
万亿美元大饼背后,英伟达也开始焦虑了
本文由 数智前线 撰写/授权提供,转载请注明原出处。
以下文章来源于:数智前线
作者:任晓渔、周享玥
“到 2027 年,市场对 Blackwell 和 Vera Rubin 系统的订单需求将带来至少 1 万亿美元的营收。”
又到一年 GTC。今年的“科技春晚”上,身着皮衣的老黄又发了新的“核弹”,同时也带来了一个前所未有的爆炸性业绩预测。这个惊人的数字,延续了黄仁勋一贯的对 AI 时代基础设施持续增长的乐观和信心,也是在向市场宣告英伟达的增长故事远未结束。
但资本市场的反应略显冷淡。英伟达股价应声跳涨 4.3% 后又下跌,最终收涨 1.2%。前所未有的业绩预测,并没有催化成市场的热情。
症结在于,在正在爆发的推理算力市场上,游戏规则正在起变化。低延迟、高能效比和应用成本正取代高性能、高吞吐、大内存、高带宽等指标,成为主导算力市场的核心因素。
结构性巨变下,过去三年里统治 AI 算力的绝对王者——英伟达,正在遭遇前所未有的离心力。除了传统芯片厂商,英伟达的一众传统大客户如亚马逊、Meta 甚至 OpenAI 都在加速自研芯片进程。同时,中国市场是推理需求的大户,目前国产算力的推理成本也极具竞争力。
为应对前所未有的推理焦虑,英伟达在今年 GTC 大会发布了一系列新品来适应推理需求,并用 AI 工厂的叙事来重塑自身护城河。不过,当下外界仍然在观察和观望这些动向的效果。
可以想见的是,这场围绕着护城河和壁垒的保护战,才刚刚打响。
推理时代的“离心”焦虑
英伟达正遭遇一场巨大的“离心运动”。多路玩家争抢推理市场形成强大外向拉力,正冲击这家巨头在训练市场的统治力。
源头在于,AI 产业正在发生巨变,推理市场正超越训练市场,成为 AI 算力的主战场。
正如老黄自己在今年的 GTC 大会演讲中的断言,“推理拐点已至”。这是一个正在爆发中的巨大市场。IDC 预测,到 2027 年,中国推理算力占整体算力的比例将突破 70%,在全球市场,智能体使用量将增长 10 倍,推理需求将增长 1000 倍。Deloitte 也在一份报告中指出,2026 年推理工作负载已占全部 AI 算力三分之二,而 2023 年的三分之一到 2025 年的一半,实现了快速跃升。
但这个高潜爆发市场,推理任务对算力的要求与训练阶段存在根本性差异。
RISC 架构奠基人 David Patterson 与 Google DeepMind 高级工程师马晓宇今年年初在一篇论文中提到,训练阶段需要大规模并行计算来处理海量数据。如单次 GPT-4 级别的训练需要 25,000 张 A100 GPU 连续运行 90 天,是比拼峰值算力与资金的“军备竞赛”。
但推理阶段的逻辑完全不同,它本质是顺序化的自回归过程,每次只能生成一个 token,模型参数需要频繁从 GPU 显存加载到计算单元,可用内存带宽才是 token 生成速度的决定因素,这使得内存带宽和端到端延迟成为核心瓶颈。
另外,在成本结构上,训练时代是“一次性爆发”模式,推理则是持续性失血。每天数十亿次请求下,AI 应用厂商们会十分重视成本控制,“每瓦特每美元的 token 产出”关乎 AI 应用的落地。
针对内存带宽和端到端延迟及成本功耗问题,业界有共识,定制芯片可以针对特定任务做优化,相比通用 GPU 有更好的表现。
目前,有多股力量都在进军推理算力市场。

传统的芯片厂商们如 AMD 和 Intel都没有缺席,它们早已看中了推理市场的结构性增长机会。其中,AMD 凭借 MI350 系列(含 MI355X)的强大内存和推理性能,在总拥有成本上形成优势。权威供应链统计显示,Meta 在 2025 年已采购 17.3 万片 MI300 系列芯片(后续将大规模转向 MI350),微软采购 9.6 万片。Oracle 也有最多部署 13.1 万颗 MI355X 的大单承诺。同时,Intel 的 Gaudi 3 加速器正在企业级和云端推理市场快速突围。
头部云厂商此前是英伟达数据中心业务的主要收入贡献者,但在成本控制与供应链自主的考量下,正大力开启芯片自研动作。对这些大厂而言,在每天数十亿次推理请求的庞大规模下,自研成本更低的定制芯片不仅能每年节省数十亿美元,还能带来关键的供应链灵活性。
目前,从谷歌到亚马逊都已与博通深度合作,完成推理芯片的设计和量产。谷歌的 TPU 经过多次迭代,已获得 Anthropic(部署超 100 万颗)和 Meta(2026 年 2 月签署数十亿美元多年期租用协议)的订单。而亚马逊的 Trainium 获得 OpenAI 2GW 容量的订单,Anthropic 也向 Amazon 伸出了橄榄枝。Meta 自研的 MTIA 系列(含 MTIA 300 及后续版本)已部署数十万颗芯片,全面支撑全平台推荐系统推理。
与此同时,一些专业化推理芯片公司也在加速发力这一市场。例如已被英伟达 2025 年底收购整合的 Groq,其 LPU 因首t oken 延迟远低于 GPU 及定价更低等因素,在 2025 年曾吸引大量开发者与企业尝试。
除了这些对手,中国作为推理市场大客户,国内的推理算力生态也在崛起。业界观察到,目前国内已经从华为一家演化为百花齐放局面,市面上壁仞的推理专用芯片极具成本优势,沐曦、摩尔线程等厂商都已经在 AI 智能体企业圈内大受推荐。
多路对手围攻之下,市场调研机构认为,AI 服务器市场将从英伟达“一家独大”走向“多元化竞争”。XPU(既非 GPU 也非 CPU 的专用加速器)的增长率将超过 GPU。科技分析机构 byteiota 综合分析师观点甚至指出,到 2028 年英伟达在推理市场份额将从 80% 大幅下降,被 ASIC 蚕食 70~75% 的生产推理工作负载。
“推理领域没有 CUDA 护城河(There is no CUDA moat in inference)。”华尔街日报日前报道过新兴芯片厂商 Cerebras Systems 的 CEO Andrew Feldman 的看法。某种程度上这可能也是英伟达当下最大的焦虑来源。
剑指万亿市场,英伟达的护城河守卫战
不过同时,英伟达也采取了一系列动作和举措来应对推理时代挑战。GTC 大会上,无论是老黄的演讲内容还是一系列新品和动作,都展示了英伟达对推理时代的野心。
两个多小时的演讲中,有人统计过,“训练(training)”被提到仅 10 余次,“推理(inference)”一词则出现了将近 40 次。
他还用一万亿美金营收预测数据,来向外界表明,英伟达在推理时代将继续保持存在感——
“去年此时我提到过,到 2026 年,Blackwell 和 Rubin 的需求规模有望达到 5000 亿美元。今天,我想告诉大家:站在这里,到 2027 年,我们看到的高确定性需求,至少已经是一万亿美元级别。而且我相信,真实需求还会更高”。
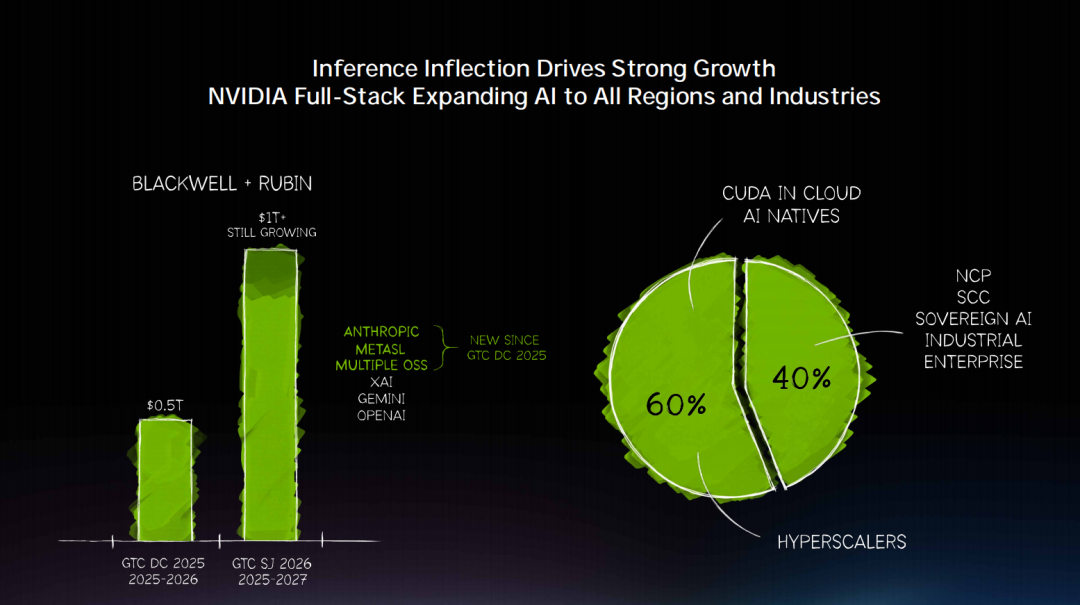
而这背后,老黄提到从 2025 年开始,英伟达就在全力押注推理能力,确保英伟达不仅擅长训练,也擅长训练后、擅长推理、擅长整个 AI 生命周期。
本次大会,英伟达展示了英伟达应对推理时代挑战的完整战略布局,黄仁勋将推理过程拆解为“prefill”(预填充)和“decode”(解码)两个截然不同的阶段,并为每个阶段配备专门优化的硬件架构。
有人点评这是在通过对推理计算的本质重新定义,来夺回英伟达在推理时代的话语权。
新一代旗舰 GPU——Vera Rubin GPU,专门负责“prefill”(预填充)阶段,推理性能相比上一代提升3.3~5 倍,能将用户请求转化为 token。
Groq 3 LPX 的加入,被视为英伟达补齐低时延推理短板的关键一步。2025 年 12 月,英伟达斥资 200 亿美元,通过非传统收购整合了 Groq 的低延迟推理技术及核心团队,这笔交易成为其历史上规模最大的一笔。Groq 主打极致低延迟与性能确定性,其创始人 Jonathan Ross 是谷歌 TPU 的关键推手。
Groq 3 LPU 也是双方合作后的首款产品,由三星代工,预计 2026 年 Q3 出货。这是一款专为 decode 阶段设计的芯片,它绕开了传统GPU的HBM内存瓶颈,首token延迟低于0.1毫秒,推理性能提升达 35 倍。黄仁勋还表示“GPU 负责 prefill、LPU 负责 decode”的分工是推理时代的最优架构。
智能体时代到来,英伟达还专为智能体工作流设计打造了全新 CPU——Vera CPU,采用常用于手机、平板等的 LPDDR5 低功耗内存,将定位从通用算力处理器转向智能体任务调度员,不再盲目堆砌内存带宽,而是以更低功耗实现数据高效、精准调度。黄仁勋称,其性能是全球主流 CPU 的两倍,将是一项价值数十亿美元级的业务,“我们从未想过会单独销售 CPU,但现在确实卖得很多。”
由此,英伟达也打破了通用 GPU 打天下的叙事,转向了场景化分工。目前,整套系统中形成了分工三角:GPU 负责重计算,CPU 负责调度编排,LPU 负责极速输出。再配合英伟达自研的 Dynamo 调度软件,可灵活应对不同 AI 任务对成本、延迟和吞吐量的复杂要求,在高价值 Token 生成场景中,每兆瓦 Token 吞吐量较上一代 Blackwell 提升 35 倍。
黄仁勋还进一步给出部署建议:高吞吐负载可 100% 使用 Vera Rubin;编码、高价值工程类 Token 生成负载,可配置 25%Groq 与 75%Vera Rubin 的组合。

除了软硬件层面的发布,英伟达还构建了一个新的叙事,“AI 工厂”——
“我们不是单独优化芯片,而是在做极端协同设计:芯片、系统、网络、软件、算法、部署方式,全栈协同。未来,所有云服务商、AI 公司和大型企业,都会像今天研究制造业产线一样,研究自己的 token 工厂效率。因为数据中心已经不再只是‘存放文件的地方’,而是一个生产 token 的工厂。token,正在成为新的商品;而 AI 计算,正在变成新的收入来源。”
这套叙事下,竞争不再是单一的芯片维度,而是包含了从芯片到液冷机架到网络互联和 AI 工厂操作系统,英伟达占据了从能源、芯片、基础设施到模型的多个层级,客户能“一站式”获得训练+推理全生命周期的最优成本。黄仁勋还阐述“Token 工厂经济学”,强调“每瓦特每美元的 token 产出”这一全新衡量标准。
外界认为,英伟达正通过一整套交付模式,用系统优势来用抹平单一维度的成本优势,从而应对推理市场竞争。
2026 年 GTC,英伟达仍然是 AI 算力市场的主导者,不过它也正进入一场防御性战事的开场。这场推理保卫战,也是新时代的生存和主导权之战,一切才刚刚开始。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


智谱首破5000亿!六小虎与DeepSeek千亿估值竞赛,谁的拳头最硬?
2026-05-20

“出走”阿里两个月,林俊旸一出手就是20亿美金
2026-05-19

即梦和可灵,能不能接住AI短剧风口?
2026-05-19

FA眼中的AI人才战:2000投资人蹲路演,700万年薪抢应届生
2026-05-19

排名第九、国内第二,DeepSeek V4 凭什么让人又爱又恨?
2026-05-20

Google I/O杀疯了:视频大模型超炸裂,音频眼镜登台,Gemini接管一切
2026-05-20

为什么说 Anthropic 像一家「宗教」?
2026-05-21

解决一个“小bug”,这款AI社交产品MAU半年上涨6倍?
2026-05-21






