
Meta重金收购,谁会成为“具身的 Scale AI”?
本文由 甲子光年 撰写/授权提供,转载请注明原出处。
以下文章来源于:甲子光年
作者:王艺
6 月 10 日,《金融时报》曝出重磅消息:Meta 计划斥资约 150 亿美元入股数据基础设施独角兽 Scale AI 49% 股权。这是继微软 6.5 亿美元“整体打包”Inflection 团队、谷歌 27 亿美元绑定 Character AI 之后,全球科技巨头在“训练数据”上开出的迄今最大支票——谁掌握数据,谁就握住了下一轮 AI 竞速的加速键。
大语言模型(LLM)早已用“拼算力 + 堆数据”跑通 Scaling Law:GPT-4、Claude 3.5 等一次训练就吞掉 100 万亿 tokens。自动驾驶依靠真实道路+仿真场景,累计数百亿公里数据。数据饥渴直接催生了独角兽基础设施——典型代表 Scale AI,2024 年营收近 9 亿美元,如今被 Meta 收购,估值飞跃至 280 亿美元。
然而,当机器人真正走进家庭、仓库、工厂,所需的却是物理交互数据:动作轨迹、碰撞反馈、力觉、光照、摩擦……这些数据的获取难度与成本呈指数级上升。迄今最领先的具身 VLA 模型 Pi-0 也只有约 1 万小时真机数据,仍远不及 LLM 量级——LLM 吞掉 100 万亿 tokens,而机器人的高保真交互数据仅相当于其十万分之一。
那么,究竟从哪里才能找到具身智能领域的 Scale AI?
答案可能在于仿真合成数据产业。
真实数据与互联网数据,
为何“远远不够”
目前,机器人或具身智能团队可以获取训练数据的途径大致分为三类:真实数据、互联网数据与仿真合成数据。
真实数据通常通过遥操作(Teleoperation)的方式采集,人类操作者借助示教器或力反馈手柄直接控制机器人执行任务。为了确保安全与精度,一套能够输出关节角、6D 姿态、RGB-D 及触觉信息的高自由度机器人动辄要一两万美元,且传感器和末端执行器需要定期标定与更换;实验室还必须按真实任务场景(例如厨房、仓储或装配线)搭建工位,并持续采购道具与耗材。再加上操作员、数据工程师与安全员的人工时薪,以及高频传感器数据带来的存储与带宽费用,一个配备五台机械臂、两班制运行的中等规模数据采集站,一年就可能烧掉两三百万美元,却只能得到一两千小时的高质量轨迹。换言之,这类数据虽然“贴近部署环境”,但以 LLM 训练的量级来看依然极其稀缺,单样本边际成本最高,且无法达成规模化。
在一座配备了 5 台 7 自由度机械臂、昼夜两班倒的中型“数据工厂”里,全年要烧掉 200 –300 万美元,却只能“榨”出区区 1000–2000 小时的高质量轨迹——而想把数据量放到能支撑 LLM 级 Scaling Law 的程度,至少还要再膨胀 1000 到 10000 倍。
互联网数据来自 YouTube、Instagram、Bilibili 等公开平台,最大的吸引力在于“量大价低”。公开抓取即可获得 PB 级别的视频,覆盖从厨房切菜到仓储拣货等长尾场景,为具身智能模型提供观察多样性的原料。然而,这些内容缺乏动作边界、接触点、力信息等精细标注,画质、视角和光照也高度不稳定,直接提供给模型用于训练会有巨大 Domain Gap,并无法有效作为预训练数据支持具身基础模型训练。版权合规审核也是隐藏成本;一旦涉及商用,获取授权便成刚需。
仿真合成数据借助物理引擎(如 Isaac Sim、MuJoCo 等)在服务器集群中并行生成。其核心优势有三点:第一,可无限扩展,理论上可以在数百张 GPU 上同时跑上千万个场景;第二,天生带齐“全标注”——物体姿态、语义、深度、接触力矩甚至材质属性全部由引擎输出;第三,新增样本几乎零边际成本,真正的成本在于前期制作高保真 SimReady 资产、精调材质与物理参数以及维持算力开销。通过域随机化 (Domain Randomization)、Sensor Noise(传感器噪声)注入等技术来缩小仿真-现实差距(Sim2Real Gap) ,行业领先者(DeepMind、NVIDIA、Figure AI 等)已经把机器人训练在仿真里完成,之后才用少量真实数据微调,实现快速迭代和可控成本。

具身智能三类训练数据对比,制图:「甲子光年」
值得注意的是,仿真合成数据并非是要取代真实数据,而是给真实数据的利用“加杠杆”。在具身智能和自动驾驶领域,行业采取的主流做法更多是“混搭”,也就是将真实数据、互联网数据和仿真合成数据混合在一起进行训练(Co-Training)。
仿真合成数据:放大真实世界的杠杆
仿真合成数据是指通过计算机算法或模拟技术生成的虚拟数据,旨在模仿真实世界的数据分布和特征。它主要应用于人工智能训练领域,用于解决真实数据获取成本高、隐私风险大、数据质量参差不齐等问题。
目前,合成数据在各行各业均得到了较为广泛应用——比如在自然语言处理、银行与金融服务、医疗、自动驾驶等领域,合成数据均有较为成熟的应用模式,Gartner 也预测,到 2030 年 AI 模型使用的绝大部分数据将是合成数据。
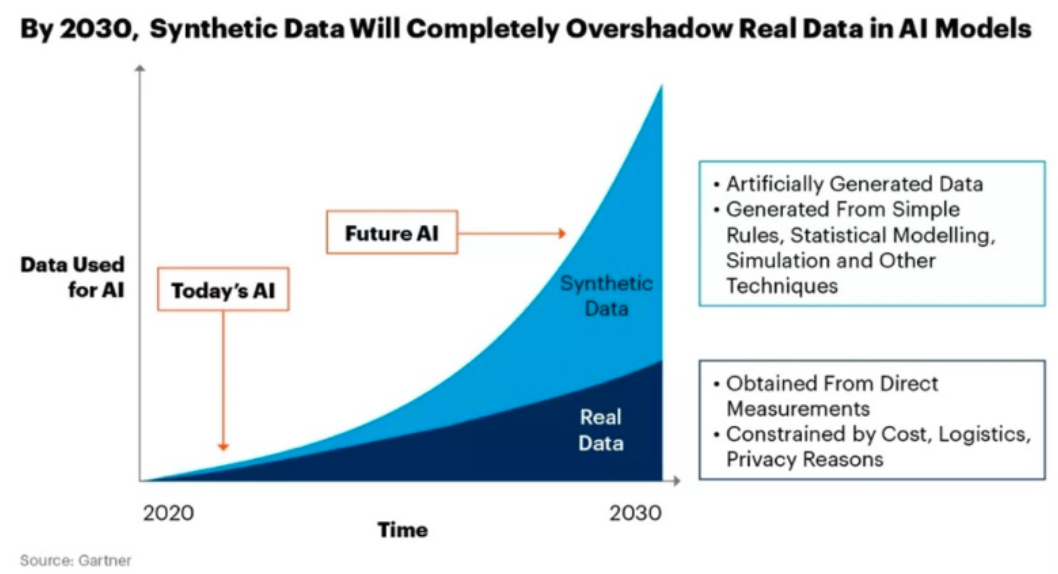
到2030年,人工智能模型中的合成数据将完全超过真实数据,图源:Gartner
2022 年,德克萨斯州立大学奥斯汀分校的朱玉可教授提出了具身智能的“数据金字塔”理论。
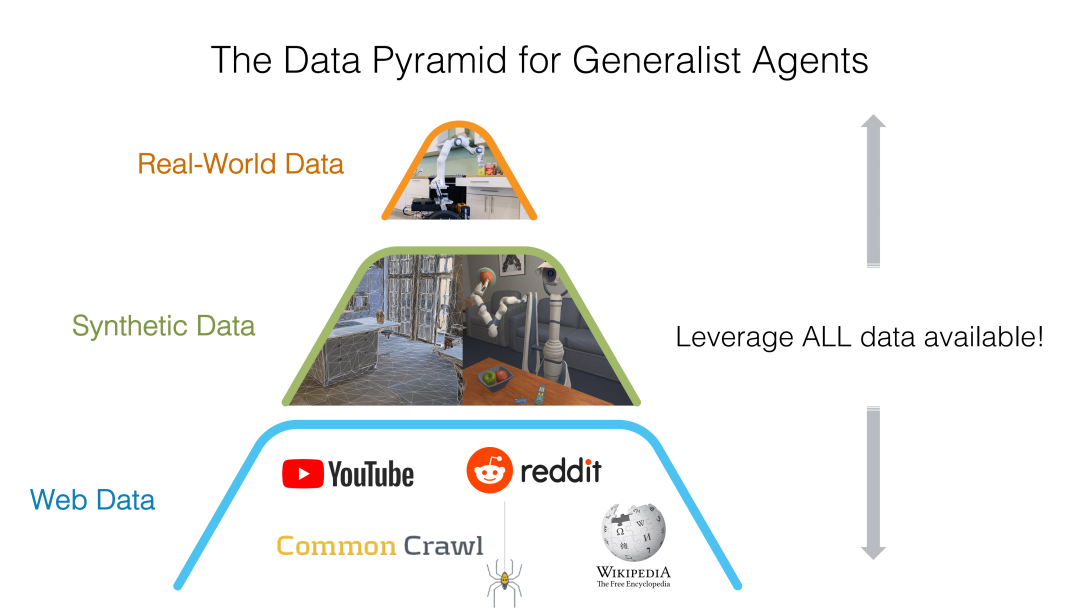
图源:Yuke Zhu《The Data Pyramid for Building Generalist Agents》
该理论认为,在训练通用机器人所需要的数据中,最底层、来源最大的是互联网数据(如 YouTube,维基百科,Common Crawl),它是非结构化的、多模态的、被动收集的,对于训练大型视觉语言模型(VLM)至关重要;中间层是仿真合成数据,从模拟器中生成(如使用 Omniverse 等工具,以及 RoboCasa 等项目用于人工智能生成资产、任务,或 DexMimicGen 用于自动生成轨迹等),这一层比真实世界的数据更具可扩展性,但存在 Sim2Real Gap,这是训练“系统 1”(快速、反应性、感觉运动)策略的关键;最顶层的是来自真实世界的机器人数据,通过远程操作等方法直接从机器人硬件收集(如特斯拉的机器人农场),这是最相关也最小、最昂贵的数据集。
朱玉可教授的“数据金字塔”理论被众多具身智能公司所认可,而这一范式已经被顶尖团队验证。
DeepMind 最新发布的 VLA 模型 Gemini Robotics 采用了双臂机器人平台 ALOHA2 的训练数据集,该数据集包括真实遥操作数据和利用 MuJoCo 模型生成的高保真虚拟数据,保证了 Gemini Robotics 的灵巧性和高泛化性。
英伟达是仿真合成数据的坚定支持者。从仿真合成数据引擎 Omniverse Replicator 到支持生成多模态数据的 Cosmos 系列模型,再到世界首个开源的通用人形机器人模型 Isaac GR00T N1,英伟达构建了覆盖数据生成、模拟训练到部署的全套工具链。2025 年 3 月,英伟达还以超 3.2 亿美元的价格收购了合成数据公司 Gretel,旨在整合其仿真合成数据平台、强化自己的 AI 生态壁垒。
最近开源的通用机器人大模型 Isaac GR00T N1 在训练过程中也采用了“数据金字塔”结构。从其论文中可以看出,英伟达使用了真实数据、仿真数据和人类视频数据和共同训练机器人,数据占比逐层增大。
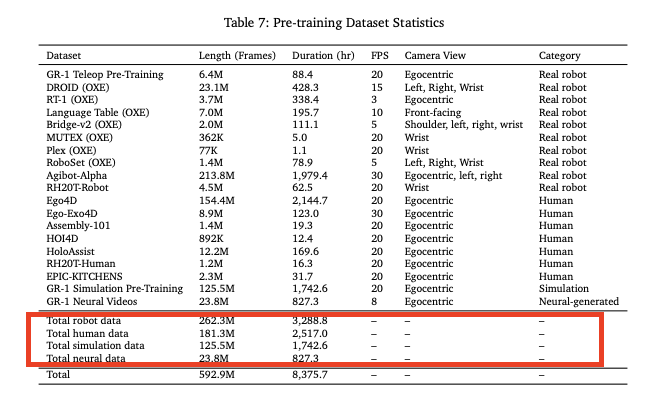
无论 DeepMind、英伟达还是国内的银河通用机器人都已经用仿真合成数据训练具身大模型,并在机器人身上表现出了良好的效果,仿真合成数据在具身智能领域的重要性日益凸显。
仿真合成数据,两个误解
尽管仿真合成数据价值巨大,但仿真合成数据领域一直有一个痛点,就是仿真环境与真实环境之间的差异,也就是业内人士常说的“Sim2Real Gap”。这导致了一些对仿真合成数据效果的误解。
具体有哪些误解?
第一个误解是,“只有真实数据才靠谱”。
长期以来,人们普遍认为“真实数据”是最高质量、最有价值的数据来源。对于具身智能而言,似乎搭建大量的“真实数据采集工厂”,让机器人在真实环境中进行操作并采集数据,是通往通用机器人的康庄大道。真实数据确实是具身智能数据基建的重要组成部分,也是行业正在积极探索的方向。然而,这种观点往往忽略了一个重要的“陷阱”:真实场景之间也存在巨大的“Real2Real Gap”。
这里的“真实场景”往往指的是在受控环境中搭建的“实景工厂”或实验室环境,而并非机器人未来真正需要工作的、千变万化的真实世界。实景工厂的环境布局、物体种类、光照条件等是相对固定的,这与现实世界中动态、开放、充满未知的情况(例如,不同的家庭环境、混乱的仓库、复杂的户外场景)存在固有差异。这构成了第一个层面的“Real2Real Gap”:实景工厂与机器人真实工作环境本身之间的 Gap。
同时,由于实景工厂的建设和维护成本高昂,且数量有限,它无法穷尽真实世界的各种复杂场景和“长尾”案例。机器人若只在这些有限的实景环境中进行训练,其在未见过的真实场景中的泛化能力将受到严重限制,难以应对突发情况或特殊任务。
除了场景本身的限制,当前依赖硬件和人工的真实数据采集方式也存在客观问题。虽然它是具身智能数据积累不可否认的基建,但也面临数据质量和效率的挑战。由于早期机器人硬件技术的局限性,本体在执行任务时难以避免抖动、运动轨迹不平滑等问题,采集到的轨迹数据可能并非最优路径,反而可能引入“噪音”,影响模型训练的准确性和效率。此外,数据采集工厂的运营成本极高,包括硬件维护(机器人和传感器经常需要调试甚至维修)、人员培训(需要大量专业的遥操作人员或维护工程师)等,这些都导致真实数据采集的效率不高,难以快速、低成本地大规模采集。
第二个误解是,“仿真数据没物理感,训练不出好模型”。
仿真合成数据由于具有物理真实性不足、跨模态对齐复杂等特点,因此很多人认为仿真合成数据物理真实性训练出的模型效果不如真实数据。
但是,Sim2Real Gap并非难以跨越。具身智能训练中,除了视觉真实性(确保虚拟场景看起来像真实世界)外,物理真实性(确保虚拟场景中的物体交互、动力学遵循真实世界的物理规律)同样至关重要,甚至对于机器人操作任务而言更为关键。物理属性的重建——如物体的重量、摩擦力等——仍然是行业目前所需要突破的技术点。然而,在很多传统的仿真合成数据生成方案中,物理真实性常常被忽略或简化。而物体如何受力、碰撞与变形是决定机器人能否在现实中完成抓取、搬运、装配的关键。
针对 Sim2Real Gap,光轮独创性的提出了 Real2Sim2Real+ Realism Validation,能够将多视角照片与物性数据结合生成 SimReady 资产,在自研仿真器中大规模生成合成数据,最后把模型回灌至真机做分钟级验证并即时回写误差,形成高速、自收敛的迭代循环。
实测表明,在此框架下训练的 VLA 模型,只需 1∶100 的真机/仿真数据配比,即可把人形机器人从仿真迁到汽车产线——左右手协同装载零件、搬运重物的成功率与真机采集大体量数据的方案不相上下,却将数据成本压到原来的十分之一。
做“有技术门槛的”Scale AI
具身智能的商业化一直是行业从业者普遍关心的问题。在产业发展各个时期都存在“卖铲子”的机会,仿真合成数据就是其中的典型代表。
以大语言模型为例,正如开头提到的,Scale AI 通过“卖数据”给大模型厂商,成为了估值千亿的独角兽公司,而具身智能领域,也有机会通过“卖仿真合成数据”给具身智能厂商的方法,创造属于自己的 Scale AI。
作为具身智能领域的“隐形数据供应商”,我们看到光轮智能的定位和模式,也非常像具身智能领域的 Scale AI。根据公开资料,光轮的第一个具身客户为英伟达,第二个为硅谷估值最高的人形机器人公司 Figure AI,接连服务的 DeepMind、智元机器人、银河通用机器人等,都是具身智能领域的巨头和领跑者。

光轮智能披露的已合作客户,来源:光轮智能官网
但光轮智能并未完全照搬 Scale AI 的模式。与 Scale AI 业务重心偏数据服务不同,光轮智能在算法研发投入方面明显更高,创造的不仅仅只是“数据”。
以光轮智能与英伟达 Isaac GR00T N1 人形机器人的合作为例,光轮智能不仅具有数据能力,还拥有 VLA 算法能力,在 N1 发布后仅一个月的时间,就帮助其完成了汽车工厂任务的落地。
英伟达公布的合作案例和光轮智能的技术博客还原了这一部署过程。首先,光轮智能利用多样化的仿真环境,模拟了汽车工厂中的复杂任务场景。他们用 NVIDIA Omniverse 和光轮的专有 SimReady 资产管道搭建了一个和真实汽车工厂 1:1 的“Digital Twin(数字孪生)”环境、及相应的“Digital Cousin(数字表亲)”,接着由遥操员戴上 VR 眼镜,远程操控虚拟机器人完成工厂任务,比如抓零件、搬重物等。这些操作被记录下来,变成训练数据,并通过多种泛化生成快速训练数据,避免了在真实工厂里反复试错的成本。最终,光轮智能使用约为 100:1 的仿真数据和真实数据配比训练机器人,提升机器人适应工厂环境和零部件形状变化的能力,且同时少量真实数据则确保机器人的动作符合物理规律。
从部署 N1 的案例可以看出,光轮智能的能力并非仅局限于仿真数据生产,而是以仿真为中心,加速 VLA+RL 算法训练的体系化能力。这种能力使得光轮智能可以快速将真实场景数字孪生到仿真环境中,通过仿真遥操作快速采集训练数据,并基于 VLA 的 FineTuning 与 RL 显著加速模型 Sim2Real 落地部署,实现了工业级应用。
因此,光轮智能想做的并不是一家单纯的数据公司,而是“有技术门槛的”Scale AI。正如光轮智能对英伟达 Isaac GR00T N1 的赋能,这种兼具仿真能力与算法 Sim2Real 能力的数据公司,或许才是具身行业 Scale AI 发展的终极方向。
(封面图来源:光轮智能)

扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


腾讯AI秘密“换船”:元宝失宠,WorkBuddy接棒
2026-06-12

腾讯高管:今年腾讯大部分代码都由AI生成
2026-06-08

Claude深夜炸场!放出史上最强“危险级”模型Fable 5,价格太逆天
2026-06-10

vivo、荣耀接连入场,戳破了具身智能的AI叙事
2026-06-10

苹果把Siri交给了Gemini
2026-06-10

豆包必须要收费了
2026-06-08
视频模型巨大的「隐形成本」,没人告诉你
2026-06-08

微信“抢婚”豆包?
2026-06-11







