偷2396部黄片训练AI,Meta遭3.59亿美元天价“碰瓷”
本文由 乌鸦智能说 撰写/授权提供,转载请注明原出处。
以下文章来源于:乌鸦智能说
作者:朗朗
大家都知道,Meta 在 AI 上舍得砸钱。结果这回,美国一家成人公司也盯上了这块“肥肉”。
7 月 23 日,美国最大的***影厂商之一 Strike3,把 Meta 告上旧金山联邦法院。
指控的内容相当劲爆:Meta 疑似偷偷下载了 2396 部色情电影,用来训练自家 AI 模型。开口就是 3.5 亿美元的索赔,平均一部片子要价 15 万美元。
Meta 的回应很简单:不认。
在他们看来,Strike3 就是“碰瓷”,毕竟这家公司一直靠版权诉讼赚钱。据估算,Strike3 每年光靠和解金就能进账 1500 万到 2000 万美元。
就这样,一个 AI 巨头和一家***影公司,因为小黄片的版权问题对簿公堂。
问题也随之而来:Meta 究竟是怎么被 Strike3 盯上的?而它又为什么要收集这么多小电影?
偷偷下载 2396 部小黄片,Meta被告了
这次 Strike3 拿出的证据有理有据。
他们提交了 47 个下载 IP,其中 43 个明确属于 Meta/Facebook,另外 4 个来自家庭宽带,但全都指向同一位 Meta 员工的住址。

▲Strike3举证Meta相关IP有侵权行为
更关键的是,超过 10 万条网络日志显示,这些 IP 所下载的文件哈希值,与 Strike3 片库中的内容完全一致。
这里简单科普一下:哈希值就像文件的“指纹”。不管是电影、图片还是文档,都能通过哈希算法变成一串固定的数字和字母。如果两个文件的哈希值完全一样,就说明它们是同一个东西。
所以,从技术上讲,这些 IP 确实下了这些小电影。
看到这里,或许你有了一个疑问,有没有可能,就是 Meta 员工用公司己的网络下载黄片?
47 个人,7 年时间,2396 部小电影,平均每人每年才下 7 部片,这太合理了。毕竟 Meta 有七万员工,肯定有人“业余学习”积极。
但 Strike3 否认了这种可能,原因是这些 IP 的下载行为太像“机器操作”了:
首先,这些 IP 下载频率极高,专挑长片,还会同时拖不同分辨率的版本。这根本不符合正常人的操作习惯。
一般来说,人看片一次最多下几部,很少几十上百部地下;另外,清晰度通常只选一个版本就够了,不会同时把 480p、720p、1080p 都下完。
唯一的解释是,下载这些小电影的目的,是为了“收集数据集”,而不是为了观看。
第二,这批被侵权影片的平均做种时间长达 21.7 天,也不合理。“做种”是 BT 下载里的概念,是指用户下完片后,把片子上传给别人。
一般人下载完后挂个一两天就会关掉,没必要一直贡献带宽。但平均做种 21 天,说明有人在刻意保持上传。他们认为 Meta 是在故意共享盗版文件,以获得更快的下载速度,以更快地侵犯更多内容。
基于这些迹象,Strike3 认定真相是:
从 2018 年起,Meta 就通过 6 个虚拟私有云搭建了匿名下载网络,用脚本批量操控 BT 做种。甚至有员工把“工作任务”带回家,继续用家庭宽带挂片。
至于为什么偏偏选***影?Strike3 给的解释也挺“专业”。
第一,片子本身的特点很适合 AI“学动作”。
***频里经常是长镜头,画面连续不切断;灯光稳定,背景简单;声音也干净,对话和动作对得上。
这对 AI 来说很重要,因为它需要大量连续的素材,才能学会“时间怎么流动”、“动作怎么接上”以及“声音和画面怎么同步”。
第二,画面重复,方便 AI“学套路”。
这种片子往往是高分辨率,且镜头手法比较单一,常见的推拉摇移、固定机位反复出现。
AI 可以学规律,学会怎么稳稳地跟拍人物,怎么切镜头更自然。这些重复结构,就像在给 AI 上“语法课”。
面对指控,Meta 沉默了一周才开口。回应很简单:不认。
在双方针锋相对之下,美国首例由成人娱乐公司直接推动 AI 版权争议的标志性案件,就这样出现了。
诉讼文件链接:
https://chatgptiseatingtheworld.com/2025/07/26/strike-3-holdings-sues-meta-for-copyright-infringement-of-adult-videos-including-alleged-use-to-train-ai-model/
索赔 3.5 亿美元,Meta 被“碰瓷“了?
Meta 不认,一个重要原因是:他们觉得 Strike3 就是来“碰瓷”的。
Strike3 这家公司吧,主业是卖小电影版权,副业是打官司。它是美国著名的“版权狂魔”,擅长靠诉讼敲钱。
根据 TorrentFreak 统计,从 2017 年到 2024 年,Strike3 发起了超过 20000 起诉讼,2024 年更是创下单年纪录。
可这些官司里,很少有被打到底的。真正的套路是:先发传票吓人,再逼你交出几百到几千美元不等的和解金。


▲Reddit上经常出现求助帖:“我收到Strike3传票了怎么办?!”
据日本媒体 GIGAZINE 援引律师估算,Strike 3 每年通过和解金赚的钱大约在 1500 万美元到 2000 万美元之间。
也就是说,光靠版权索赔,Strike 3 一年就能赚 1 亿人民币,平均每部片子要赔 100–500 美元。
为了锁定“猎物”,他们甚至自研了一个爬虫工具 VXN Scan,天天在 BT 群里蹲守。它的原理很简单:靠哈希值识别种子文件,记录 IP 和时间,再通过传票逼网络服务商交出真实用户信息。
虽然 VXN Scan 证据算不上铁证,但已经足够支撑他们的诉讼轰炸。
这次遇上 Meta 这么个“大金主”,Strike3 当然也毫不手软,直接开口索赔3.59亿美元——平均每部片子要价 15 万美元。
这差不多顶得上他们此前索赔 15 年的收入。
而 Meta 之所以被盯上,也怪不得别人。因为他们自己也有前科。
早在 2023 年,Meta 就因为盗取数据,被一群作家告上了法庭。
当时的指控是:Meta 通过虚拟私有云隐藏 IP、写自动化脚本,从 LibGen、Z-Library 这些“影子图书馆”里爬了 81.7TB 的盗版电子书,用来训练 LLaMA 模型。
为了避免暴露,他们甚至特意设置了虚拟私有云服务器,连着匿名 IP,专门用来掩盖 BT 下载行为。
这一次,Strike3 发现,匿名 IP 地址也出现在片源 BT 群组里。在他们看来,Meta 在书籍数据上用过的那套“暗箱操作”,也用在了下载小电影上。
这一次被 Strike3 咬住,既像是旧账翻新,也像是恶人碰上恶人。Meta 嘴上说“不认”,但它过去的操作已经让外界很难完全相信。

▲业内人士辣评(来源:领英)
无论结果如何,这场官司都会成为 AI 训练与版权博弈的分水岭——不是因为片子有多敏感,而是因为它揭穿了一个现实:
AI 巨头模型的飞速进化,很大程度上靠的就是这些灰色数据。
这场官司表面上是 Meta 和 Strike3 的纠纷,但本质上却是整个 AI 行业绕不开的难题:训练数据从哪来,边界在哪,谁来买单。
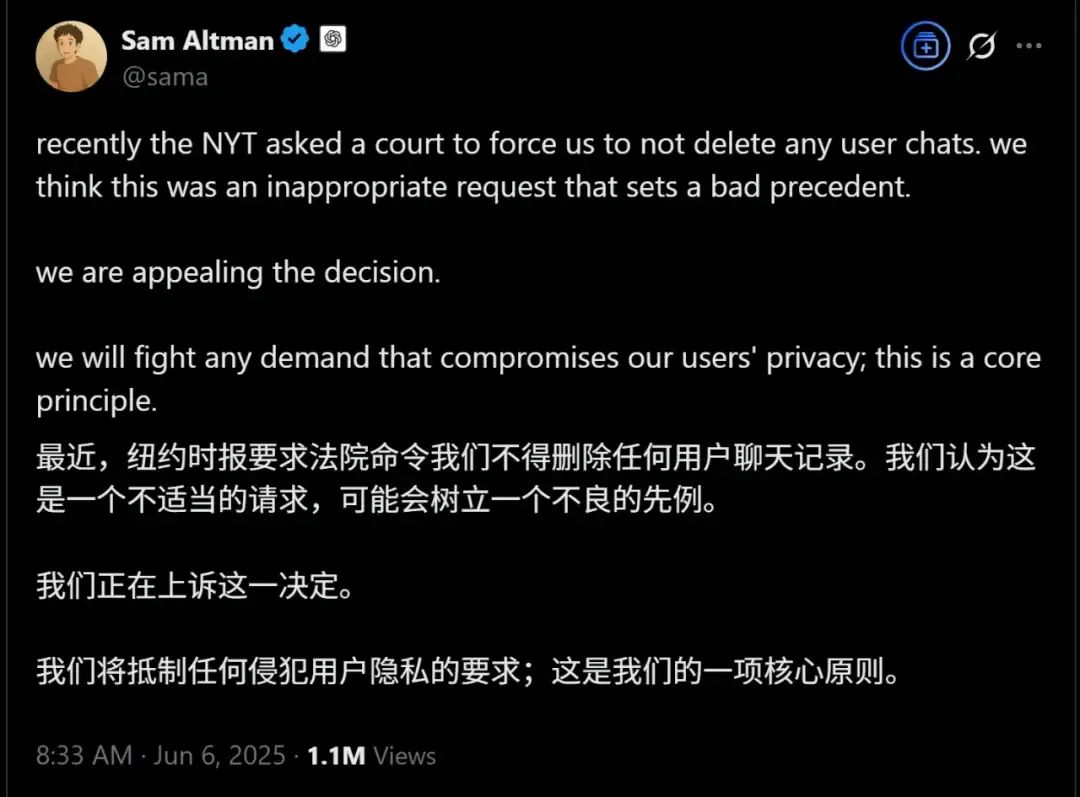
▲OpenAI和Microsoft正面临来自《纽约时报》和《每日新闻》作者的合并版权诉讼
Meta 有钱,可以挨刀;但那些想靠 AI 闯出一片天的小公司,如果连数据都碰不得,那就只能在合规成本里被压垮。
所以,不管最后谁赢谁输,这个案件可能都会延伸向一个问题:AI 还能在灰色地带摸索多久?靠“薅盗版”的时代,可能真的要走到尽头了。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


豆包之后,千问也想要“脸”
2026-04-27

日更7.5万首,播放不足3%:AI音乐沦为“虚假繁荣”?
2026-04-27

刚刚,DeepSeek搞了个V4预览版,震撼行业
2026-04-27

Anthropic 的“刀法”越来越像苹果和微软了
2026-04-29

DeepSeek-V4发布,黄仁勋的担忧成真了
2026-04-28

苹果“库克时代”谢幕,那些没说出口的话
2026-04-28

4月AI混战大盘点:DeepSeek压轴登场,AI小龙加速商业化
2026-04-28

相比龙虾,AI浏览器更适合普通人
2026-04-29