GPT-5 放弃追求智能上限了?
本文由 AI科技评论 撰写/授权提供,转载请注明原出处。
以下文章来源于:AI科技评论
作者:梁丙鉴
编辑:陈彩娴
GPT-5 发布,虽然靠着“OpenAI”的名气也刷了一波流量,但在 AI 科技评论看来,GPT-5 的结果是让人失望的。
原因在于:Sam Altman 对 GPT-5 的“推销”已经全面转向现有的模型能力可以在多少个(我们知道是“很多”)任务上性能提升几个点,而非基础大模型的能力在现有技术路线上朝着“智能进化”的方向做了多少突破——以至于正常发布会看下来,只是“Scaling Law 遇到瓶颈”的又一有力佐证。
唯一值得乐观的点是:GPT-5 告诉了我们,OpenAI 对基础模型的能力突破也没招了,而下一代基础模型的高地战、每一个科研团队都有同等的机会。
大模型发展到现在,不难发现,全球在 AGI 技术创新上的方向最终归纳到了两个点:一是多任务表现(但这并不脱离“专有数据+预训练”的“背诵”范式),另一个是自主思考、学习与推理能力。而这次,时隔一年多姗姗来迟的 GPT-5,显然是将落脚点放在了前者。
虽然走“白盒路线”的马毅被认为离经叛道,但其提出的“知识不等同于智能”的观点之所以在业内能有所拥趸,原因正是现有大模型发展的瓶颈突显。通用人工智能之路漫漫,GPT-5 没有表现出持续追求智能上限的野心,是否侧面也反映了大模型之于 AGI,已经“江郎才尽”了?
这也迫使我们必须重新审视:一个能够自主学习、思考与推理的人工智能模型,接下来要如何突破?
据 AI 科技评论与多位业内人士的交流,这确实是目前基础模型最难的问题,且并非单靠多任务熟练、多模态大模型就能突破。
一位资深研究员向 AI 科技评论举过这样一个生动的例子:“如果以人为类比,一个人即使瞎了、聋了、哑了,TA 依然是一个人,因为 TA 的大脑依然在感知、思考并与世界交互。”
换言之,虽然如今有观点认为,通过增加多模态的信息能增强 AI 模型的智能水平,但一个残忍的事实是:至今依然没有足够的研究结果表明,在现有架构的基础上,通过向模型注入更多模态的信息能带来“智能的涌现”。同样,多任务处理性能提升,本质其实是应用工程的创新,而非基础研究的突破。
GPT-5 的发布确实取得了一系列出色的成果,但或许也提醒了此刻已到 AGI 的反思关口。
支持调用 GPT 系列子模型,
高频任务针对性优化
写作、编程、数学能力、健康管理、视觉感知、指令遵循、工具调用……OpenAI 这场深夜发布会像是才艺表演,让 GPT-5 在常见任务场景都展示了一遍。在模型智能水平之外,OpenAI 此次更新走的更像是工程路线,结果以实用为导向。Sam Altman 特意指出,针对 ChatGPT 最常见的三种任务,即编程、写作和健康管理,GPT-5 均进行了专门的优化。
作为大模型的兵家必争之地,GPT-5 的 Coding 能力首先受到了高度关注。OpenAI 称其为自家迄今为止最强大的编程模型,在“复杂的前端生成和调试大型代码库方面表现尤为出色”。有用例显示,GPT-5 只需几分钟就能生成一款带音乐、计分的小游戏。而此前也有早期测试者表示,GPT-5 的前端设计对于间距、排版和留白等元素的把握有了更好的表现。
Prompt: Create a single-page app in a single HTML file with the following requirements: 提示:在一个 HTML 文件中创建一个单页应用程序,满足以下要求:
Name: Jumping Ball Runner
名称:跳跃球跑者
Goal: Jump over obstacles to survive as long as possible.
目标:跳过障碍物,尽可能长时间生存。
Features: Increasing speed, high score tracking, retry button, and funny sounds for actions and events.
特点:速度递增、高分记录、重试按钮、以及动作和事件相关的趣味音效。
The UI should be colorful, with parallax scrolling backgrounds.
界面应色彩丰富,带有视差滚动背景。
The characters should look cartoonish and be fun to watch.
角色应该看起来像卡通一样,并且很有趣。
The game should be enjoyable for everyone.
游戏应该让每个人都感到愉快。
写作能力方面,用户的日常任务多集中在起草和编辑报告、邮件或撰写备忘录上。OpenAI 指出,相较于严谨的学术论文,这些文本的结构更加模糊,需要将模糊的想法转化为清晰易读的文字。比如下面这个婚礼致辞的例子:

语言自然流畅,使用意象和比喻增加文学性,适当埋梗。以及更重要的,没有把婚姻比作某种量子物理现象。
OpenAI 在第一时间放出了 GPT-5 的多项基准测试结果,最引人注目的是大模型竞技场 LMArena。经过对诸多任务场景的针对性优化,GPT-5 已经在所有细分类目中登顶。
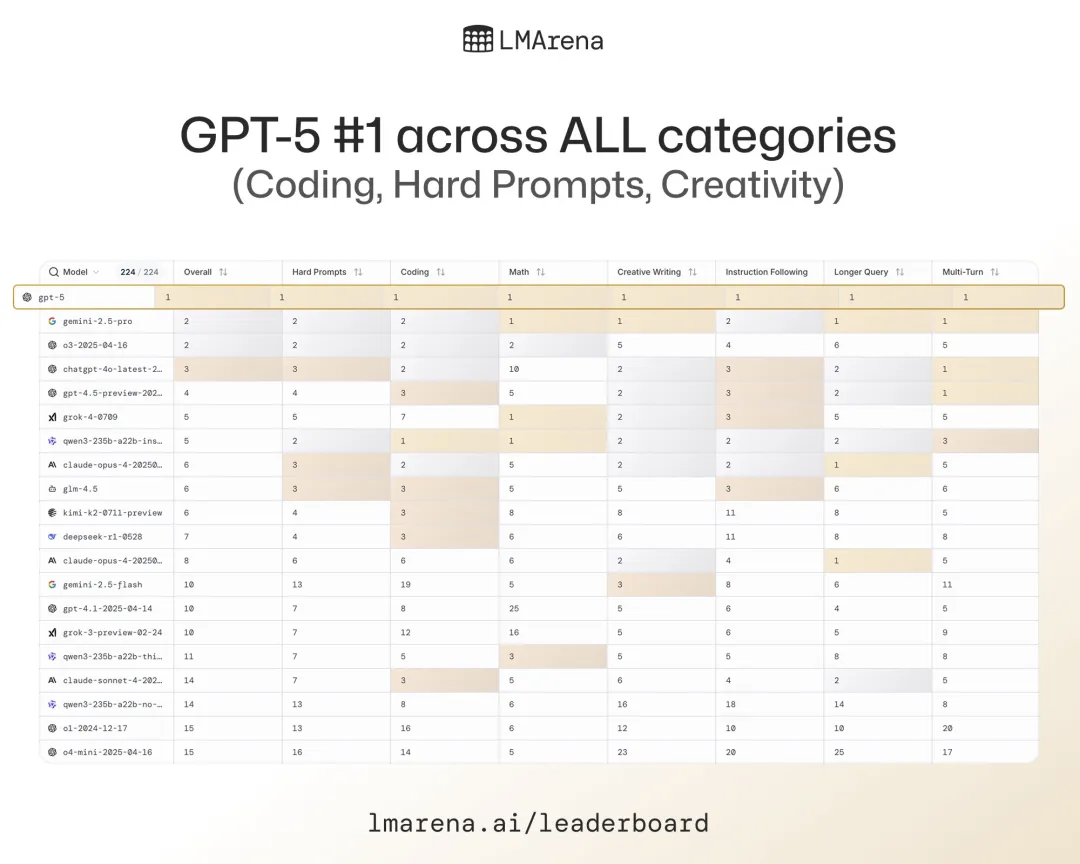
数学能力方面,GPT-5 在 IME 等三项基准测试中排名第一。
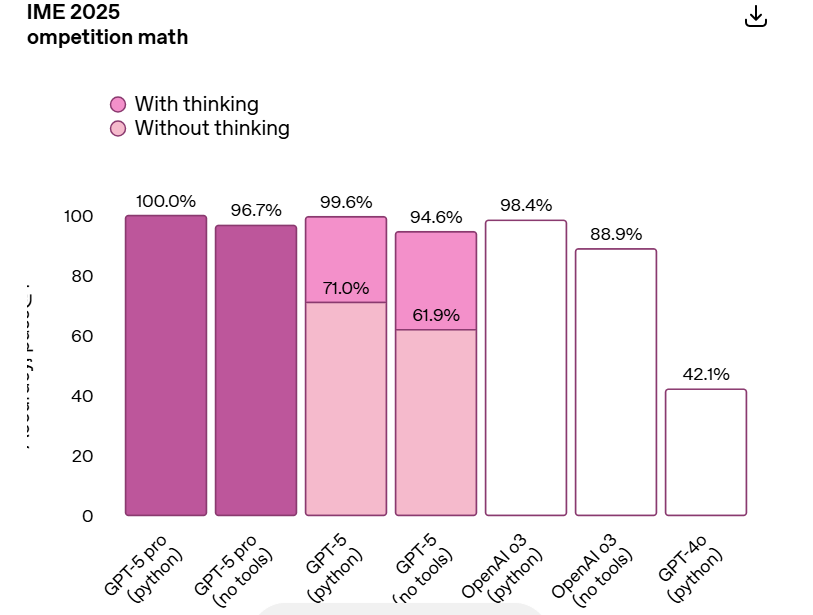
SWE-bench 验证测试达到 74.9%,Aider Polyglot 测试达到 88%,GPT-5 的现实世界编程能力力压此前的 o3 和 4o。
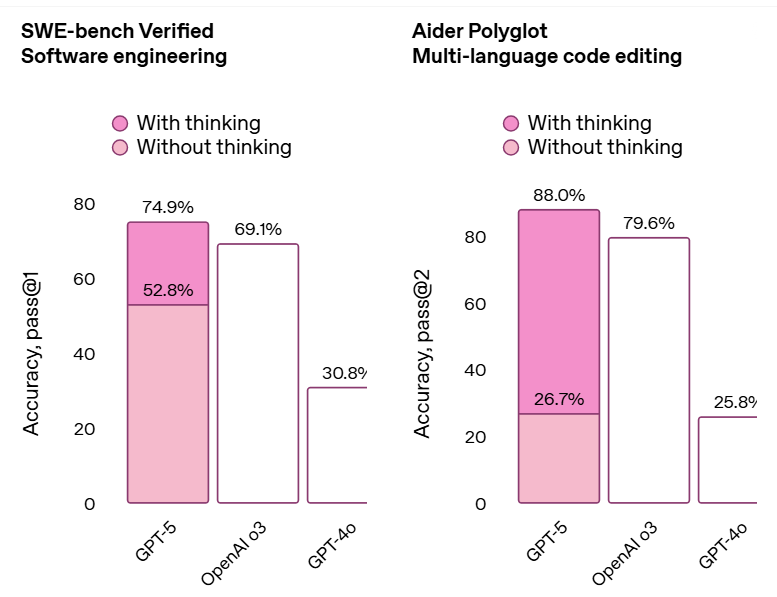
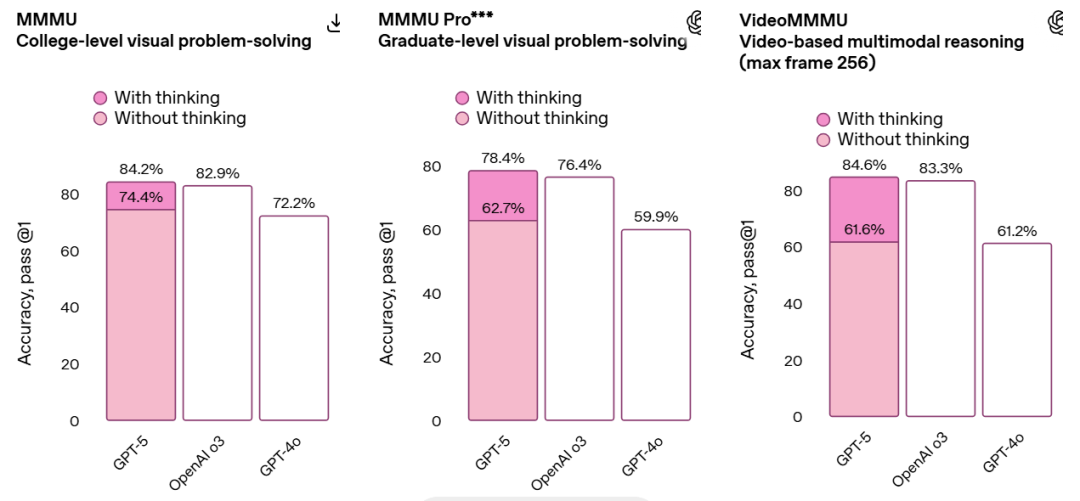
多模态理解能力也在 GPT-5 发力之列,MMMU 测试得分达到 84.2%,意味着 GPT-5 在执行图标解读等任务时可以更准确地处理图像和其它非文本输入。
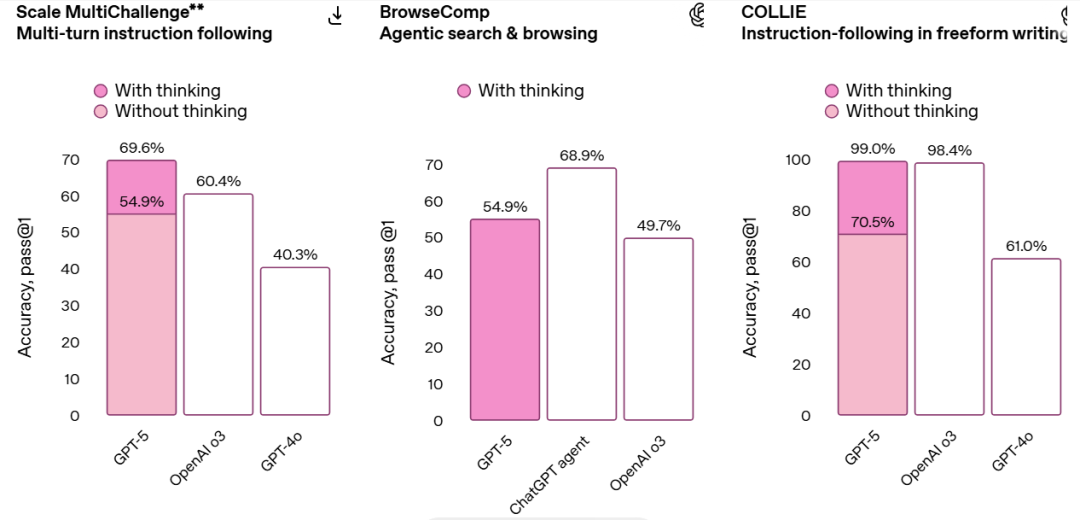
指令遵循和工具调用能力也是模型实用性的重要维度。GPT-5 在 Scale MultiChallenge 等基准测试上也取得了良好表现,这意味着它在处理复杂、变化的任务时将更忠实地遵循用户指令,并利用其可用的工具完成更多端到端的工作。
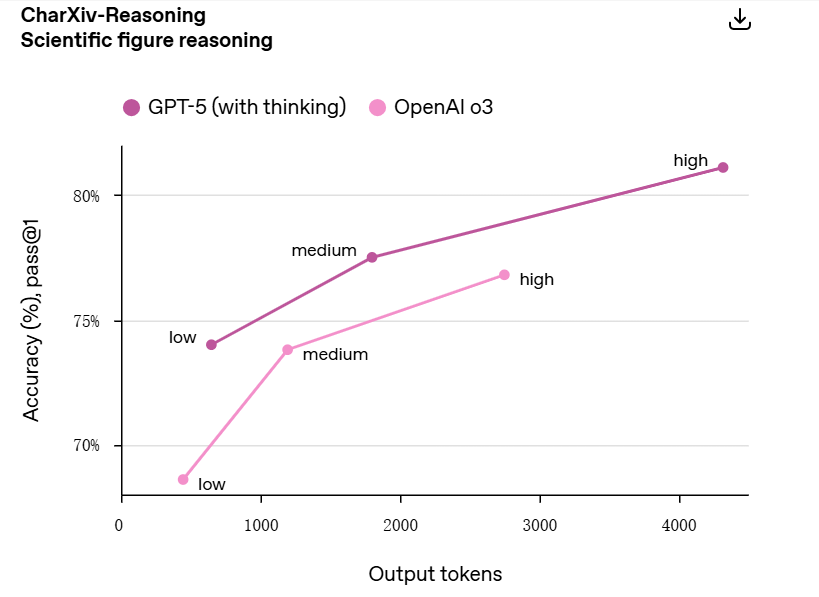
在性能全面提升的同时,GPT-5 的推理成本还降低了。开启思考模式的 GPT-5 在视觉推理、代理编程和研究生水平科学问题解决等能力方面,输出的 token 数量比 OpenAI o3 减少了 50-80%。
值得注意的是,GPT-5 还被赋予了调度子模型的能力,堪称 GPT 全家桶的入口。据 OpenAI 官方介绍,GPT-5 中包含一个实时路由器,可以根据对话类型、复杂度、工具需求和用户的明确意图,快速决定由哪个模型响应用户指令。
OpenAI 此前发布的众多模型在使用场景上各有不同,模型能力及 API 价格的区别确实值得高频用户在选型上多花心思,但也平添了用户的使用成本。GPT-5 将终结这一局面,其实时路由器通过真实信号不断训练,对用户切换模型的行为、对回答的偏好以及测得的正确性进行学习,并且上述指标都会随时间推移不断提升。
在智能水平未见明显提升的情况下,这让 GPT-5 的定位更像是一个跨越不同场景的任务执行专家。
探索智能,不如好用
实用性无疑是此次 GPT-5 更新的一大关键词。相比起展示自身对于智能上限的探索,OpenAI 花了大力气向用户证明,GPT-5 已经是一个可靠的助手:更少的幻觉,更少的犟嘴。
首先是模型幻觉的问题被显著优化。在启用网络搜索的情况下,GPT-5 的回应比 GPT-4o 包含事实性错误的概率降低了约 45%,而在思考过程中,GPT-5 的回应比 OpenAI o3 包含事实性错误的概率降低了约 80%。
这一改进源于 OpenAI 采取了新增的评估方法,来测试模型在处理复杂开放式问题时的可靠性。研究团队在两个公开的事实性基准测试上,测量了 GPT-5 在在思考开放式事实性提示时的幻觉率。在测试结果中,思考模式下 GPT-5 的幻觉相较 OpenAI o3 减少了约 6 倍。
这意味着 GPT-5 在生成持续准确的长格式内容方面取得了明显的进步,同时也会减少模型不懂装懂的可能。
GPT-5 会更诚实地向用户传达其行为和能力,特别是对于那些不可能完成、未明确指定或缺少关键工具的任务,GPT-5 会清晰地表达其局限性,而非通过谎报任务成功完成或“知错不改”而以求在训练中得到奖励。目前,GPT-5 的欺骗率已从o3 的 4.8% 降低到了 2.1%。
GPT-4o 此前曾因为“谄媚”的问题引起热议。这不仅意味着对用户的无条件顺从,Antropic 的研究显示,其实质是 AI 为了对话轮次、用户停留时长等短期指标,而牺牲真实性和准确性的长期价值。
此次 GPT-5 发布,OpenAI 表示已经在训练过程中开发了新的评估方法来衡量奉承程度,并且直接向 GPT-5 展示“过度认同”的例子,教导它不要这样做。OpenAI 还设计了专门的提示词诱使 GPT-5 扮演一个马屁精的角色,但经过优化后,其奉承回复的比例从 14.5% 显著降低至不到 6%。
在可感知的维度,用户会发现 GPT-5 变得不像从前那样热衷于附和、爱用表情符号,并且更加体贴。在交互体验上,研究团队希望 GPT-5 更像用户一个“拥有博士学位水平的乐于助人的朋友”。
“虽然减少奉承有时会降低用户满意度,但我们所做的改进带来了其它可衡量的提升,因此用户能够继续进行高质量、有建设性的对话。”OpenAI 表示。
自今年 2 月 GPT-4.5 发布之后,GPT-5 便被寄予下一代大模型的厚望,然而这中间却出现了诸多始料未及的难题。技术路径方面,高质量数据源耗竭导致 Scaling Law 撞墙,模型智力亟需寻求新的增长增长点。组织架构上,OpenAI 向商业实体的转型几经波折,中间伴随着 IIya Sutskever、Mira Murati 等多位核心人物的出走。近期硅谷的人才大战中 OpenAI 也无法置身局外,扎克伯格拿着“天才名单”高薪挖人之下,OpenAI 又经历了大规模人才流失。
GPT-5 发布前夕,Sam Altman 在自己的社交媒体上发布了一张不知所云的照片,有人猜测是用《星球大战》中的死星暗示 GPT-5 的强大。但想到过去半年的种种,难免有守得云开见月明的感觉。
OpenAI 此次更新,GPT-5 的表现也确实令人眼前一亮。作为一款实用的工具,它在基准测试和实际应用中的表现均无可忽视,编程水平可以胜任更多端到端任务,长文本生成的连贯性和一致性更加自然,对复杂、抽象问题的推理能力有了显著进步。此外 GPT-5 的情境理解能力也得到了显著提升,能够更精确地捕捉文本中微妙的情感变化,这都意味着它更有“人味”,在交互中更贴近了我们对 AGI 的想象。
但 OpenAI 目前并未放出 GPT-5 的参数规模、模型架构等更多信息,后者在任务执行能力上的提升,更像是在现有技术框架内的优化,而非革命性的进步。早在 GPT-5 发布之前,亦有早期测试者对媒体表示,GPT-5 在技术水平上并未实现 GPT-4 之于 GPT-3 的飞跃。
“下一代大模型”靠小步快跑就可以抵达吗?模型架构优化、训练效果提升、新的数据源……模型智力水平新的源动力在哪?GPT-5 发布之后,这些问题更加尖锐。而好消息是,诸多模型团队重新站在了同一条起跑线上。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


1万亿智谱,谁赚走了最多的钱?
2026-06-23

AI支付宝上桌,微信慌了吗?
2026-06-23

在数十亿个Agent运行之前,亚马逊先让Agent学会了管库存和招人
2026-06-24

火山引擎就是要制造一个一个又一个 Seedance 2.0 时刻
2026-06-24

3年5亿MAU,Meta悄悄养出一个社交爆款
2026-06-23

微信推了 AI 助手「小微」,它会成为 AI 大模型的战场吗?
2026-06-24

机器人融资暴增,但没一分钱投给“普通人”
2026-06-25

智谱破万亿,中国大模型终结「平替」叙事
2026-06-25