
国产六大推理模型激战OpenAI?
本文由 光子星球 撰写/授权提供,转载请注明原出处。
以下文章来源于:光子星球
撰文:郝鑫
编辑:王潘
“DeepSeek-R1 如同当年苏联抢发的第一颗卫星,成为 AI 开启新时代的斯普特尼克时刻。”
2025 年春节前,DeepSeek 比除夕那天的烟花先一步在世界上空绽放。
离年夜饭仅剩几个小时,国内某家云服务器的工程师突然被拉入工作群,接到紧急任务,要求其快速调优芯片,以适配最新的 DeepSeek-R1 模型。该工程师告诉我们,“从接入到完成,整个过程不到一周”。
大年初二,一家从事 Agent To B 业务的厂商负责人电话被打爆,客户的要求简单粗暴:第一时间验证模型真实性能,尽快把部署提上日程。
节前大模型,节后只有DeepSeek。DeepSeek-R1就像一道分水岭,重新书写了中国大模型的叙事逻辑。

以 2022 年 11 月,OpenAI 发布基于 GPT-3.5 的 ChatGPT 应用为起点,国内自此走上了追赶 OpenAI 的道路。2023 年,大模型如雨后春笋般冒出头,无大模型不 AI,各厂商你追我赶,百模大战初见端倪。
你方唱罢我登场,2024 年的主人公变成了“AI 六小虎”,AI 创业成为新的故事脚本。仅一年的时间,智谱累计完成 40 亿元人民币融资,月之暗面融资总额超 13 亿美元。在资本抛出橄榄枝后,他们站到了聚光灯下,一跃成为明星独角兽公司。
新的转折点发生在 DeepSeek-R1 爆火后,曾有一段时间内行业陷入了“一半火焰,一半海水”的境地,即一边积极拥抱学习 R1,一边陷入了深深的自省。
徘徊是短暂的,随着百度、阿里、字节、腾讯、科大讯飞等厂商纷纷发布最新的推理模型,2025 年的 AI 叙事主题呼之欲出:“六大推理模型迎战 OpenAI”。
推理模型的当打之年
回看 OpenAI 的模型发布时间线,在基础模型方向,可以分为 GPT 系列和 o 系列,2024 年 OpenAI 所发布的 o1 是一个里程碑式的转向。
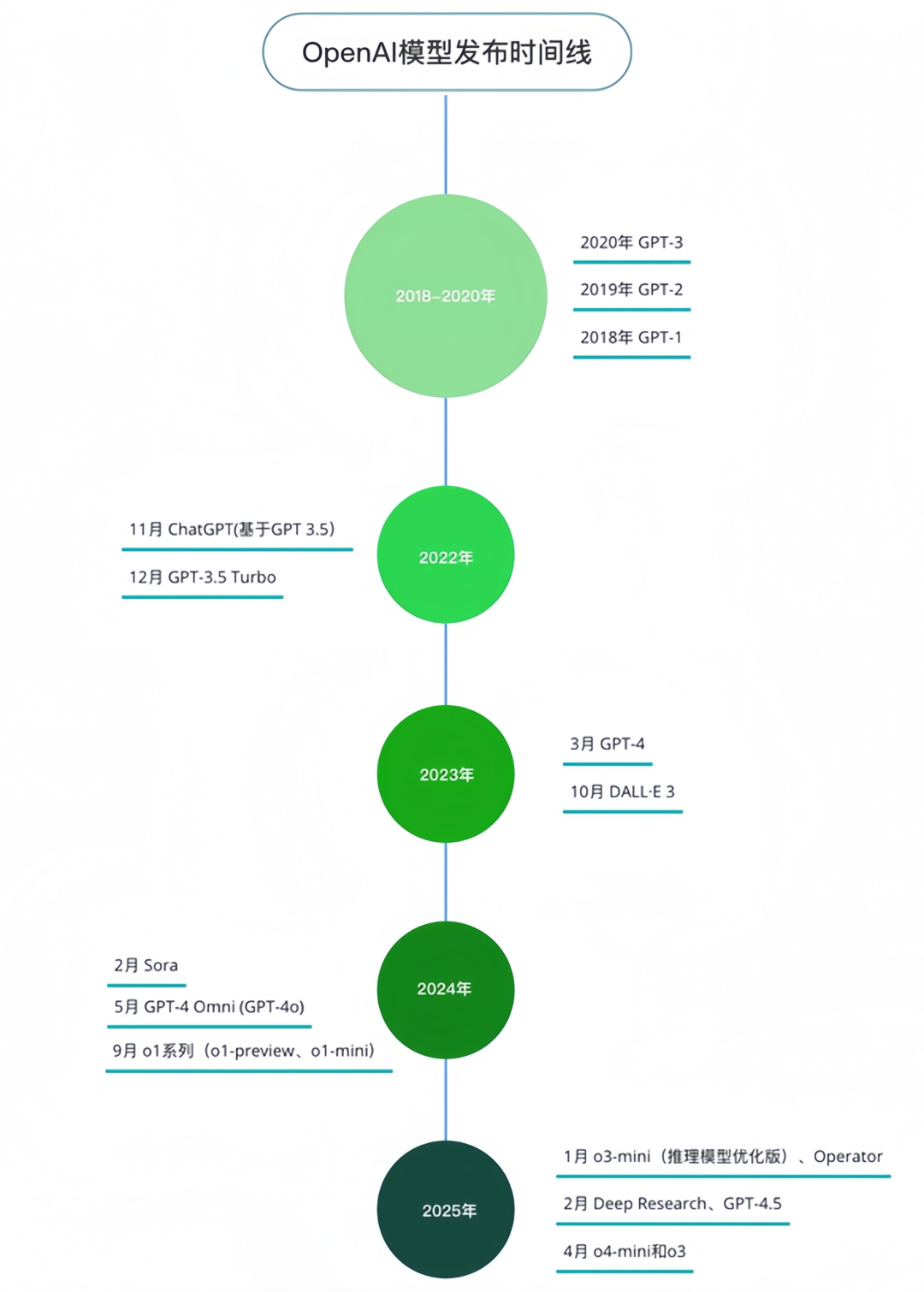
(光子星球制图)
GPT 系列是 OpenAI 最早构建的模型体系,聚焦自然语言处理、对话系统与文本生成,强调语言流畅性与上下文理解能力。o 系列是 OpenAI 于 2023 年新设立的模型家族,核心聚焦“结构化推理”能力,强调模型的逻辑、分析、工具调用能力,是对 GPT 系列“语言偏重”路线的补充与扩展。
未来 GPT 系列或将逐渐退出历史舞台。OpenAI 在更新日志中宣布,自 2025 年 4 月 30 日起,GPT4 将在 ChatGPT 中退役,将完全被 GPT4o 取代。
如果只是 OpenAI 自身技术选择,o 系列和 DeepSeek-R1 并不会带来如此强大的影响。以底层模型架构举例,有公司选择传统的 Transformer 架构,也有公司选择自研架构。
o 系列崛起有一个大背景,即大模型范式的改变,从传统预训练阶段模型参数的 Scaling Law,转移到强化学习推理计算带来新 Scaling Law。这一点在 OpenAI 的 o3 开发过程中得到了验证,OpenAI 观察到大规模强化学习表现出与 GPT 系列预训练中观察到的趋势相同,计算量越大,性能越好。
简而言之,就是让 AI 自己规划、学习、反馈和完成任务,这与如今大热的 Agent 所需具备的能力一致。
有技术人员告诉光子星球,o1 以后所发布的“Deep Research”Agent,完全基于模型从头训练,且未公开思维链推理过程。“这意味着底座模型能力直接决定了 Agent 的落地效果”,想要在大模型第二程变得有竞争力,推理模型几乎成为了必选。
站在公司和技术一号位角度,第一时间跟进 o1 和 DeepSeek-R1 是一种判断和眼光,但同时也代表着重投入与高风险。
我们了解到国内的很多公司,名义上有自研大模型,但实则是“套壳”。o 系列站在 GPT 的肩膀上诞生,这导致地基不牢的公司只能望而却步。另一方面,融资和商业化变现的压力,又淘汰了一批公司。
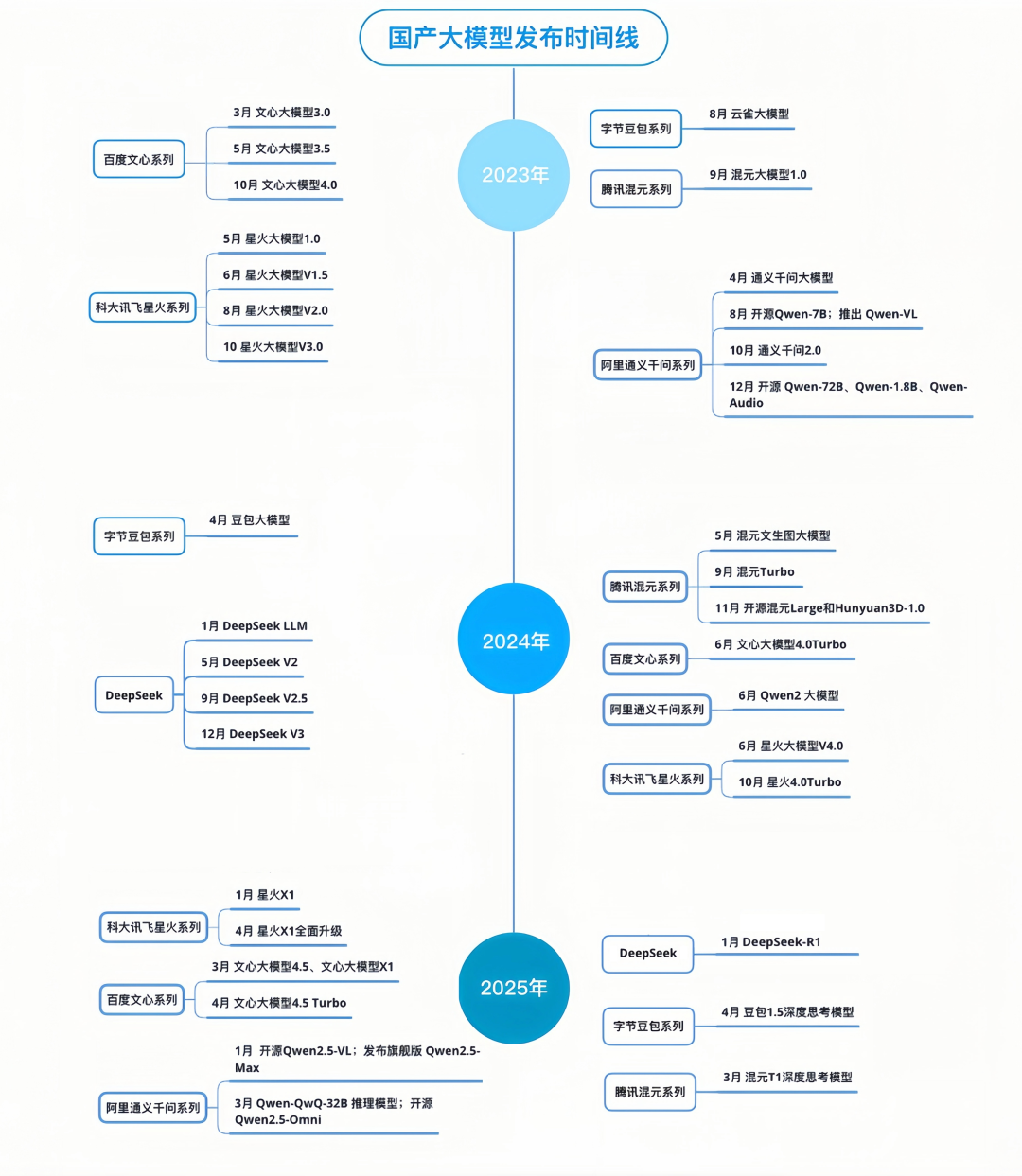
(光子星球制图)
于是,我们发现去年星光暗淡的大厂们,成为了反应最快,跟进最及时的代表。
以 DeepSeek-R1(2025 年 1 月 20 日发布)为时间基准线,当月科大讯飞就发布了深度推理大模型——讯飞星火 X1;3 月,百度发布文心大模型 X1,阿里发布通义千问 Qwen-QwQ-32B 推理模型,腾讯发布混元T1深度思考模型;4 月,字节豆包 1.5 深度思考模型上线,同时讯飞星火 X1 迎来升级,发布“快思考、慢思考统一模型”。
上述厂商有一些共同之处,跟上了每一次的模型能力升级进度,在转向推理方向前,其基础模型能力基本都达到了 GPT-4 的水平。以此作为参照,这可能是迈入大模型第二阶段的基本条件。
六大推理模型混战 o3
o3 目前是 OpenAI 最强大的推理模型。网上流传的一张大模型 IQ 图显示,人类平均 IQ 为 100,o3 智商达到了惊人的 136。
测试数据显示,o3 在多项基准测试中超越了 o1 的性能,特别在分析图像、图表和图形等视觉任务中表现尤为出色。
在外部专家的评估中,o3 在困难的现实任务中比 o1 犯的重大错误减少 20%,在编程、商业、咨询和创意构思等领域都有不错的表现。
需要承认的是,OpenAI 存货确实有两把刷子,继 o1 之后,o3 又成为了新的大模型性能攀登高峰。但国内各大模型厂商的跟进速度并不慢,若以 DeepSeek-R1 为参考标准,百度、阿里、科大讯飞、字节、腾讯后面所发布的推理模型水平相差不大,部分在一些测试指标上甚至有超越。
截至目前,国产六大推理模型各有千秋。
DeepSeek-R1 的意义不言而喻,完整的技术报告和开源部署,给予了行业推理大模型训练思路。打开了 OpenAI 闭源的“黑匣子”,成功复刻出了性能相差无几的 o1。R1 突出的特点是“花小钱办大事”,高效且追求极致性价比。在非常有限的算力、数据等资源投入的情况下,训练成本却仅为 560 万美元,远低于美国 AI 公司的数千万美元乃至数亿美元投入。
一位知情人士告诉我们,DeepSeek-R1 和一些国产推理大模型不构成直接竞争对手。在B端业务中,目前阿里开源的千问系列模型占比更重。“全尺寸和全模型,就像一个全家桶,可以供客户选择。32B 的模型大小,跑起来成本也不是很高”。
百度在这波中从生态层面接入了 DeepSeek,这给了用户更多选择权,开源和免费的策略或将能吸引更多用户。文心大模型 X1 采用“思维链-行动链”协同训练,在复杂任务中自动拆解为二十多个推理步骤,同时可以调用十几种的工具链,以此来增强 Agent 的能力。
有参与过与百度合作的人士告诉光子星球,在金融、医疗、政务等一些垂类领域,百度会“牵线搭桥”,把一些相关业务的公司攒到一个局。“百度提供基础模型,我们提供另一方所需的技术,最后直接跟百度核算”。通过这种方式,百度正不断缩小 To B 大模型市场与科大讯飞之间的差距。
科大讯飞的星火 X1,是当前业界唯一基于全国产算力训练的深度推理大模型。
正是基于全栈国产、自主可控的优势,科大讯飞的星火大模型倍受央国企和政府客户的青睐,保持行业端领先。4 月 21 日,星火 X1 升级提升了通用能力,也同步增强了面向行业的解决方案能力。在重点行业,如教育、医疗、司法等领域的测试中,都获得了超过 OpenAI 和 DeepSeek 的分数,这些能力无疑会在今年大模型订单中有所体现。
星火 X1 一个模型同时支持两种思考模式,提升了模型处理不同复杂度任务的能力,满血版星火 X1 仅需 4 张卡(华为 910B)即可部署。与华为的深度合作,以及不断迭代的底座大模型能力和强大的行业大模型落地体系,已经成为科大讯飞在一众大厂围剿中突出重围的三大利器。
国内闭源大模型中,豆包模型被评价为“有一定价格竞争力”。一位做 AI 玩具的厂商告诉我们,他的产品接入了多家大模型,在用户使用过程中,优先使用各家的免费 Token 额度,“一旦超过后,优先切换豆包,价格能控制在比较低的成本”。
去年,豆包参与主导了价格战,豆包大模型价格降至 0.0008 元/千 Tokens,豆包视觉理解模型定价 0.003 元/千 Tokens,均低于当时行业平均水平。此外,豆包大模型是技术落地 AI 应用产品值得借鉴的案例,端到端的实时语音技术、多模态、Agent 技术都能在第一时间介入豆包应用端,这也是支撑其快速迭代更新的原因之一。
腾讯混元入场较晚。有员工曾向我们表示,混元团队成员大部分以前是搜索推荐广告出身,跟通义、字节或许有一定差距,“赶鸭子上架,好像也没什么明确方向,东一下西一下”,“一群外行人指导内行人”。加之人员的流逝,导致了混元曾一度处于停滞状态。
借着 DeepSeek 崛起的东风,元宝已经悄然实现了逆袭。至少从数据层面看,已经取得阶段性成果。一位内部人士告诉我们,2025 年春节以来的这几个月,腾讯倾注了整个集团资源对元宝进行推广,无论线下活动资源,还是微信导流或者预算投入,对于元宝都是重点倾斜,通过这种大力出奇迹的方式,逆转了此前完全被动的局面。
从目前各公司的市场反馈来看,云端多模调用已经逐渐被认可,各家模型并存,用户按需调取才是未来。在现实情况中,客户最终是否选用一款大模型,模型性能只是一项衡量标准,背后可能还涉及数据、生态等多方面的考量。
大模型将全面国产化?
自 DeepSeek-R1 开始,国产推理大模型成为了各榜单的常客,AI 开源社区的用户以真实的下载量和 Star 数来支持中国 AI 的发展。
即便如此,当前大模型仍面临着或多或少的“卡脖子”的问题。
近期,有消息称,英伟达已通过非正式渠道通知其 AIC 合作伙伴(如七彩虹、影驰、同德等),暂停 GeForce RTX 5090D 的销售和出货。这一举措被认为是英伟达在应对国际环境变化的预防性措施。
尽管英伟达尚未发布正式公告,但业内普遍认为,RTX 5090D 的供应已进入“暂停状态”,这仅仅才只是开始。
若从源头上被限制,英伟达必将遭遇更加巨额的损失,而美国之外国家的大模型发展将遭遇不确定性,追赶 OpenAI 的步伐也将受到一定的阻碍。
在此背景下,全国产化技术路径将越来越成为大家的备选项。这其中,科大讯飞做了较为充分的准备。据了解,科大讯飞与合作伙伴联合通过四大核心技术优化,实现 MoE 模型集群推理性能翻倍提升。
根据最新测试集评测结果,星火 X1 在通用任务效果评测中全面对标 OpenAI o1 和 DeepSeek R1,在数学、知识问答等方面表现突出,这表明在技术自主可控的道路上,中国 AI 已具备与国际顶尖模型同台竞技的实力。
去年风光无限的 AI 六小虎,如今早已各奔东西,境遇迥然。被 DeepSeek 击碎“AGI 理想”“学术天才创业”和“明星 AI 产品”的月之暗面,回归到低调的技术研发中;将底层技术和产品解绑后的 MiniMax,加大了对技术的投入,方向同样为 Agent 和推理模型;六小虎中的智谱终于盼来了即将 IPO 的好消息,不过其整体营收、估值以及能否顺利实现 IPO,仍充满变数。
去年,Kimi、海螺 AI 等 AI 应用的出圈,短暂地迎来了 AI 公司的高光时刻。但今年,推理模型已经成为了国内各大厂商角逐的重要方向,AI 六小虎的方向与大厂高度重合,而决定他们能否生存下去的“口粮”则握在大厂们的手上。
如今,随着六大推理大模型的全面崛起,以及国际环境的不确定性加剧,全栈国产化大模型有望将成为一种新的主流。
从半导体、工业软件与信创再到今天的 AI 芯片,历史的经验告诉我们,想要摆脱被制约的现状就得实现独立自主,将命运牢牢掌握在自己手中。或许在不久的将来,越来越多的国产大模型将走上全栈国产化对抗 OpenAI 们的道路。

扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


腾讯AI秘密“换船”:元宝失宠,WorkBuddy接棒
2026-06-12

腾讯高管:今年腾讯大部分代码都由AI生成
2026-06-08

Claude深夜炸场!放出史上最强“危险级”模型Fable 5,价格太逆天
2026-06-10

豆包必须要收费了
2026-06-08

苹果把Siri交给了Gemini
2026-06-10
视频模型巨大的「隐形成本」,没人告诉你
2026-06-08

vivo、荣耀接连入场,戳破了具身智能的AI叙事
2026-06-10

普通人怎么读懂Token经济学?
2026-06-11








