
硅谷大换血!从小镇做题家到顶级AI研究员,华人为什么统治了AGI?
本文由 乌鸦智能说 撰写/授权提供,转载请注明原出处。
以下文章来源于:乌鸦智能说
作者:朗朗
在过去二十年,硅谷的互联网是属于印度人的。他们以勤奋、高效和强大的执行力,撑起了硅谷互联网时代的软件帝国。
但随着生成式 AI 的崛起,硅谷的人才格局正在发生系统性倾斜。华人,正在成为 AGI 赛道里最重要的人才来源,没有之一。
看看硅谷的“含华量”有多高:
Meta 超级智能实验室初始团队 11 人,就有 7 位华人;xAI 的首批 12 位成员里,5 位是华人,占比超过 40%;马斯克发布 Grok 4 时,身边坐着的两位核心人物也是华人;至于 OpenAI,关键团队 17 人中 6 位是华人。
难怪有人调侃:“犹太人的金融,华人的 AGI”。
更有意思的是,这些顶尖人才的履历几乎如同“模板”:
本科多出身于清北等国内顶尖院校,随后前往普林斯顿、斯坦福、MIT、卡内基梅隆等名校攻读博士,再顺理成章进入硅谷最前沿的 AI 实验室,成为推动技术边界的中坚力量。这几乎成了 AI 时代最稳定、最高效的人才输送渠道。
这背后有一个耐人寻味的问题:一个常被诟病"缺乏创造力"的教育体系,是如何系统性地培养出能穿透技术迷雾、找到 AGI 路径的顶尖人才的?
华人,成了美国最贵的人才
在硅谷顶级科技公司的 AI 部门里,核心成员中华人比例高得惊人。
保尔森基金会发布的《全球人工智能人才追踪报告 2.0》显示,2022 年,在美国排名前 20% 的 AI 机构中,中国研究人员的占比达到38%,甚至超过了美国本土的 37%。
如果把视角拉到具体公司就会发现,华人的身影更为突出。
(1)Meta 超级智能实验室,首批核心成员华人占比 64%
7 月,Meta 成立超级智能实验室,华人占比引人注目。在首批公布的 11 人核心成员中,7 位具华人背景。
他们几乎都是 OpenAI 关键技术和产品突破背后的技术骨干:
毕树超:GPT-4o 语音模式与 o4-mini 的共创者,前 OpenAI 多模态后训练负责人;
常慧雯:GPT-4o 图像生成的共创者,于谷歌发明 MaskGIT 和 Muse 文生图架构;
赵晟佳:ChatGPT、GPT-4 及多个 mini 模型的共创者,前 OpenAI 合成数据团队负责人。
此后团队扩展至 30 多人,在一份流传的 44 人名单中,华人比例接近一半。据《连线》杂志报道,Meta 为了抢人,甚至开出了四年 3 亿美元的薪酬方案,首年即可兑现超 1 亿。
(2)OpenAI 金牌 AI 团队,华人占 35%
在 OpenAI,华人的比重同样惊人。
2022 年 11 月,ChatGPT 惊艳问世,87 人的主创团队中,华人占比 10.34%,达到 9 人,且其中有 5 人本科就读于中国内地高校。
而后陆续亮相的多项产品背后,同样闪现着大量华人面孔:
GPT-4 背后有 30 余位华人,GPT-4o mini 团队的 9 位负责人中,有 5 位是华人,Sora 的 13 人研发团队中有 4 位华人
去年,OpenAI 推出其首个原生多模态模型 GPT‑4o,关键团队 17 位成员中有 6 位华人,来自清华大学、北京大学、上海交大、中科大等院校。
最新的 GPT-5 演示上,也三次出现华人研究员的面孔。更值得注意的是,华人已经开始走向管理层。比如,Mark Chen,2018 年加入 OpenAI,参与 DALL·E、GPT-4、o1 等核心项目,如今已被提拔为高级研究副总裁。
(3)马斯克的“中国智囊团”
在 xAI,马斯克的“智囊团”同样少不了华人。
创始团队 12 人中有 5 人是华人,占比超过 40%。在 Grok 4 的发布会上,和马斯克同台的两位核心创始成员就是 Tony Wu 和 Jimmy Ba。
其中,前者的身份是 xAI 的联合创始人,曾在谷歌 DeepMind、OpenAI 实习。而后者更是著名的 AdamW 优化算法提出者,论文引用量超过 21 万,早已是学术圈里的大牛。
由此可见,华人已经成为硅谷顶级 AI 实验室最重要的人才来源,没有之一。
这并不是偶然。根据智库 MacroPolo 报告,2019 年美国顶级 AI 研究机构中,拥有本科中国国籍背景的研究人员占比为 29%。仅仅三年后的 2022 年,这个数字飙升至 47%,几乎占了一半,而美国只有 18%。
一条清晰的顶级 AI 人才路径正在显现:清北等顶尖院校本科+美国博士=全球顶级 AI 人才。
据乌鸦君的不完全统计,在梳理的 30 位华人核心研究者中,有 22 人的路径相似:
本科就读于清华、北大、中科大、浙大等国内顶尖高校,随后前往普林斯顿、斯坦福、MIT、卡内基梅隆等名校攻读博士,再进入硅谷最前沿的 AI 实验室,成为推动技术边界的中坚力量。
比如,Meta 超级智能实验室里的核心成员中,就有不少这样的代表人物:余家辉,本科出自中科大少年班,博士阶段在 UIUC 就读;赵晟佳,本科清华、博士斯坦福;毕树超,本科浙大、博士伯克利;任泓宇,本科北大、博士斯坦福。
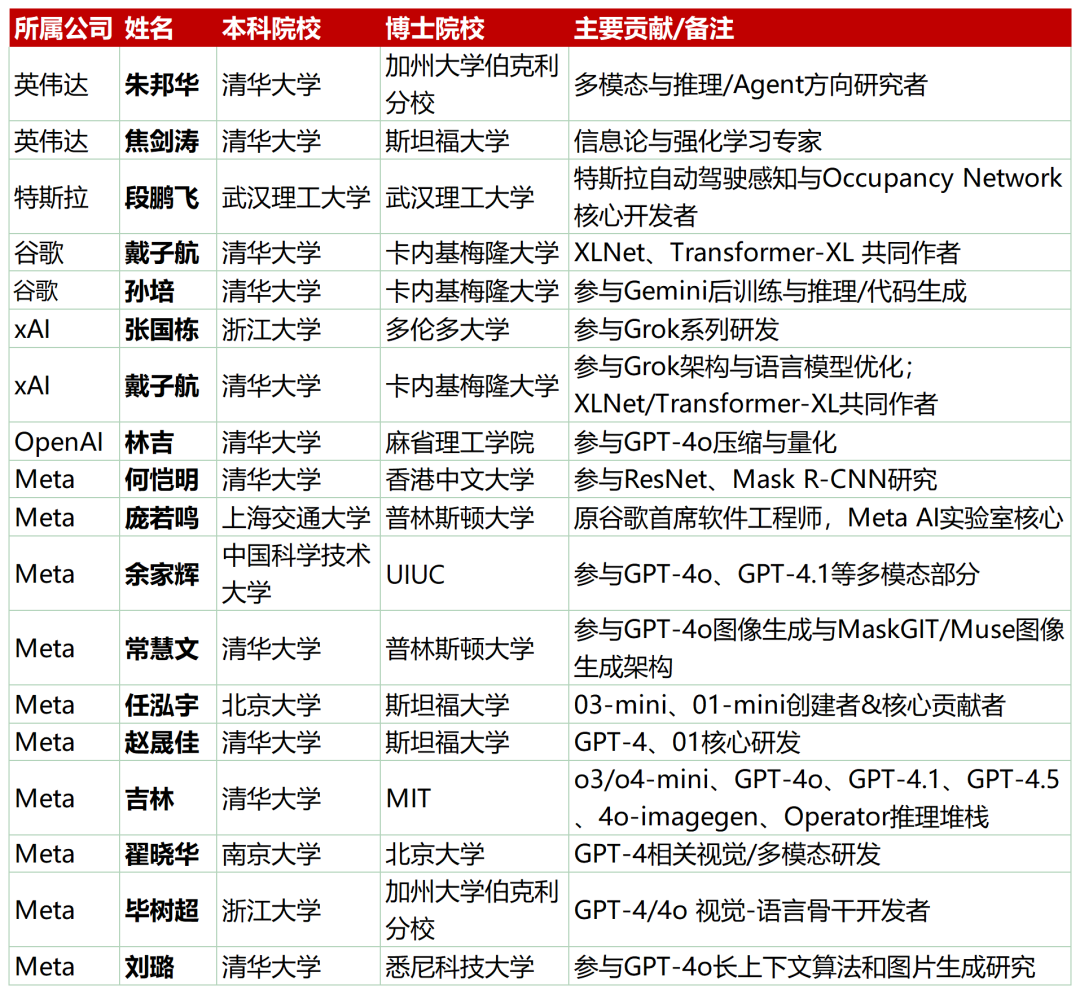
这些看似是“题海”里成长起来的“小镇做题家”,为什么会成为当下 AI 行业最稀缺的人才?
AI 时代的工程师红利从何而来?
过去,大家谈 AI,习惯性会把目光放在硅谷。但如果把镜头拉到现在,你会发现另一股力量正在快速生长,那就是中国在 AI 研究上的人才积累。
现在,中国每年计算机及相关专业毕业生超过 500 万,是全球最大的 STEM 人才输出国。
根据 Dimensions 研究数据库,目前,中国活跃的人工智能研究人员超过 3 万名。仅博士和博士后总数就相当于美国人工智能研究人员总数的两倍。相比之下,美国约有 1 万名研究人员,欧盟 27 国约有 2 万名,英国约有 3000 名。
这构成了中国 AI 庞大的人才梯队,甚至可以说是,AI 时代新的“工程师红利”。
更重要的是,中国的基础教育强调数理基础与解题能力,这种长期高强度的训练,恰恰培养了适合 AI 研究的核心素质:
第一,结构化思维,能够把现实问题翻译成数学问题。
比如,在奥数题、物理题,其实都是在让你练习:把现实情况转成公式和方程,再用数学方法解决。
做题训练里,学生学会了“去掉多余信息,抓住核心变量”的能力。在 AI 研究里也是一样,语言、图像、动作这些复杂的东西,都要先翻译成向量和矩阵,才能交给机器去处理。
第二,耐心和韧性。
数学题、竞赛题往往需要很久的思考和演算过程,耐心是必备品质。AI 研究也一样,一篇论文背后,可能要跑几百上千次实验;模型动辄几十亿、上千亿参数,调参非常耗时,没有耐心,很难在大模型实验里坚持下来。
尤其当强化学习取代预训练成为模型新的 Scaling law 后,中国学生的能力就就更适配了。
强化学习特点是目标明确(奖励函数),路径不唯一,需要不断试错迭代。用 Ilya 的话说:
“强化学习让 AI 用随机的路径尝试新的任务,如果效果超预期,那就更新神经网络的权重,使得 AI 记住多使用这个成功的事件,再开始下一次的尝试。”
这和奥数的逻辑很像:尝试路径→失败→纠错→总结→再尝试。
而这正是中国学生最熟悉的节奏。从小做题,他们已经习惯了把大问题拆成小问题,再逐步求解。长期的数理训练,也让他们对概率、优化、线性代数这些工具很熟练——而这些恰恰是 RL 的基本功。
很多人本科毕业时,矩阵运算、梯度下降、概率建模早就烂熟于心,所以进入研究时不用“补课”,能直接投入到算法创新和实现里。
再加上,RL 的特点是结果量化、指标清晰:奖励曲线、收敛速度、测试分数,都能一眼看到改进。这样的研究模式,特别符合华人务实、高效、追求确定性的习惯。
这也是为什么在 RL 领域华人的存在感格外强。
NeurIPS 2020 的 RL 论文里,30% 的第一作者是华裔;谷歌的 RL 团队里,有四分之一到三分之一毕业于中国高校;xAI 团队里,张国栋、杨歌、JimmyBa 等人,都在顶级 RL 研究里留下过成果。
某种程度上说,强化学习就是华人工程师的“天然主场”。而今年年初 DeepSeek-R1 的崛起,更像是一声清脆的锤响,昭示着这种优势正在结出果实。
背后并不神秘。中国有庞大的受教育人口、从小到大的数理训练、国家层面对科研的长期投入,以及一种深植文化的动力——相信技术能够改造世界。
正是这些因素,共同撑起了一条巨大的“人才管道”,源源不断地把博士级研究者送进美国的顶尖学府和 AI 实验室。
在大模型时代,硅谷仍然需要少数能发明全新范式的“达·芬奇式天才”,但当下更需要一大批能把算法磨到极致的工程科学家。中国的教育和人才体系,恰好在此刻展现出了强大的“造血能力”,提供稳定而厚实的科研底座。
AI 的竞争从来不是单一技术曲线的冲刺,而是人才管道、教育制度与文化心智的长期博弈。
当硅谷最前沿的实验室里遍布华人的身影时,这不仅是一种人才现象,更是一种文明现象。AGI 的未来,并不只是公司之间的角逐,而是全球文明在人才配置上的竞赛。
而在这场竞赛中,华人已经站在舞台中央。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


中国未来AI力量,藏在2026 WAIC这些首发新品里
2026-07-21

AI硬件,“老厂”凶猛
2026-07-20

刚刚,智谱建了一座只用国产芯片的数据中心
2026-07-22

Kimi,要去IPO了
2026-07-23

不危险不配上桌?AI御三家自曝家丑藏心机:安全报告成AI版安兔兔
2026-07-21

库克出手,阿里有了自己的“豆包手机”?
2026-07-20

AI Coding 最难的一仗,阿里为什么赢了?
2026-07-20

北美AI短剧市场:大厂的游戏,中小公司纯靠赌?
2026-07-21







