
承认百度仍在AI第一梯队没那么难
本文由 雷峰网 撰写/授权提供,转载请注明原出处。
以下文章来源于雷峰网
作者:董子博
编辑:林觉民
2025 年,百度的“天”变了。
“前 Deepseek 时代”,圈里不少人还悲观地认为,中国没有模型能跟上 GPT 的脚步,对百度来说,模型不掉队,应用生态做起来,就能够留在牌桌上;
而 Deepseek 一出,风云变幻、谁与争锋——原本,文心 4.0 在国内也算数得上号的大模型,在 Deepseek 面前,也不得不甘拜下风。
于是,巨大的压力给到了百度:
发新模型,必然面临质疑,要被拿去在显微镜下和 Deepseek 作比较,在冷眼下遭遇批判;
不发新模型,百度的技术实力更没了展现的机会,无端的猜测又会甚嚣尘上,客户的信心也会被损伤。
进退维谷,百度的选择,是亮出宝剑,非要试一试自己的成色——即使面临批评和贬损,百度也决心放下面子,把自己最新的模型成果展示出来。
放下面子,拼了老命,也死活不下牌桌,百度是怎么想的?
文心 4.5 和 X1,百度“死磕”
谈战略之前,先聊点实着的——百度新发的文心 4.5 和 X1 好用吗?
作为百度新一代的原生多模态大模型,文心 4.5 首先是在多模态的能力上进一步升级。今天的文心 4.5,不仅可以理解照片、工作图表、视频内容,准确摘取静态、动态图像中的细节信息;甚至还能理解网络笑话、梗图中的幽默和讽刺,并连贯地完成推理。
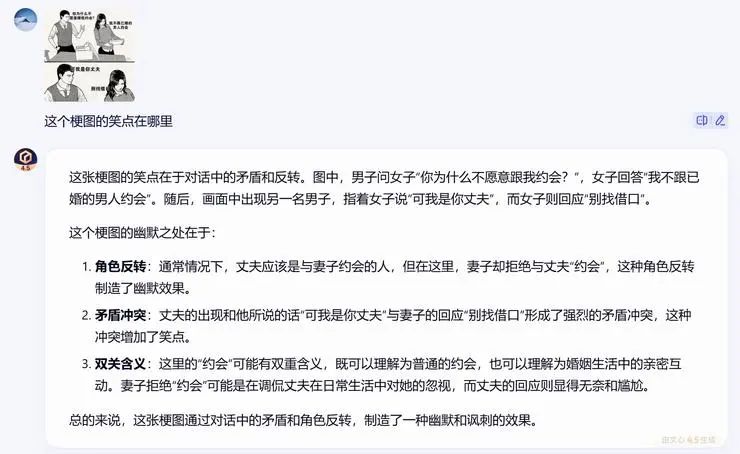
当大模型能力越来越卷、用户标准越来越高,模型之间最细微的差距,就决定了实际生成结果在体验上的天差地别——原生和非原生的区别,也由此显现。
预训练阶段更深层次的模态融合、专为跨模态交互和理解设计的模型机制,都是原生多模态模型的优势。
3 月,李彦宏在人民网上发表了一篇署名文章,其中就提到了原生与非原生多模态大模型的区别——原先,所谓的“多模态模型”,只是几个单模态模型训练后再进行拼接;而原生多模态大模型,胜在以统一的架构,去实现对复杂世界的统一理解。
本次发布的文心 4.5,在原生多模态的角度,思路与谷歌的 Gemini,Meta 的 Llama 4,OpenAI 的 GPT-4o 一致。
而文心 4.5,则是在多模态异构专家扩展技术上更进一步,就如同根据图像、视频、文字等不同领域,给智囊团请来了一群术业有专攻的“专家”,并且通过一套自适应模态感知损失函数,让“专家”们可以实力相当,也就更能完成协作,执行复杂跨模态任务的处理。
多模态能力之外,针对大模型不少老生常谈的技术难关,百度在文心 4.5 也交上了这一期的“答卷”:
面对长文本处理问题和多轮交互,百度优化了 FlashMask 动态注意力掩码,提高了长序列建模能力和训练效率;
针对大模型的学习效率和幻觉问题,文心 4.5 则继续在预训练数据下了苦功夫,通过知识分级采样、数据压缩与融合、稀缺知识点定向合成等技术,百度将数据质量大幅提升,模型的质量和成本也都得到了保障;
而对强化学习效率至关重要的后训练(Post-training)技术,文心 4.5 一样没落下,通过融合多种评价方式,百度将一套自反馈迭代式的后训练技术用到了大模型的后训练当中,将强化学习的稳定性和鲁棒性全面提升,让模型理解人类意图的能力更上一层楼。
对标 GPT-4.5,文心 4.5 已经有了相对亮眼的成绩;而对标 GPT-o1 和 Deepseek R1 的文心 X1,也交出了一份不错的答卷。
据了解,百度文心 X1 采取了递进式的强化学习训练方法,并且基于思维链和行动链根据结果反馈进行了端到端的模型训练,给训练效果增色不少;而 Deepseek 最引人注目的评估系统,百度在文心 X1 上也做了革新,他们建立了一套同意的评估系统,并将多种类型的奖励机制融合,让模型的训练获得了更鲁棒的反馈。
一系列的努力之下,相比文心 4.0,X1 的文本创作能力显然更强,也更擅长梳理逻辑、分析复杂问题、生成观点、提供情绪价值——能和用户聊“思考深的”,也能聊“感情真的”;
而到了多模态的范畴,文心 X1 也没丢了系列由来已久的跨模态能力,在图片理解的精准度更上一层楼,还能细节识别图片是否有 P 图痕迹,兼具一副火眼金睛。
相比 Deepseek,刚刚面世的文心 X1 测试下来,在文本的创意和个性化上稍逊一筹。但除了前者所不具备的多模态能力之外,文心 X1 更大的优势在于“家底厚”——文心大家族支持的“高级搜索”“文档问答”“AI绘图”“TreeMind树图”“百度学术检索”等等工具,都能在文心 X1 上用到,让用户获得沉浸的一站式 AI 体验。
在能力上来说,两款模型在文心 4.0 的基础上又实现了一次“飞升”;而在成本上,文心 4.5 和 X1 却再次“跳水”,依靠芯片、模型、框架等层面的联合优化,文心 4.5 的推理成本只有 GPT-4.5 的 1%,而 X1 的推理成本也只是 Deepseek R1 的一半左右。
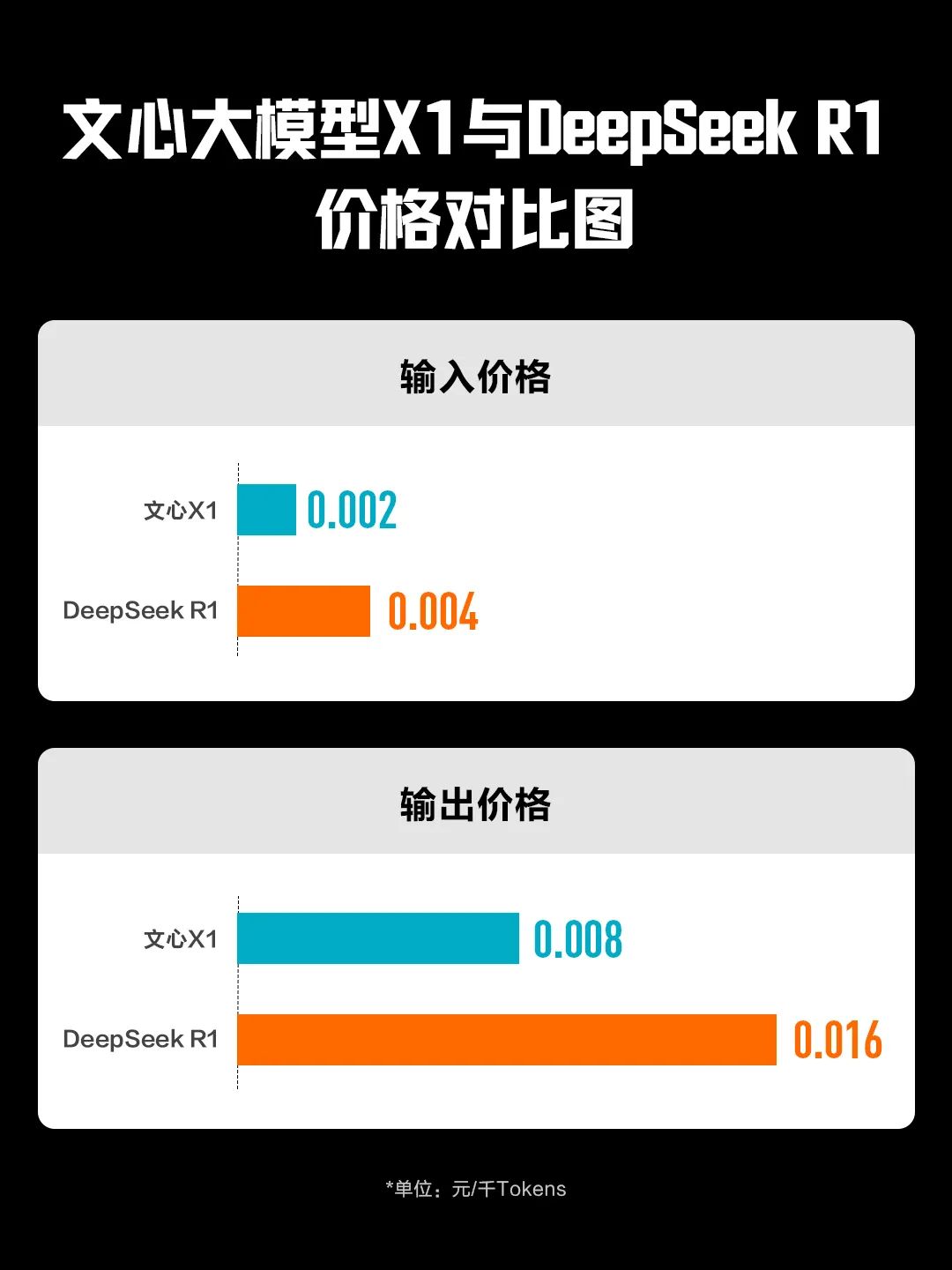
成本优势建立了起来,如何让用户更便宜地把大模型用起来,百度就有了底气:
今天,文心 4.5 和 X1 都已在文心一言官网上线,免费向用户开放;
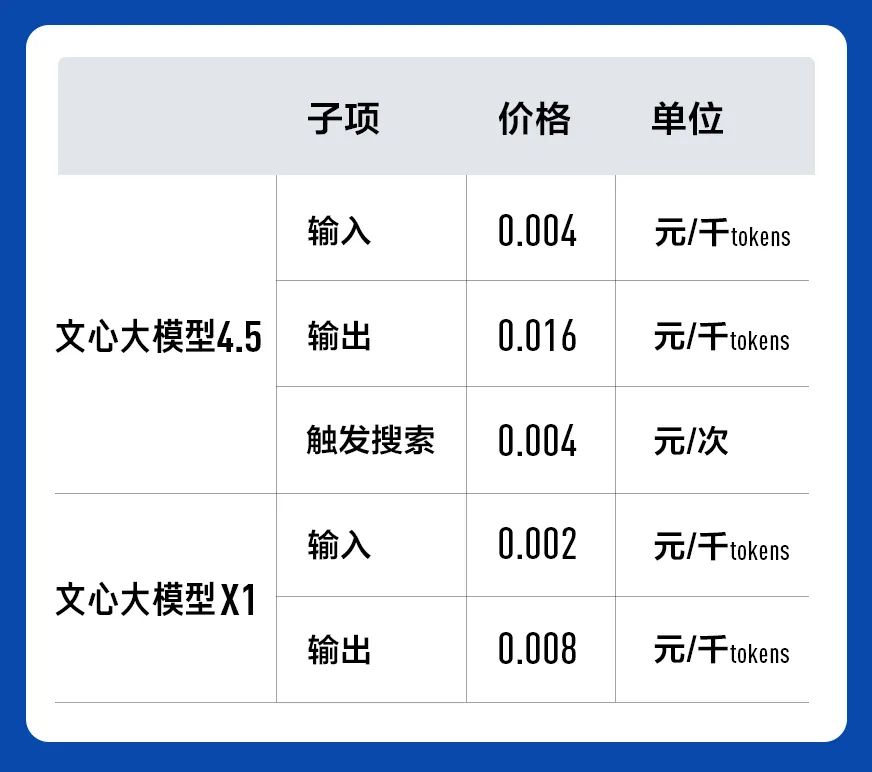
面对企业用户和开发者,文心 4.5 已在百度智能云千帆大模型平台上,输入价格为0.004元/千tokens,输出0.016元/千tokens,约为GPT4.5价格的1%;文心X1定价为输入0.002元/千tokens,输出0.008元/千tokens,也即将上线千帆。
百度搜索、文小言等百度的当家产品,也正在逐步接入文心 4.5 和 X1,把最强大的 AI 能力让社会普惠。
近十年,百度的累计研发投入,已经超过 1800 亿,李彦宏在今年 1 月的 25 周年全员信中写道,很多年里,百度收入的 20% 以上,都被投入到了研发当中——这么看,文心 4.5 和 X1 的迭代速度虽然在“意料之外”,但也算是高投入之下的“情理之中”。
然而,这次文心的双料发布,却远不止是新技术迭代这么简单——百度鲜有地放下面子,用诚实的姿态,把自己的优点和缺点暴露在用户的眼皮底下,究竟图点什么?
百度变了
像开头说的一样,当下这个时点,在 Deepseek 占领了无数圈内外用户心智的当口,从市场角度看,百度发布文心 4.5 和 X1 是一个正确的选择吗?
一样的困境,整整两年前,在面对 OpenAI 和 ChatGPT 时,百度就已经经历过了一次。
当时,是李彦宏许久之后首次出席线下会议演讲,还是熟悉的白衬衣、熟悉的不紧不慢的语调。甫一开场,他并没盯着提词器里的讲稿,比起“早有预谋”的台词,更像有感而发的感叹,犀利地抛出了一个问题:
“最近一段时间,很多朋友问我:‘为什么是今天,你们真的 ready 了吗?’”
与其说这个问题问的是别人,不如说,这个问题李彦宏或许也问了自己很多遍。但思前想后,百度不怕被与 OpenAI 比较,也不怕丢面子,有好东西,必须得让客户和用户先用上。
两年后,文心 4.5 和 X1 发布,百度更是必须保证更新频率,缺乏旗舰模型的公司,留在 AI 的第一梯队也难以服众。
今天,百度变了,变得不再爱面子:
先前站队闭源,Deepseek 通过开源尝到了甜头,那就闻过则喜、从善如流;
Deepseek、Llama 等模型确实各有千秋,那就践行“拿来主义”、在搜索、地图、文库、智能云等 ToC、To B 产品体系里海纳百川,让用户自主选择;
在未来,智能体和 AI 应用,没法被一家公司大包大揽,那百度就甘当绿叶,不做“超级应用”,而要帮助人们打造更多“超级有用”的应用;
过去做事慢条斯理、贻误军机,今天在内部,文心 4.5 全面免费,PC、移动双端直接上现货,等等决策都在半天之内完成,绝不拖泥带水;
而体现在迭代速度上,百度模型迭代的速度仍在加快,文心 4.5 全部开放之后,最晚 6 月底就将公布开源版本,下半年则有望见到文心 5.0 的面世。
百度变得不爱面子,也变得越来越开放、越来越务实——不躺平,也不苟着。
在今年的“世界政府峰会”WGS 访谈时,李彦宏提到:“我认为创新不能被计划,你不知道创新何时到来,你所能做的就是营造一个有利于创新的环境。”
枕戈待旦,百度还在谦卑地等着一个机会。但在今天,即使面临着诸多强敌的挑战,百度还在大模型的第一梯队吗?
百度,没下牌桌
今天,评价所谓“第一梯队”的 AI 公司,或许还并不能存在一个共识性的标准。
几个顶流 AI 玩家,更像八仙过海,有些以技术见长,有些重视产品,还有些则干脆专注市场营销,各有各的优势,也各有各的活法。
如果把百度算进第一梯队的 AI 公司当中,或许有人基于一贯的刻板印象,并不会同意;
然而,数据是直接、有力的,百度在中国的 AI 商业化实践,的确可以名列前茅——2024年,文心大模型的日均调用量已经达到了 16.5 亿次,相比一年前的同期数据,狂增33倍;飞桨平台上,1808 万个开发者和 43 万家企业,已经创建了 101 万个模型;而文心千帆已经帮助客户完成了 3.3 万个模型的精调、开发了 77 万个企业应用。
巨大的 B、C 端使用量,已经帮助百度建立起了一个初具动能的用户飞轮。同时,每天不停运转的百度搜索、近亿 AI 用户的百度文库,以及地图、网盘等多款亿级用户产品,都是百度内部试验 AI 效能提升的试验田,肩负的不仅是百度这家科技公司的技术未来,更是这家上市公司的商业未来。
过去 24 个月里,AI 行业中大的变化,李彦宏说,是“大模型基本消除了幻觉”,这也让用户们可以更放心地使用 AI,而不担心遭到幻觉的反噬——这也是大模型推向商业化的必要条件。
而到了 2025,不同公司的生存策略正逐渐趋同:独角兽们为了满足资本的期待,而必须展现自己的盈利能力;而大厂更是如此,要依靠持续不断的现金业务支撑营收和财报,这样股价才能有所保障。
而 Deepseek 面世后,看似通过先进的技术力“杀死了比赛”,其实整个 AI 大行业反而有了向好的趋势。
一方面,Deepseek 的确通过开源,救活了一些基础模型能力较差的公司和产品,让他们也能通过接入 Deepseek 的方式,获得一些流量;
另一方面,Deepseek 在国内突然爆炸式的营销,让不少企业单位——尤其是国央企、事业单位——一改之前对 AI 的谨慎态度,纷纷加速拥抱 AI,让本地部署的一体机生意在近期反而增色不少。
于是,李彦宏在今年的首次内部讲话中,他提到,加大 AI 应用商业化实践同样相当重要。AI 应用在全行业的爆发,只会加速玩家的淘汰,而那些缺乏商业化能力的公司和产品,恐怕更要遭殃。
早在别人大谈 AGI 时,百度就很早提出要在商业化落地上取得成绩,要通过 AI 业务给自己造血,丝毫没有行业“前辈”的“偶像包袱”——翻译过来就是:“赚钱,不寒掺。”
百度的商业化保证,是其作为一个25年大厂日积月累的庞大矩阵。百度底层有芯片,有智算中心、万卡集群;中间有模型,有模型精调、APP 开发工具链、有大模型商店;顶层有自己的原生 AI 产品,有亟待重构的老牌大 DAU 产品,有丰富的渠道和颇具深度的用户池子——中间不少要素,即使是同等量级的大厂也难望项背。
今天,百度还带着两款技术更先进,免费的文心大模型前来挑战,而还很少有人知道,百度文心 5.0 的底牌究竟长什么样子。
能留在牌桌上,百度的底牌,是它独特的生态位,是它巨大的体量和它平台型、生态型公司的特点,让它可以与整个大赛道与有荣焉。
结语
相比两年前,AI 大模型的赛道,变化其实没有那么大。
诚然,技术在日新月异地进步,玩家们来了又走,七百多天里,赛道经历了百端待举,也经历了“群模乱舞”。今天市场重回理性,Deepseek 又强势入局,颇有一扫六合之势;Manus 又以智能体作为切口,让人们对 AI 产生了新的遐想。
但未曾改变的是,AI 的方向仍然被一群人引领着。他们兼具浪漫主义与实干家精神,技术头脑与商业眼光,让他们能够一直目光如炬,照亮自己,也同样照亮他人的前路。
今天的百度亦属于这个行伍,他们是天生的挑战者,挑战更强的对手,挑战更复杂的技术,挑战昨天的自己。
当心中有梦的时候,面子又算得了什么呢?


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群

什么!ChatGPT也要刷脸实名认证了?
2026-06-18

突发!Anthropic即将启用实名制刷脸
2026-06-15

一边裁员承压,一边半年狂赚数亿,AI短剧到底谁在赚钱?
2026-06-16

OpenAI 被传要终止 IPO?
2026-06-15

独家解读丨SpaceX今晚IPO,华尔街为何却吵翻了天?
2026-06-15

灵光走独木桥
2026-06-16

人形机器人,汽车产业的新故事
2026-06-15

散户人均赚3.8万,韩国怎么就成了AI最大赌场?
2026-06-16





