
讲真,马斯克的Grok-3,“碰瓷”不了DeepSeek
本文由 DoNews 撰写/授权提供,转载请注明原出处。
以下文章来源于:DoNews
作者:雁秋
编辑:李信马
题图:豆包AI
前不久,一场高规格民企座谈会让坊间议论纷纷。这是中央时隔 6 年 3 个月再度专门召开民营企业座谈会,会上,中国互联网和科技产业的精英齐聚一堂,释放出新质生产力、科技创新产业向好的趋势。
年轻的梁文峰也在其中,他与任正非、曾毓群等老一辈企业家同座,而他的 DeepSeek 正成为在场各家业务的连接桥梁。
没过多久,马斯克旗下 xAI 公司突然发布新一代大语言模型 Grok-3,号称是“地球上最聪明的人工智能”,计算能力是去年 8 月发布的 Grok 2 的 10 倍,推理能力超越包括 ChatGPT 和 DeepSeek 在内的其他领先 AI 模型。
一场横跨太平洋的“AI对战”瞬间点燃科技圈,在外界看来,Grok 3 令 AI 行业竞争更加激烈。谁是在实验室里“秀肌肉”,谁又能将技术变成实实在在的生产力,是未来这场风暴的中心。
训练:一个赌“壕气”,
一个用“巧思”
Grok-3 是马斯克与团队 xAI 为挑战 OpenAI、ChatGPT 而精心打造的产品,被称为“地球上最聪明的人工智能”。
在官方的直播演示中,Grok-3 和 Grok-3 mini 在数学、科学和编程基准测试上,超越了包括 GPT-4o、DeepSeek-V3 和 Gemini-2 Pro 等主流模型。
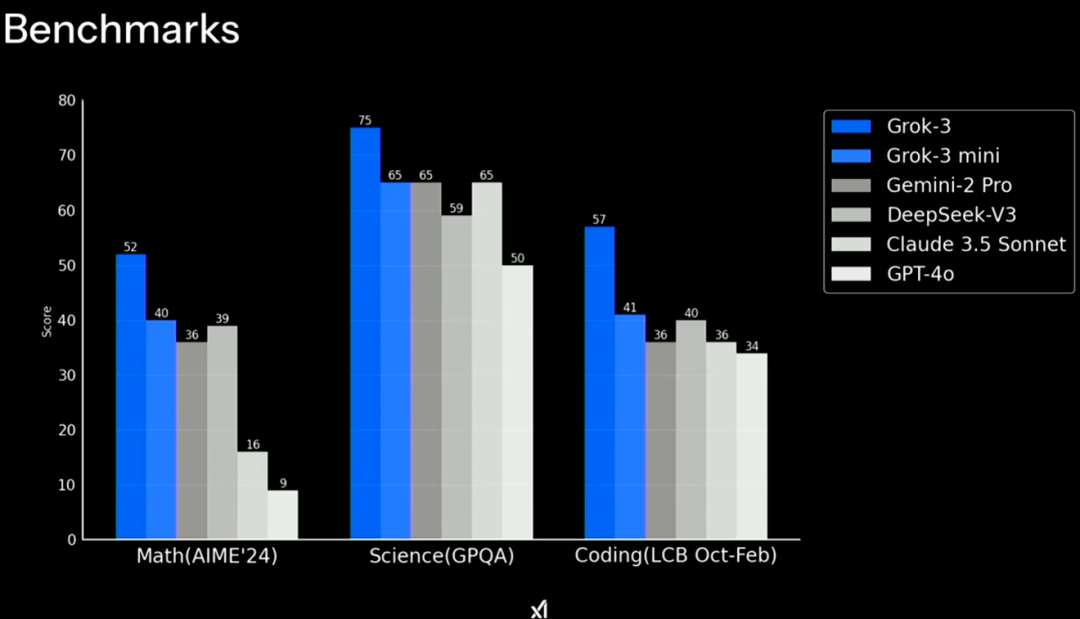
同时,具备推理能力的 Grok-3 Reasoning Beta 和 Grok-3 mini Reasoning 则超越了 DeepSeek-R1 和 OpenAI 的 o3 mini 等。
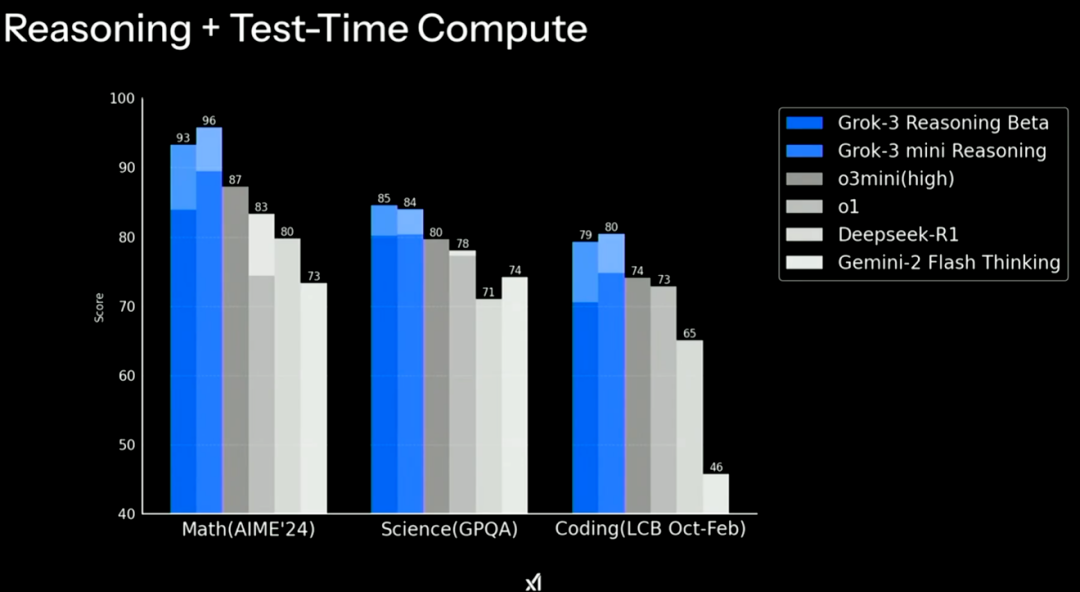
看得出,DeepSeek 已经与头部大模型比肩。
自打这个国产大模型爆火后,包括硅谷在内的许多 AI 公司都开始重新评估用堆算力和参数来推进所谓的“扩展法则”,是否仍然适用。因为 DeepSeek 颠覆了以往发展 AI 就是要不断的堆算力、堆 GPU 的烧钱路子,而是采用了一条分布式算力+混合云优化的路线:通过动态调度公有云、私有服务器甚至边缘计算资源,结合自研的模型压缩技术(如稀疏化训练),在千亿参数规模下实现了训练成本降低 40% 以上。
然而目前看来,马斯克并不这么认为。事实上,xAI 一直是追求“大力出奇迹”的代表,相关负责人表示:
“如果你看看所有性能的来源,当你有一个非常强大的工程团队和最优秀的 AI 人才时,唯一需要的就是一个强大的集群,才能产生巨大的智能。”
某种意义上,Grok3 也是大力出奇迹的结果,马斯克为其攒下了“壕”无人性的算力家底。据了解,xAI 团队在 122 天内让第一批 10 万块 GPU 投入使用,是“目前最大的完全连接的H100集群”。之后又用了 92 天的时间,将数据中心的容量继续翻倍,并基于这些成果构建出了 Grok-3。
而被拿来进行对比的 DeepSeek-V3 模型,则是在配备了 2048 个英伟达 H800 GPU 的集群上进行训练的。H800 是英伟达特供中国市场的 AI 芯片,在性能上不及先进的 H200、H100 等。
虽然如此,拥有更高集群的 Grok-3 在演示时也未呈现出“地球最聪明”的状态。直播中Grok-3一度“思考卡壳”,在任务时因为显示“Thinking Hard”;后很长一段时间没有反应,等待几秒后演示人员关闭了页面开启下一话题。
有网友亲自下场向 Grok 3 提问,在面对下图中“比萨斜塔上两个球哪个先落下”这样常识性的问题时,Grok 3 也仍然无法应对,因此被戏称为“天才不愿意回答简单问题”。

图源:x(谷歌翻译)
尽管如此,马斯克称未来他们将会进一步加大数据中心的建设力度,xAI 的下一个计算集群会成为世界上最强大的集群,能耗达到 1.2GW,相当于数十万户家庭 1 年的用电量。
网友犀利的评价:“自 DeepSeek-R1 之后,我们只应考虑效率更高的进步,而不仅仅那些规模更大、且比竞争对手耗能更多的进步。”
开源:一个“挤牙膏”,
一个全开放
一般情况下,企业依靠高算力而堆出来的高性能模型,会基于成本考虑选择闭源或延迟开源。
关于 Grok-3,马斯克并未当场宣布开源,而是表示:“当下一个版本完全发布时,将开源 Grok 的上一个版本,也就是当 Grok-3 成熟稳定时,我们将开源 Grok-2。”
2 月 20 日,马斯克转发 xAI 的推文,宣布短期内 Grok 3.0 向所有人免费开放。不出意外,Grok-3 会延续“基础版开源+高级功能付费”的策略。这样既能吸引开发者贡献算力(社区训练反哺主模型),又能用开源生态倒逼竞争对手。
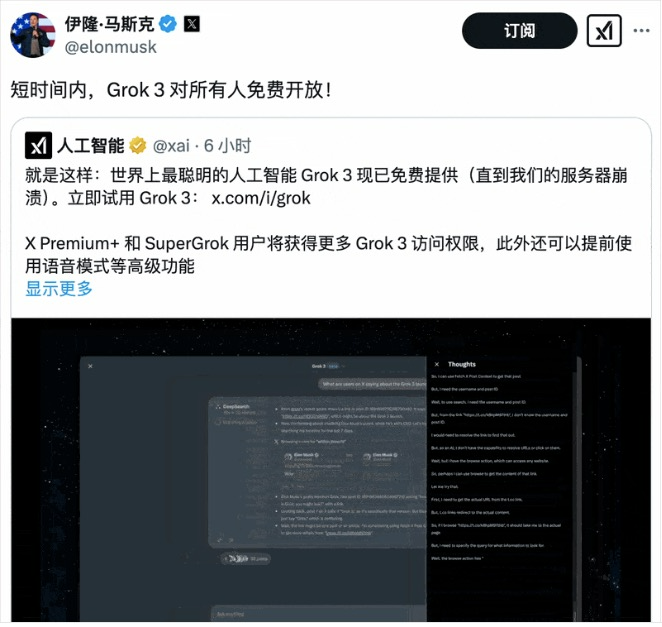
图源:x
而在刚刚过去的两周,以 DeepSeek 为中心的朋友圈迅速扩容。国外,有包括微软、英伟达、亚马逊等世界级云计算巨头;国内,三大基础运营商、超过 15 家芯片厂商,还有手机、车企、云服务、金融在内的 200 多家企业,多地政务服务系统,甚至两款“国民级应用”腾讯微信、百度搜索也先后宣布接入。
大模型到底应该开源,还是应该闭源?这个话题讨论已久,企业基本上走出三条路子:
只做开源,没有盈利模式,只有大公司烧得起,Meta 是少数走这条路的;
开源闭源并行,比较灵活,既有收入又能获取用户,包括微软、谷歌、阿里云、腾讯云等,均践行这条路;
只做闭源,相当于走了一条简单直接逻辑清晰的路,亚马逊、华为盘古、还有以前的文心一言(百度)、GPT-4(OpenAI)均如此。亚马逊、谷歌云在过去一年的营收增速都有所提升,这被认为是大模型拉动的结果。
在发展过程中,企业的观念也在发生变化。长期以来,OpenAI 因为「不open」(不开放)而备受争议。OpenAI 首席执行官萨姆.奥特曼曾为下一个模型的开源项目征集意见,“做一个相当小但仍需要在 GPU 上运行的 o3-mini 级模型,还是做一个我们能做得最好的适合手机运行的模型?”
就在看似闭源 OpenAI 遥遥领先之时,DeepSeek 开源大模型的出圈又带来了巨大的不确定性。萨姆.奥特曼称 OpenAI 在开源 AI 软件方面“一直站在历史的错误一边”,他还透露,虽然并非所有员工都同意其观点,但 OpenAI 内部正讨论公开 AI 模型的权重等事宜。
开源或闭源,这其中掺杂了商业利益、技术观点等多重因素。Gartner 高级分析师 Mike Fang 在接受 DoNews 采访时则表示,在人工智能大模型领域,开源和闭源的路线持续并存。
“如果闭源模型的性能不及开源模型,则其商业价值将受到质疑。然而,对于高性能的闭源模型,其商业路径仍然具备优势。未来 AI 大模型可能进入低算力、低成本时期,但高端模型仍会保持一定溢价。”
至于疯狂开源的 DeepSeek,其发展模式是否会调整?未来盈利前景又将如何?在 Mike Fang 看来,这家公司短期不以盈利为目的,能够从研究角度鼓励工程师更高效运营,而没有特别多的财务变化或者业务变化的压力。未来如何能够保持初心,让发展模式或者技术创新能够持续下去,才是主要考虑的方向。
换个角度想,对于日活用户数量达数千万的 DeepSeek 来说,找到盈利模式并不困难,开源的价值要比想象中大得多。从某种层面来讲,DeepSeek 的影响力是以往的技术突破无法比拟的——我们不应该只考虑它作为单个公司的科技价值、商业价值,而应该思考它对推动新质生产力发展的巨大价值。
面对 DeepSeek 的普及,
企业要怎么做?
DeepSeek 所代表的资源消耗更小、算法效率更高、推理更精确的技术路径,正在进一步助推 AI 应用成本下降。
从近期企业动作来看,不仅包括大语言模型领域积累较弱的手机、家电、PC、汽车厂商,就连已经开发出 AI 大模型的腾讯、360、百度等大厂,也在为自家的 AI 工具注入新动力。
但这会产生新的问题,所有人都接入了,等于所有人都没接。家家户户都有 DeepSeek 这把“金钥匙”,打开市场的、或者说驱动业务增长的核心差异化能力体现在哪里?在新的环境下,企业又该如何竞争?
关于这一点,Gartner 的 Mike Fang 告诉我们,企业若仅满足于“简单接入”,就无法在竞争中脱颖而出。关键是要找到适合自身业务场景的AI解决方案,深度挖掘大模型的潜力,将其与行业特点、客户需求和特定场景紧密结合,并注重工程化落地与治理,从而实现高效且负责任的技术应用。
也就是说,大模型赋予产品强大的技术力,但如何将这一能力转化为无可替代的产品体验,让用户发自内心地接受使用,才是竞争的最终目标。
Mike Fang 举例表示,当下,从车企到券商纷纷宣布接入 DeepSeek,但也仅仅是接入,距离真实大规模应用落地还需要更长时间。“这其中涉及到模型切换,面对新的业务场景,企业要通过不断的流程测试以及在真实业务当中检验。”
但这里要注意数据问题,对于 AI 来说,有三大要素需要分析:大模型、算力和数据。在大模型迎来颠覆式创新之后,对算力的需求开始降低,下一个重要的瓶颈是数据。
通过 Gartner 研究表示,海外 AI 公司应用数据的能力较高,已经支持企业大模型的落地。反观国内,数据方面的数值一直徘徊在较低位,只有少部分企业能够实际把生成式 AI 应用从实验到最后的生产落地。
这就要考验企业是否具备构建一个从技术到市场的良性循环,不仅仅是关于产品的迭代与优化,更是如何在短期内通过市场数据和产品调整,不断提升大模型的能力。未来,谁能够获取专有数据,并能实现实时更新,将是竞争的关键所在。
单个企业是如此,而对于整个中国的 AI 产业来讲,DeepSeek 还可以带动很多开发、推理,甚至是芯片方面的额外的机会,这将进一步加速企业“出海”。此外,AI 接下来的治理也会变得更为重要,“如果把 DeepSeek 的能力比作高速行驶的一辆车,企业就需要自建或者管控出一个原生的刹车系统,这样才会使得大模型更健壮,“车”能够开得更快。Mike Fang 表示。
可以说,DeepSeek 搅动起的,早已不是 AI 大模型竞技规则变化的风云,而是影响多个产业迭代的深层变革浪潮。我们都站在了时代潮头,更需要以开放的心态拥抱变化。


扫一扫 在手机阅读、分享本文

扫码关注公众号
获取更多技术资讯
{{ val.activity_name }}

免费领取技术福利
发送名片申请入群


腾讯AI秘密“换船”:元宝失宠,WorkBuddy接棒
2026-06-12

腾讯高管:今年腾讯大部分代码都由AI生成
2026-06-08

Claude深夜炸场!放出史上最强“危险级”模型Fable 5,价格太逆天
2026-06-10

vivo、荣耀接连入场,戳破了具身智能的AI叙事
2026-06-10

苹果把Siri交给了Gemini
2026-06-10

豆包必须要收费了
2026-06-08
视频模型巨大的「隐形成本」,没人告诉你
2026-06-08

微信“抢婚”豆包?
2026-06-11







