
“吉卜力风”免费版来了!豆包这款AI生图神器,不比GPT弱?
本文由 智能Pro 撰写/授权提供,转载请注明原出处。
以下文章来源于:智能Pro
作者:三明治
最近两周,“吉卜力画风”突然就火了。
事情的开始是这样的,3 月 26 日,OpenAI 推出了基于 GPT-4o 多模态大模型的高精度图像生成功能“4o Image Generation”,按照他们的说法,现在用户只需一句简单的文字描述,就能实现精美的广告或平面图的制作、应用界面的UI设计、LOGO 或图片风格的切换等等。
结果呢?整个互联网的人,都在用它变身“赛博宫崎骏”。
不开玩笑,小雷是真被这玩意给刷屏了,这两天一打开群聊,就能看到无法无天的群友们在拿 GPT-4o 疯狂整活,有做头像的,有做表情包的,甚至还有把“黄 O 大道东”变成吉卜力画风的,推特上的国外网友玩得更是乐此不疲,看得我都有点心痒痒的。

(图源:X)
幸好,类似的功能,国内大模型并不是没有。
比如说字节跳动的 SeedEdit,同样可以实现“自然语意修图”,用户只需输入简单的自然语言,便可对图像进行多样化编辑操作。
最重要的是,这功能可不需要你想方设法翻出去用,在字节跳动的豆包官网就直接能用,而且目前豆包的“图像生成”功能是完全免费且不存在限制的,这一波甚至能把开会员的钱也给直接省下来。
话不说多,我们这边直接开整!
豆包这款产品,让人人都是宫崎骏
想体验这个功能的话,其实还蛮简单的就是了。
打开豆包网页版,在输入框下面就有「图片生成」,应该就能看到上传参考图的选项了,这里就是 SeedEdit 模型的入口。
要做的事情很简单,上传图片,然后输入我们想要改变的内容。

(图源:雷科技)
话不多说,先来看图。
首先,小雷这边选用了一张来自知名音乐录像带里的截图,让豆包和最近巨火的 GPT-4o 都试着“帮我换成吉卜力风格”。
这是原图:

(图源:Youtube)
这是豆包的成品:

(图源:豆包)
这是 GPT-4o 的成品:

(图源:GPT)
对比下来,GPT-4o 的衣服还原度更高,手部没有变形,只是没有维持原图比例;豆包虽然整体构图、配色更加贴近原图,但是衣服有些微变化,手部有些变形,甚至多了一只抓着麦克风的手。
接着试一下大家都关心的名人,比如说马斯克:

(图源:豆包)
比方说乔布斯:

(图源:豆包)
再给乔布斯换个迪士尼风格:

(图源:豆包)
从结果来看,豆包的转换效果可以说是非常成熟。
最后,我们试一试影视剧集里的名场面,这次就拿《和平使者》里面约翰·塞纳饰演的克里斯多福·史密斯的名场面做例子:

(原图,图源:HBO Max)

(图源:豆包)

(图源:GPT)
这次差距其实更加明显一些,GPT-4o 甚至把金属头盔保留了下来,身边的两名角色也做到了精准的画风转制,但是图片比例有所修改,文字信息也没有保留下来。
作为对比,豆包则是试图在整幅画面上进行对齐,然而人数一多起来,角色的服装和样子就没多少能对上的。
但是,接着我就要说但是了,豆包的效果还是比 Gemini 2.0 要强上一大截的,谷歌这玩意虽然支持自然语意修图,但是既不懂吉卜力风格是啥意思,也搞不清楚怎么修改图片比例。

(图源:Gemini 2.0)
可恶的谷歌,不要给我看这一堆不知所谓的东西!
其实把思路反过来,把画改成真实风格,豆包搞得也不错,我上传了一张刻在不少人基因里的 Meme 图片,让它以此为原型,生成一张真实照片。
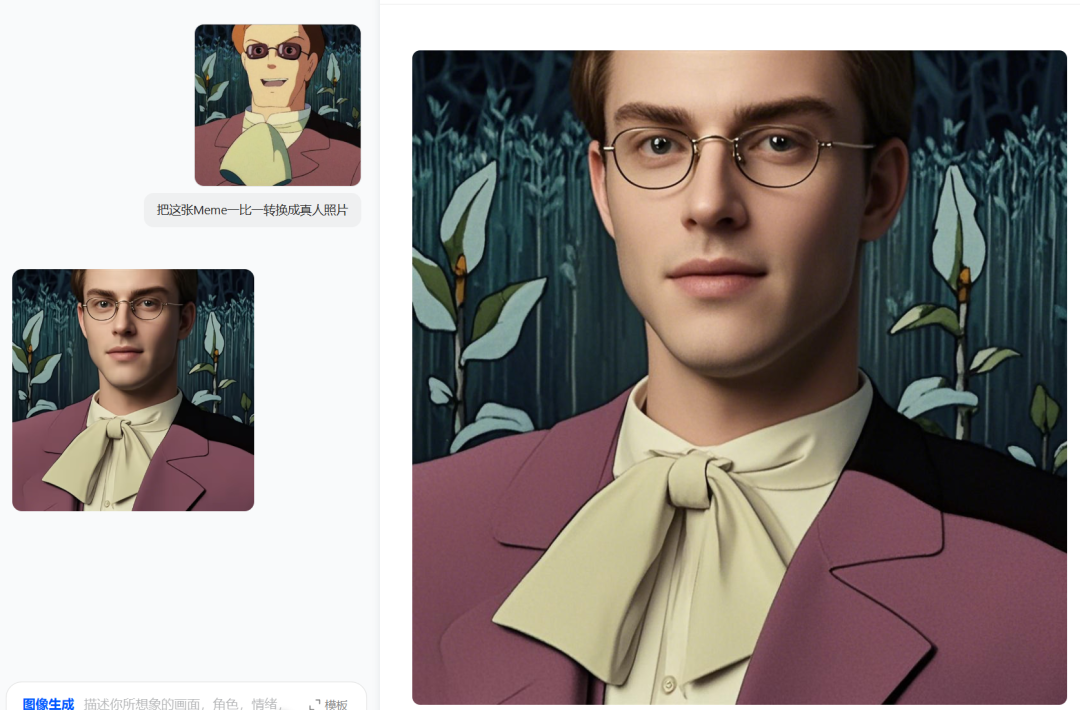
(图源:豆包)
嗯...只能说像是挺像的,就是没了那种冲击感。
如果再简单调整一下的话,就能做出下面这种效果:

(图源:豆包)
虽说脸型有点不对,笑得也是有点狰狞,但是这种打破次元壁的做法,还真就只有 AI 大模型能够实现。
豆包图片处理能力在线,
但仍有较大改进空间
不过,人人都在用吉卜力画风,也带来了新一轮的版权问题。
毕竟早在 2016 年,宫崎骏评价 AI 动画技术时就直言:这是对生命本身的侮辱。
宫崎骏反对用技术代替手工创作,他认为 AI 生成图像缺乏对生命力的敬畏,而在 2025 年的今天,技术力的进步,反而让大家对这件事情变得更肆无忌惮了起来,确实是有点讽刺的。

(图源:Youtube)
既然如此,我们不妨转换一下思路,把它当成 PS 来用?
比如在设计行业里源远流长的梗,“让大象转个身”这种要求,我们在豆包上能不能实现呢?

答案是“完全可以,轻易可以”。
可以看到,SeedEdit 生成的大象背面是非常合乎逻辑的,耳朵的形状、脚部的位置、身体的颜色都做得相当不错,周围的环境也保持了高度的一致,很难看出画面上有什么破绽。
不过类似海报的效果,豆包就做得不咋样了,和 GPT-4o 可以说一眼就能看出差别了。

(图源:豆包)

(图源:GPT)
只能说,豆包在审美这块,还真有挺多要学的地方。
最后,我也试了一下豆包凭空进行“图片生成”的效果。
提示词如下:
一位年轻的印度女性,黑发扎着敞开的马尾辫,身穿黑色夹克,站在大学校园里,直视着镜头。该图像具有 1990 年代风格的电影静态美学,在阳光明媚的日子里拍下的特写肖像。

(图源:雷科技)
对比豆包,GPT-4o 产出的图更有特写感;Midjourney V7 产出的图片光线更加自然,人物脸部的肤色也相对更加清晰,细节更加丰富,画面焦点更加清晰,但总的来说,三者都没啥肉眼可见的问题。
AI 修图,爆发在即
不可否认,如今 AI 大模型在“绘画”上足以独当一面了。
但是在图像编辑领域,AI 大模型依然是相对落后的,无法进行精准编辑一直是行业的老大难问题。
前些年,这类需求一般可以通过 Stable Diffusion 的 ControlNet 插件来实现。
它可以获取额外的输入图像,通过不同的预处理器转换为控制图,进而作为 Stable Diffusion 扩散的额外条件,只需使用文本提示词,就可以在保持图像主体特征的前提下任意修改图像细节。
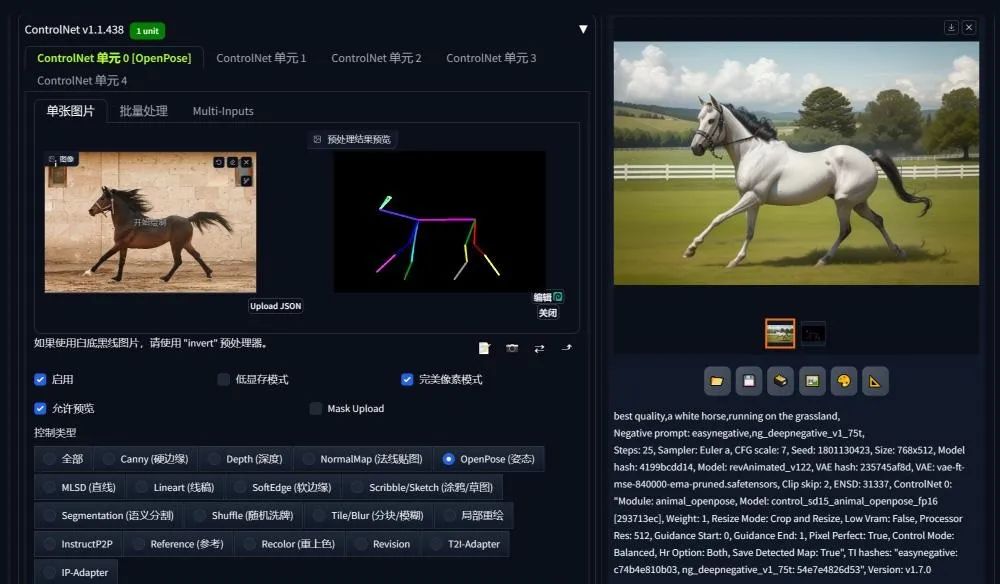
(图源:新浪微博,识别特征并进行重新绘制)
然而本地部署 AI 应用这事,和大部分小白是基本无缘的。
所以在进入今年后,包括 GPT-4o、Gemini 2、Midjourney V7 等先后上线了通过自然语意修图的功能。
个人认为,这种只需给定输入图像和告诉模型要做什么的文本描述,然后模型就能遵循描述指令来编辑图像的功能,甚至可以被视为重大突破,曾经被视为必备技能的 PS,如今似乎陷入了“可学可不学”的微妙处境。
当然了,目前这类模型在生成图片时还是有一些问题存在的。
直到今天,豆包 AI 修图依然缺乏人像前后的一致性,也缺乏图片内容的方向性,只要涉及到人物面部的修图,那么最终出来的图像和原图的差异会很夸张,豆包本身也很难判断你要修改的是图片里的哪个元素。
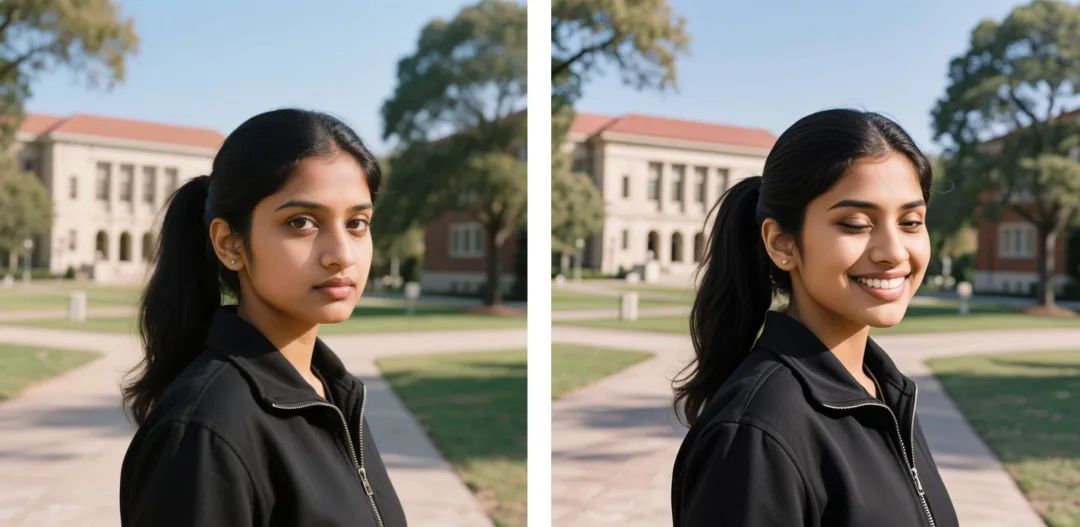
(图源:豆包)
倒是文字处理能力,相较以往有了一定提升,现在 SeedEdit 在修图时已经不会随便编造文字内容,但是图片生成时的错字现象依然需要改善。
不管怎么说,豆包 SeedEdit 算是弥补了国产大模型在语义 AI 修图应用这块的空白。
可以预见的是,随着 AI 图像编辑技术的不断发展,未来手机、电脑都可能会集成这项功能,就像AI消除、AI 扩图那样走进寻常百姓家。无论是小白还是大咖,每个人都有机会轻松上手使用,让自己对美的理解可以更直观地展现出来。
修图有手就行?或许真的不是梦。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


Gemini 3.5 Flash体验越来越糟糕?免费AI越用越傻,好的AI越来越贵
2026-06-05

倒卖Token,隐秘的中转站生意有多暴利
2026-06-05

可灵头上缺了一朵遮风挡雨的云
2026-06-05

腾讯高管:今年腾讯大部分代码都由AI生成
2026-06-08

豆包必须要收费了
2026-06-08
视频模型巨大的「隐形成本」,没人告诉你
2026-06-08

Claude深夜炸场!放出史上最强“危险级”模型Fable 5,价格太逆天
2026-06-10

vivo、荣耀接连入场,戳破了具身智能的AI叙事
2026-06-10







