
性价比搏击:Grok 4 Fast 推理成本直降 98%
本文由 AI科技评论 撰写/授权提供,转载请注明原出处。
以下文章来源于:AI科技评论
作者:梁丙鉴
编辑:马晓宁
几乎没有预热,马斯克不声不响把模型调用成本砍掉 98%。
作为低成本推理模型的最新进展,xAI 于上周五发布了其旗舰模型的轻量化版本 Grok 4 Fast。
通过大规模强化学习实现智能密度最大化,Grok 4 Fast 在基准测试上实现了与 Grok 4 相当的表现。同时由于推理任务的平均 token 消耗减少了 40 %,xAI 此次更新将前沿模型的调用成本大幅降低。
据官方测算,Grok 4 Fast 单个推理任务的成本最低可降至原来的 2%。
这已经是一个可以改写大模型竞争规则的数字。
端到端强化学习
如果要给 Grok 4 Fast 三个关键词,那应该是 AI 搜索、上下文窗口和统一模型架构。
xAI 在一篇博客中介绍,Grok 4 Fast 拥有原生的工具调用能力,这是指 Grok 4 Fast 通过端到端工具使用强化学习进行训练,在决定何时调用代码或网页等工具方面表现出色。
由于背靠 X 平台的丰富数据,此举为 Grok 4 Fast 在自主探索能力方面带来的优势更为突出。该模型能够无缝浏览网页和 X 平台,利用实时数据增强查询,同时支持跳转链接获取媒体内容,并以极快速度综合生成结果。
对于外部工具的自主使用能力,Grok 4 Fast 在 BrowseComp(44.9%)和 X Bench Deepsearch(74%)等基准测试中,表现优均于 Grok 4。
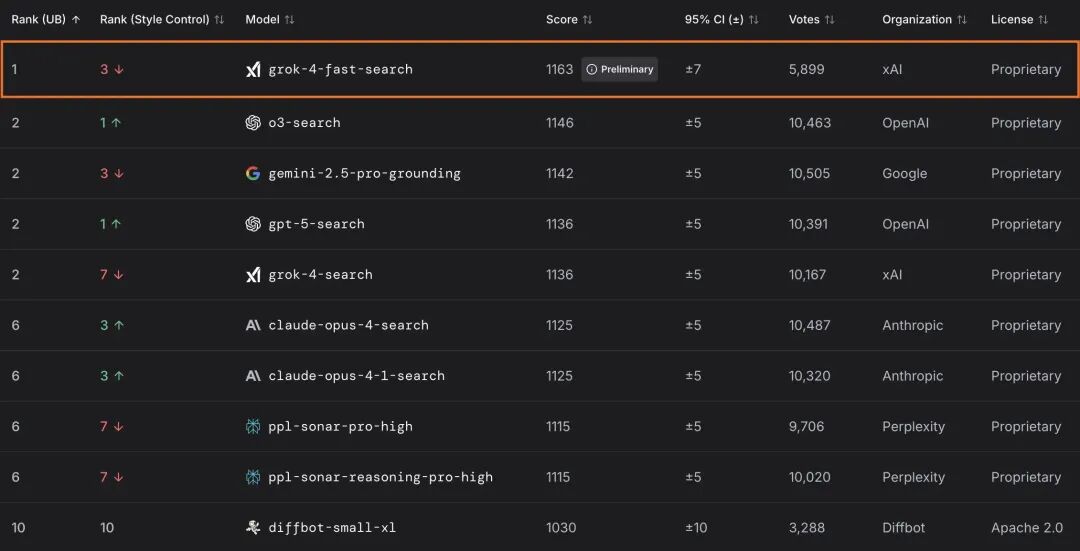
在 LMArena 的搜索竞技场中,Grok 4 Fast 以 1163 分位列第一,力压此前 OpenAI 领先的 o3-websearch,更是优于 gpt-5-search 和 grok-4-search。在文本竞技场中,Grok 4 Fast 则排名第八,以一分之差险胜 grok-4-0709版本。
可以看到,Grok 4 Fast 已经显著优于同等量级的模型,而在搜索相关任务中,模型参数造成的差距则可以被强化学习带来的推理效率和智能密度所追平甚至跨越。
即将和 Grok 4 Fast 同期推出的是其两个版本,grok-4-fast-reasoning 和 grok-4-fast-non-reasoning,即长链式思维和快速响应两种推理模式,均具备 200 万 token 的上下文窗口。
值得一提的是,Grok 4 Fast 采用了统一模型架构。
此前,在不同推理模式下应用不同的独立模型已经成为业界通行的选择。对于仅需要简单回答和大量推理的任务,手动切换模型的开关对于各个模型厂商来说几乎已是标配。
而 Grok 4 Fast 此次更新引入了统一架构,其中 reasoning(长链式思维)和 non-reasoning(快速响应)两种模式由同一模型权重处理,推理过程中通过系统提示进行引导。
这种设计进一步降低了端到端延迟和 token 成本。可以预见的结果是,在压缩调用成本之外,Grok 4 Fast 距离那些对即时响应存在高需求的场景也更近了一步。
SOTA 性价比
SOTA 一日三变,市场对模型性能挤牙膏的戏码早就没有了耐心。
xAI 也深知这一点,所以比起循例公布的基准测试结果,此次更新真正的“军火展示”其实是下面这两张图。
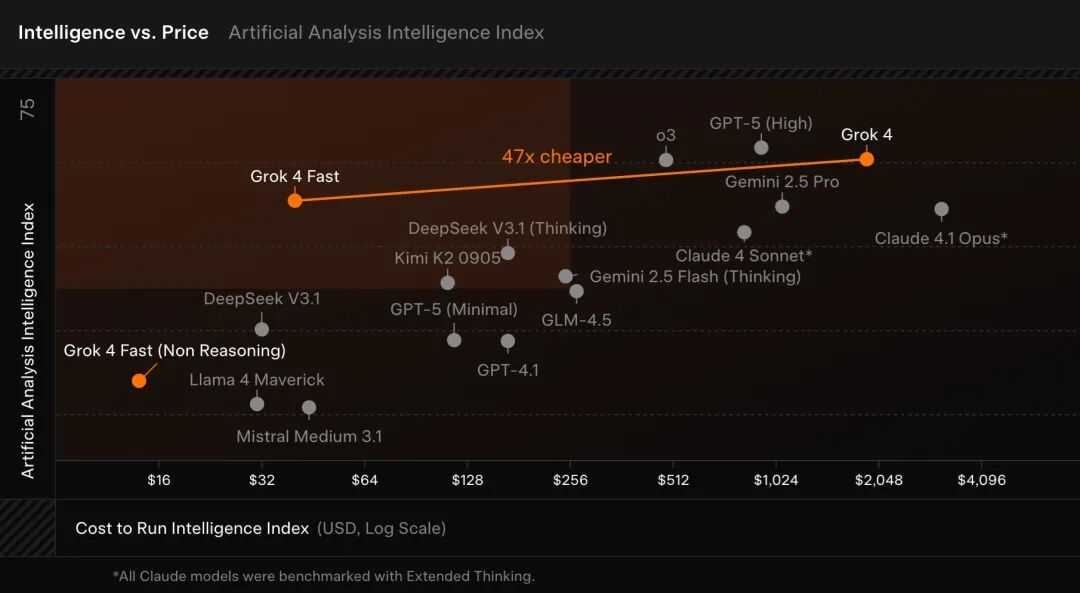
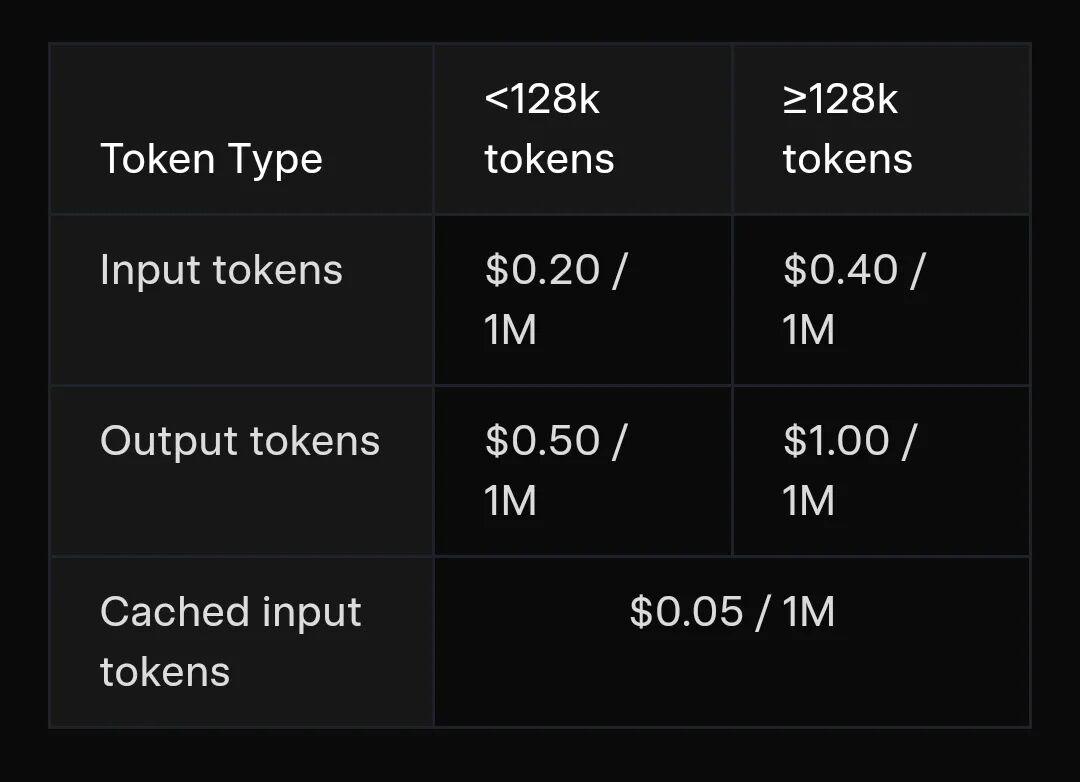
Grok 4 Fast 的 token 效率提升了 40%,加之每个 token 的大幅降价,最终结果是开发者的模型调用成本显著降低。而此时的模型性能,仍可以基本保持在 Grok 4 的水平。
根据 Artificial Analysis 的独立评测,Grok 4 Fast 相较于其它公开可用的模型,展现出了 SOTA 级别的性价比。
在官方博客中,xAI 将 Grok 4 Fast 称为“低成本推理的最近进展”。98% 的成本压缩一出,马斯克就差把“我们最便宜大碗”写在脸上。虽然没能在追求智能上限的路上甩开友商,但“谁都能用”是在“比谁都强”之外,另一种打遍天下的可行方案。
在此前的很长一段时间里,大模型都是一场暴力美学的军备竞赛,更大的参数规模、算力消耗和更强的推理能力成为了模型厂商竞争的硬指标。GPT-4、Gemini、Llama系列,乃至 xAI 自家的 Grok 4 Heavy,都是这种极致性能追求下的产物。
然而实验室之外的世界没有那么关注技术边界,当大模型以一款产品的角色面向市场,过去的技术路线也在应用场景之前留下了一道道坎,其中最为明显的就是昂贵的推理成本和漫长的响应时间。
相比之下,曾经被视为阉割性能的小模型,如今却正在成为应用普及的关键角色。
xAI 虽未公布 Grok 4 Fast 的具体参数,但根据命名逻辑的行业惯例,其大概率是在 Grok 4 的基础上通过蒸馏、架构优化等技术降低了计算负载与延迟。这意味着它能在更低配置的服务器甚至边缘设备上高效运行,并实现远低于 Grok 4 Heavy 每百万 tokens 输入 3 美元、输出 15 美元的“奢侈品”定价。
“低成本推理”主打的不是推理,而是低成本。在智能上限短期内突破无望的背景下,每省下一个 token,每个 token 多便宜一点,都是向落地多迈出了一步。而在这场性价比搏击中,马斯克先挥出了一记重拳。
参考资料:
https://x.ai/news/grok-4-fast#native-tool-use-with-sota-search


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


中国未来AI力量,藏在2026 WAIC这些首发新品里
2026-07-21

AI硬件,“老厂”凶猛
2026-07-20

Kimi,要去IPO了
2026-07-23

北美AI短剧市场:大厂的游戏,中小公司纯靠赌?
2026-07-21

库克出手,阿里有了自己的“豆包手机”?
2026-07-20

AI Coding 最难的一仗,阿里为什么赢了?
2026-07-20

刚刚,智谱建了一座只用国产芯片的数据中心
2026-07-22
千问补课苹果AI:阿里有了自己的“豆包手机”
2026-07-22







