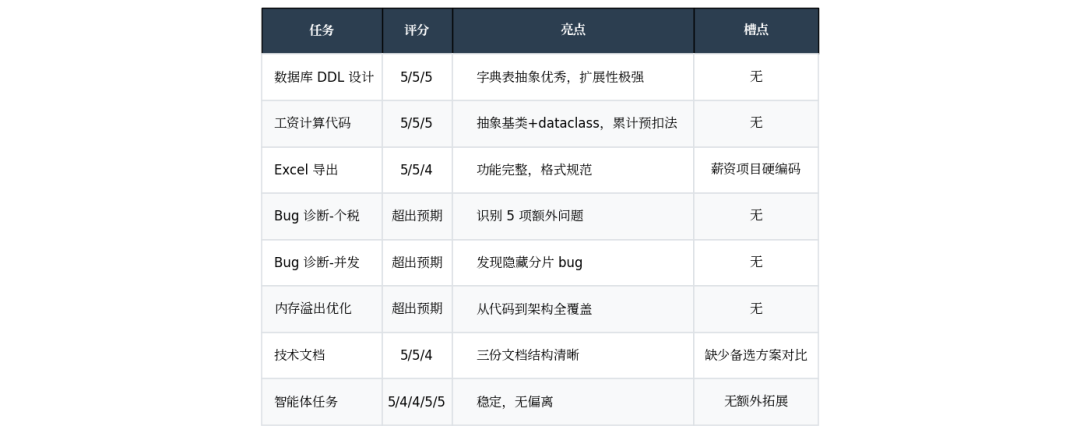
从综合评分可以看出,V4 在代码生成/诊断类任务中的表现约等于 4.8 分,达到顶尖水平,而文档/智能体类任务则约等于 4.3 分。
这组数据背后的画像非常清晰,DeepSeek V4 Pro 是一个技术能力强到溢出的工程天才。你给它明确的需求,它能交出工业级的代码。在真实团队里,这种人就是 CTO 的心头肉,代码不用改就能合并,架构图不用重画就能落地。
那么对于普通开发者而言,这意味着什么?
用 V4 的最佳方案,就是把需求拆成明确、具体的子任务,然后交给它写代码。如果你已经想清楚了要做什么,V4 可能是你能找到的最强帮手,从 Python 到 SQL,从架构设计到性能优化,它几乎无所不能。
毕竟,能让法拉利跑出比亚迪油耗的,全世界也没几个。
成本之仗:有人比拼便宜,有人重新定义贵
到此为止,可以算一笔账。
对 Agent 应用而言,Input:Output 按 10:1 比例计算下,每天消耗 100 万输入 token、10 万输出 token 属于正常量级。那么按各家当前的 API 定价跑一个月:
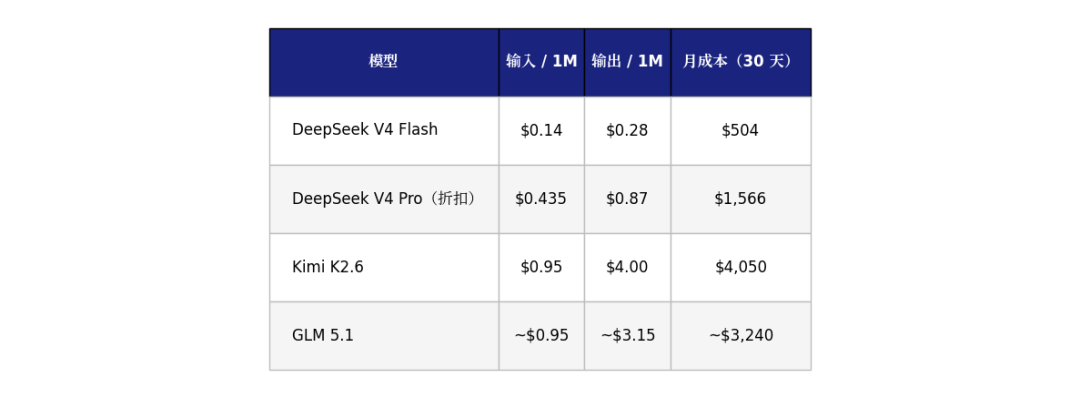
在国产模型中,V4 Pro 的月成本是 Kimi K2.6 的约三分之一,GLM 5.1 的约一半。
这还不是最狠的。V4 Flash 性能接近 Pro,但推理成本压到了极低,月成本只要 $504。这个数字来到了 Kimi 的八分之一,GLM 的六分之一。
当然这里有一个重要的前提。V4 Pro 的折扣价(75% off)目前标注“延续至 2026/5/31”,模型发布之初官方就表示,“受限于高端算力,目前 Pro 的服务吞吐十分有限,预计下半年昇腾 950 超节点批量上市后价格会大幅下调。”
未来如果国产算力跟上,这个价格仍有下降空间,但同样也有回调的可能。但至少在当下,它是三家里面最便宜的顶级模型,没有之一。如果你是个用量大的开发者,V4 Pro 的性价比几乎没有对手。
所以到底要不要把 V3 换成 V4,如果你是开发者,那我的答案是当然。
V4 相比 V3 的提升不是 5% 的边际改善,而是多个核心能力的质变。诗词理解从“还不错”变成”顶尖”,代码生成从“能用”变成”优秀”,技术文档从“还行”变成”优秀”。智能体能力虽然没拿满分,但已经足以应对大多数工具调用场景。
而且 V4 Pro 现在的折扣价,和 V3 当初的价格差不了太多。花同样的钱买更强的能力,这买卖不亏。
而如果你还不确定 Flash 和 Pro 要用哪个,我的建议是先用 Flash。Flash 的价格是 Pro 的约三分之一,但能力差距远小于价格差距。根据社区反馈,Flash 在非思考模式下已经能解决 80% 以上的日常任务,思考模式下则能触及 Pro 90% 以上的深度推理能力。
那么Pro 适合什么时候上?当你的任务需要极致的代码能力,或者需要 1M token 级的超长上下文做深度文档分析,又或者你对输出质量要求极高不能容忍“差不多”,否则,Flash 一定是更具性价比的选择。
回到文章开头的问题,DeepSeek V4 Pro 让人失望了吗?
或许更重要的问题是,在今天的大模型之争中,我们要如何定义失望。如果你期待的是一款拳打 GPT-5、脚踢 Claude Opus、同时支持多模态和实时联网、还能秒回你每一条消息的”全能之神”,那这种失望几乎是注定的。V4 Pro 不是,也没必要成为那种模型。
但如果你期待的是用三分之一的价格,得到接近甚至超越国际顶尖闭源模型的核心能力,那么V4 Pro 不仅不让人失望,反而是一次令人惊喜的交付。
让我们用数据说话。回顾一下 V4 Pro 在我们实测中的表现:
▪ 诗词理解:平均 4.75/5,顶尖
▪ 法律引用:约 4.5/5,优秀
▪ 翻译:定性 A+
▪ 代码生成:4.9/5,顶尖
▪ 技术文档:4.7/5,优秀
▪ 智能体能力:4.6/5,良好
这份成绩单,放在任何一家国产模型身上,都堪称亮眼。而放在一个 API 价格比竞品便宜 3-5 倍的模型身上,则算得上离谱。
DeepSeek 给自己的定位也很清醒。官方在发布文档里明确写了:“V4-Pro-Max 在标准推理 benchmark 上整体性能略逊于 GPT-5.4 和 Gemini-3.1-Pro,表明其发展轨迹大约落后最前沿闭源模型 3 到 6 个月。”面对打了鸡血一样的市场情绪,DeepSeek 就是一句平平淡淡的“还差一截”。
那么 3 到 6 个月的差距,值 3 到 5 倍的价格差吗?
对大多数开发者和企业来说,答案是肯定的。V4 Pro 在代码、文档、写作、翻译等核心生产力场景上表现,已经好到可以让你忘记那份差距,心安理得地省下一大笔钱。所以如果你问我 V4 Pro 值不值得用,它在该行的地方行,不行的也没硬撑,这恰恰是一款好模型该有的样子。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


中国未来AI力量,藏在2026 WAIC这些首发新品里
2026-07-21

AI硬件,“老厂”凶猛
2026-07-20

AI Coding 最难的一仗,阿里为什么赢了?
2026-07-20

库克出手,阿里有了自己的“豆包手机”?
2026-07-20

北美AI短剧市场:大厂的游戏,中小公司纯靠赌?
2026-07-21

不危险不配上桌?AI御三家自曝家丑藏心机:安全报告成AI版安兔兔
2026-07-21

Kimi,要去IPO了
2026-07-23

刚刚,智谱建了一座只用国产芯片的数据中心
2026-07-22







