OpenAI 推出 GPT-4.1,撞期智谱 Z.ai
本文由 AI科技评论 撰写/授权提供,转载请注明原出处。
以下文章来源于AI科技评论
作者:洪雨欣、梁丙鉴
编辑:陈彩娴
就在今天,OpenAI API 中推出了三个新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。这些模型的性能全面超越 GPT-4o 和 GPT-4o mini,在编码和指令跟踪方面均有显著提升。除此之外,它们还拥有更大的上下文窗口,支持多达 100 万个上下文tokens。
GPT-4.1 在 SWE-bench Verified 上的得分为 54.6% ,比 GPT-4o提高了21.4% ,比 GPT-4.5 提高了 26.6%,使其成为领先的编码模型。
在衡量指令遵循能力的标准当中,GPT-4.1 得分为 38.3%,比 GPT-4o 提高了10.5%。
在 Video-MME 多模态长上下文理解的基准中,GPT-4.1 创造了新的先进成果——在长篇无字幕类别中得分为 72.0%,比 GPT-4o 提高了6.7%。
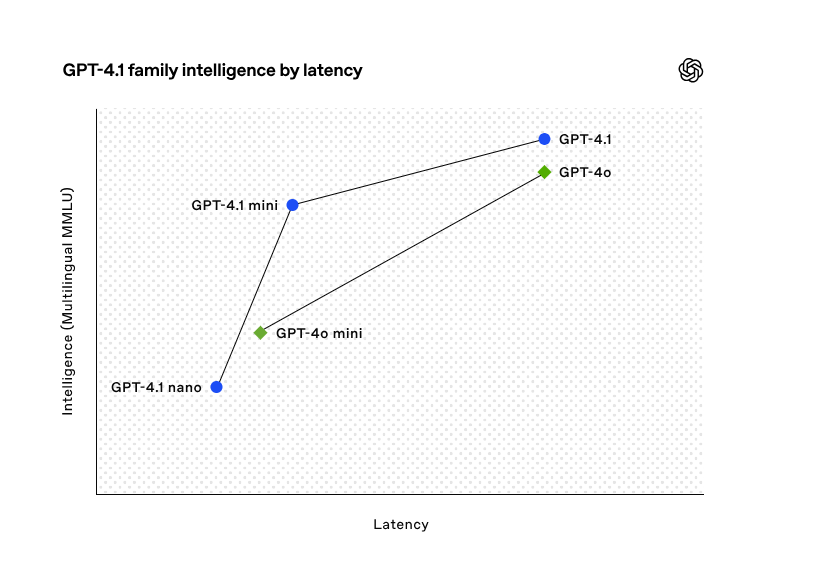
针对模型的优化,GPT-4.1 模型系列以更低的成本提供了卓越的性能。这些模型在延迟曲线的每个点上都实现了性能的提升。
同日,智谱开源了其32B/9B 系列 GLM 模型,在代码生成、指令遵循等方面与GPT4.1短兵相接。
该批模型涵盖基座、推理、沉思模型,现已通过全新平台 Z.ai 免费开放体验,并同步上线智谱 MaaS 平台。
此次开源,OpenAI 和智谱均干劲十足。GPT-4.1 在代码任务、指令遵循、长上下文理解等多项领域均击败 GPT-4o。Z.ai 在指令微调和搜索代码上的基准指标上已接近甚至超越 GPT-4o。
代码生成
GPT-4.1 在各种代码任务上都比 GPT-4o 表现得更好,包括代理解决编码任务、前端编码、减少无关编辑、遵循差异格式、确保一致的工具使用等等。
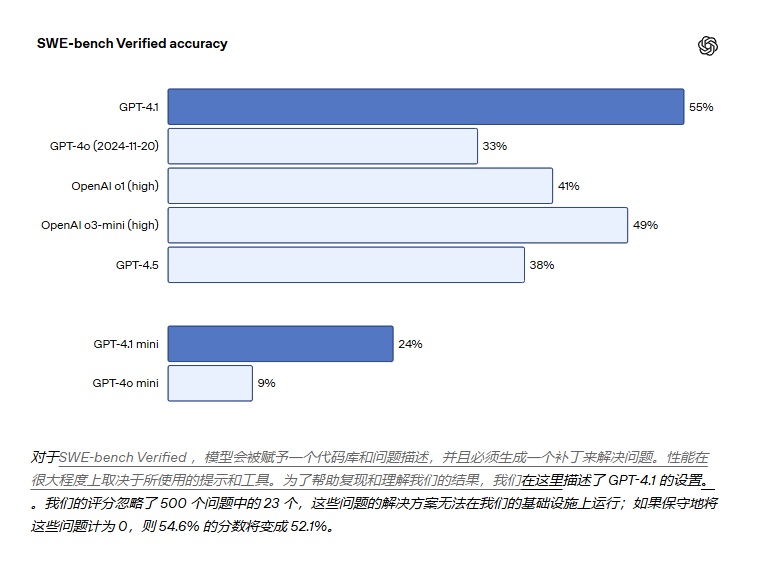
在衡量真实世界软件工程技能的 SWE-bench Verified 测试中,GPT-4.1 完成了 54.6% 的任务,而 GPT-4o 的完成率为 33.2%。这反映了模型在探索代码库、完成任务以及生成可运行并通过测试的代码方面的能力有所提升。
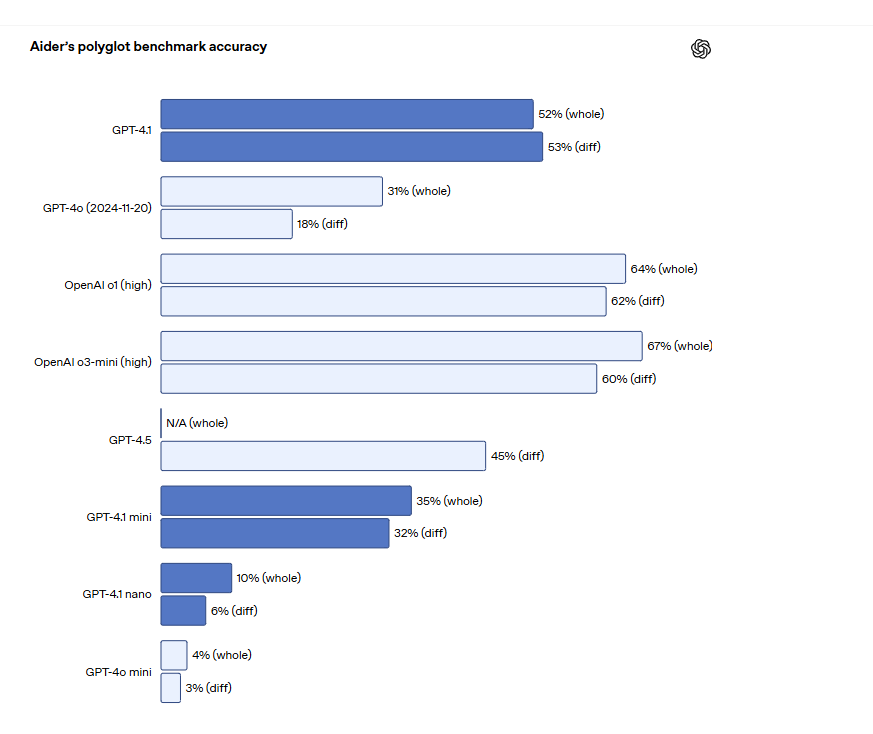
对于需要编辑大型文件的 API 开发者来说,GPT-4.1 在跨多种格式的代码差异分析方面更加准确。在Aider 的多语言差异基准测试中,GPT-4.1 的得分是 GPT-4o 的两倍多,甚至比 GPT-4.5 还高出 8%。OpenAI专门训练了 GPT-4.1遵循差异格式的能力,开发人员无需重写整个文件,从而节省成本和延迟。
GPT-4.1 在前端代码方面也比 GPT-4o 有了显著提升,能够创建功能更强大、更美观的 Web 应用。在我们的面对面对比中,付费人工评分员 80% 的评分结果显示,GPT-4.1 的网站比 GPT-4o 的网站更受欢迎。
除了上述基准测试之外,GPT-4.1 在遵循格式方面表现更佳,准确性更高,并且减少了无关编辑的频率。在OpenAI的内部评估中,代码中的无关编辑从 GPT-4o 的 9% 下降到了 GPT-4.1 的 2%。
指令遵循
OpenAI 开发了一个内部教学跟踪评估系统,将每个类别分为简单、中等和困难提示。GPT-4.1 在困难提示方面的表现尤其优于 GPT-4o。
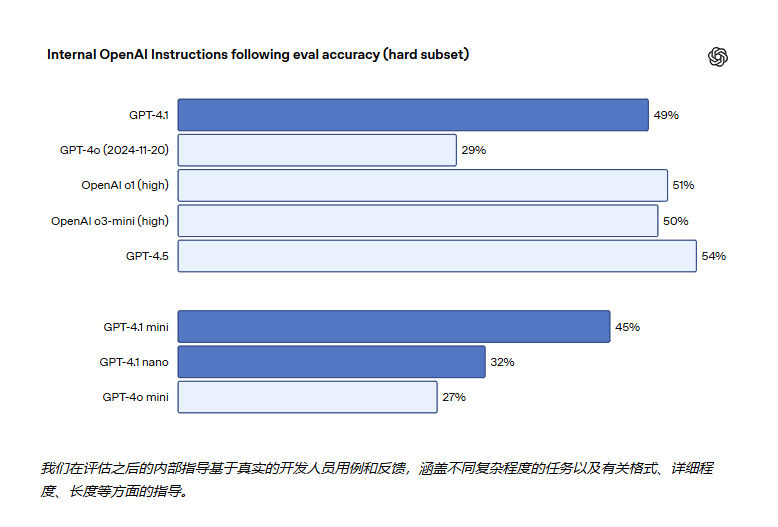
GPT-4.1 能够更好地从过往对话中识别信息,从而实现更自然的对话。在 MultiChallenge 的基准测试中,GPT-4.1 的表现比GPT-4o 提高 10.5%。
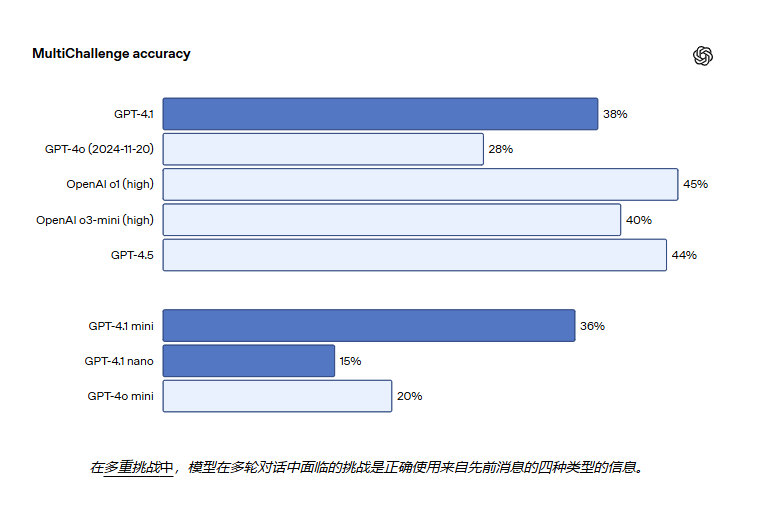
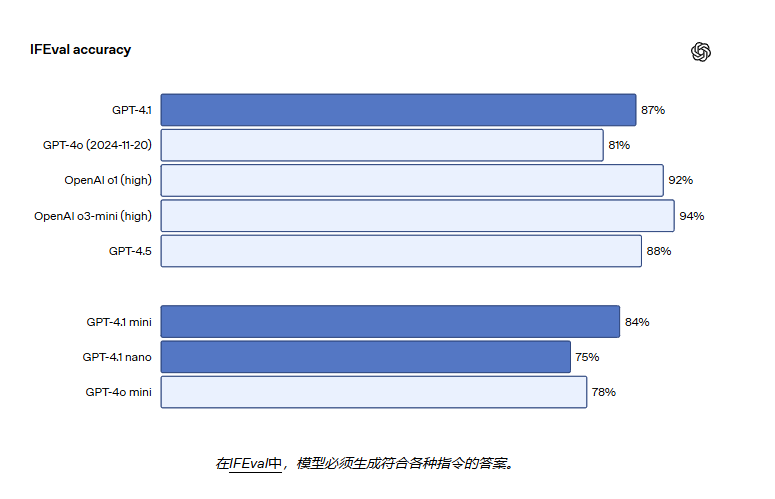
GPT-4.1 在 IFEval 上的得分也为 87.4%,而 GPT-4o 的得分为 81.0%。IFEval 使用带有可验证指令的提示(例如,指定内容长度或避免使用某些术语或格式)。
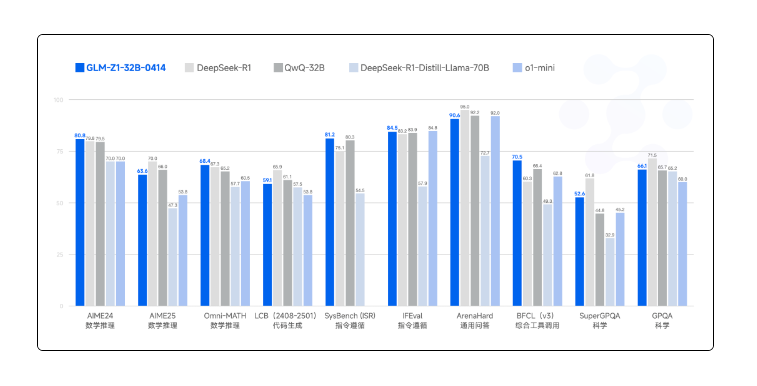
智谱的 GLM-Z1-32B-0414 在 IFEVAL 上也表现优异,以 84.5% 的分数和 GPT o1-mini 分庭抗礼。
长上下文理解
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 最多可以处理 100 万个上下文tokens,而之前的 GPT-4o 型号最多可以处理 128,000 个。100 万个tokens相当于整个 React 代码库的 8 个以上副本,因此长上下文非常适合处理大型代码库或大量长文档。
GPT-4.1 能够准确地处理长达 100 万个上下文中的信息。此外,它能比 GPT-4o 更准确地识别相关文本,并忽略长短上下文中的干扰项。长上下文理解是法律、编码、客户支持以及许多其他领域应用的关键能力。
下图是 GPT-4.1 检索位于上下文窗口内各个位置的隐藏信息(“针”)的能力。GPT-4.1 能够始终如一地准确检索所有位置和所有上下文长度的针,最大检索tokens数可达 100 万个。无论这些tokens在输入中的位置如何,它都能有效地提取与当前任务相关的细节。
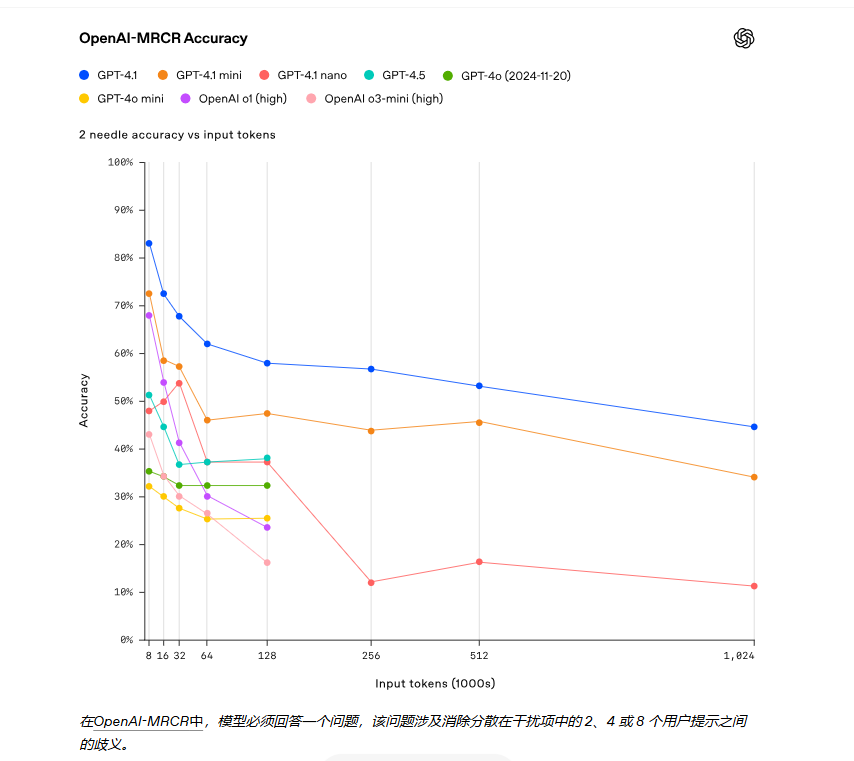
为了进一步展示信息理解的能力,OpenAI 开源了一个新的评估平台:OpenAI-MRCR(多轮共指,上下文中发现并区分隐藏的多个针头的能力)。
GPT-4.1 在上下文长度高达 128K 个 token 时的表现优于 GPT-4o,并且即使长度高达 100 万个 token 时也能保持强劲的性能。
在 Graphwalks (一个用于评估多跳长上下文推理的数据集)的基准测试中,GPT-4.1 达到了 61.7% 的准确率,与 o1 的性能相当,并轻松击败了 GPT-4o。
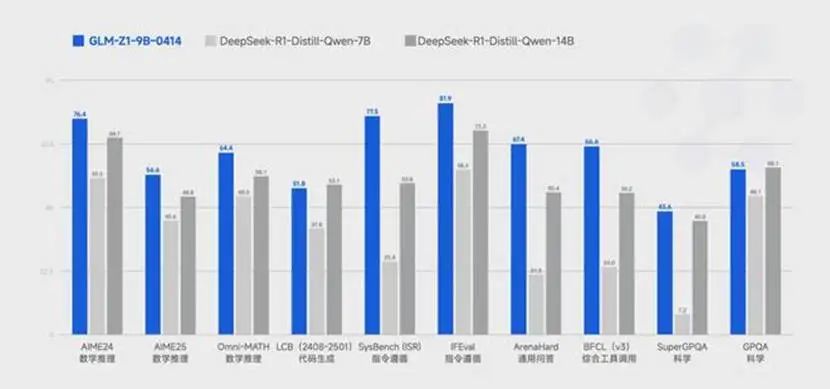
值得注意的是,智谱此番在小模型性能上也有所突破。尺寸仅为 9B 的 GLM-Z1-9B-0414 虽然参数量更少,但在数学推理及通用任务上依然表现出色。在 AIME 的基准测试中,以 76.4% 的高分击败 DeepSeek-R1-Distill-Qwen-7B。
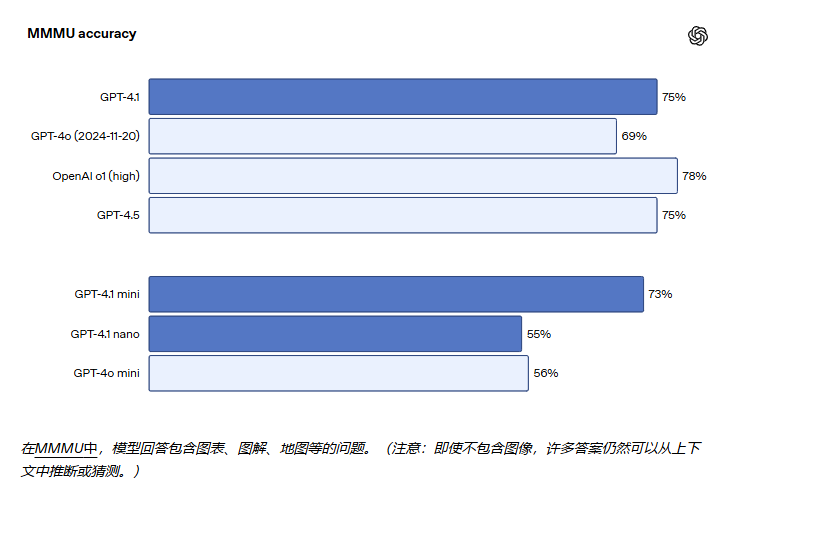
图像理解
GPT-4.1 系列在图像理解方面非常强大,尤其是 GPT-4.1 mini 代表了重大的飞跃,在图像基准测试中经常击败 GPT-4o。
在 Video -MME(长篇无字幕)的测试中,模型会根据 30-60 分钟长的无字幕视频回答多项选择题。GPT-4.1 的表现达到了最佳水平,得分为 72.0%,高于 GPT-4o 的 65.3%。

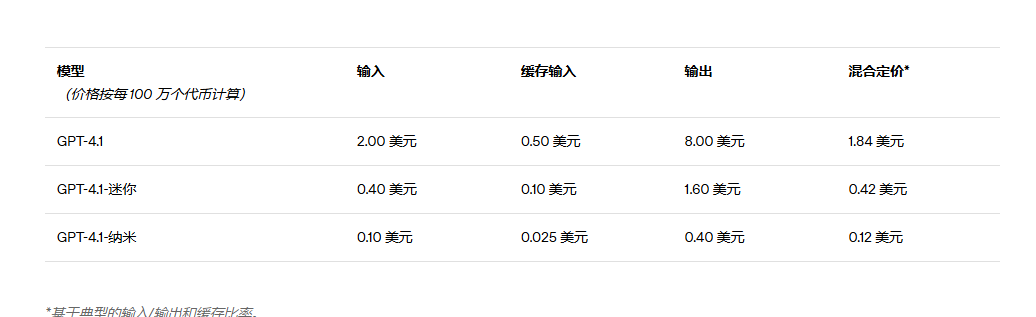
定价
GPT-4.1 的成本比 GPT-4o 低 26%,而 GPT-4.1 nano 是 OpenAI 迄今为止最便宜、速度最快的模型。除了标准per-token 的成本外,还提供了无需额外付费的长上下文请求。
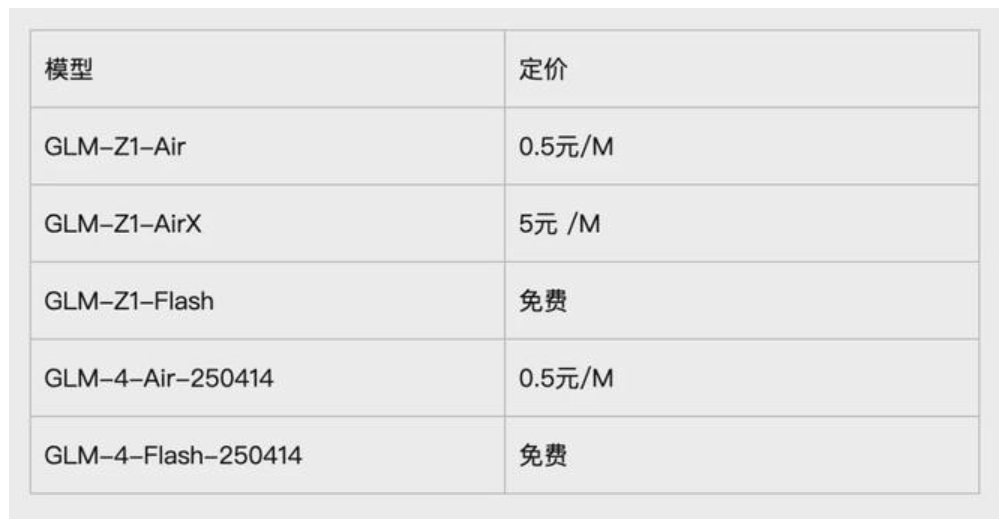
定价方面,智谱 Z.ai 整体低于GPT4.1。本次上线的基座模型提供GLM-4-Air-250414 和 GLM-4-Flash-250414两个版本,其中后者完全免费。推理模型分为三个版本,分别满足不同场景需求:
GLM-Z1-AirX(极速版):定位国内最快推理模型,推理速度可达 200 tokens /秒,比常规快 8 倍;
GLM-Z1-Air(高性价比版):价格仅为 DeepSeek-R1 的 1/30,适合高频调用场景;
GLM-Z1-Flash(免费版):支持免费使用,旨在进一步降低模型使用门槛。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


Claude深夜炸场!放出史上最强“危险级”模型Fable 5,价格太逆天
2026-06-10

vivo、荣耀接连入场,戳破了具身智能的AI叙事
2026-06-10

苹果把Siri交给了Gemini
2026-06-10

普通人怎么读懂Token经济学?
2026-06-11

Kimi年内第3轮融资来了,估值300亿美元
2026-06-11

微信“抢婚”豆包?
2026-06-11

腾讯AI秘密“换船”:元宝失宠,WorkBuddy接棒
2026-06-12

一场「贩卖焦虑」的生意,正在被AI重新定价
2026-06-12